Python实现鸢尾花数据集分类问题——基于skearn的NaiveBayes
Python实现鸢尾花数据集分类问题——基于skearn的NaiveBayes
代码如下:
# !/usr/bin/env python
# encoding: utf-8
__author__ = 'Xiaolin Shen'
from sklearn.naive_bayes import GaussianNB,BernoulliNB
import numpy as np
import pandas as pd
from sklearn import preprocessing
from sklearn import model_selection
import matplotlib.pyplot as plt
import matplotlib as mpl
from matplotlib import colors
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline # 当使用numpy中的loadtxt函数导入该数据集时,假设数据类型dtype为浮点型,但是很明显数据集的第五列的数据类型是字符串并不是浮点型。
# 因此需要额外做一个工作,即通过loadtxt()函数中的converters参数将第五列通过转换函数映射成浮点类型的数据。
# 首先,我们要写出一个转换函数:
# 定义一个函数,将不同类别标签与数字相对应
def iris_type(s):
class_label={b'Iris-setosa':0,b'Iris-versicolor':1,b'Iris-virginica':2}
return class_label[s] #(1)使用numpy中的loadtxt读入数据文件
filepath='IRIS_dataset.txt' # 数据文件路径
data=np.loadtxt(filepath,dtype=float,delimiter=',',converters={4:iris_type})
#以上4个参数中分别表示:
#filepath :文件路径。eg:C:/Dataset/iris.txt。
#dtype=float :数据类型。eg:float、str等。
#delimiter=',' :数据以什么分割符号分割。eg:‘,’。
#converters={4:iris_type} :对某一列数据(第四列)进行某种类型的转换,将数据列与转换函数进行映射的字典。eg:{1:fun},含义是将第2列对应转换函数进行转换。
# converters={4: iris_type}中“4”指的是第5列。 # print(data)
#读入结果示例为:
# [[ 5.1 3.5 1.4 0.2 0. ]
# [ 4.9 3. 1.4 0.2 0. ]
# [ 4.7 3.2 1.3 0.2 0. ]
# [ 4.6 3.1 1.5 0.2 0. ]
# [ 5. 3.6 1.4 0.2 0. ]] #(2)将原始数据集划分成训练集和测试集
X ,y=np.split(data,(4,),axis=1) #np.split 按照列(axis=1)进行分割,从第四列开始往后的作为y 数据,之前的作为X 数据。函数 split(数据,分割位置,轴=1(水平分割) or 0(垂直分割))。
x=X[:,0:2] #在 X中取前两列作为特征(为了后期的可视化画图更加直观,故只取前两列特征值向量进行训练)
x_train,x_test,y_train,y_test=model_selection.train_test_split(x,y,random_state=1,test_size=0.3)
# 用train_test_split将数据随机分为训练集和测试集,测试集占总数据的30%(test_size=0.3),random_state是随机数种子
# 参数解释:
# x:train_data:所要划分的样本特征集。
# y:train_target:所要划分的样本结果。
# test_size:样本占比,如果是整数的话就是样本的数量。
# random_state:是随机数的种子。
# (随机数种子:其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但填0或不填,每次都会不一样。
# 随机数的产生取决于种子,随机数和种子之间的关系遵从以下两个规则:种子不同,产生不同的随机数;种子相同,即使实例不同也产生相同的随机数。) #(3)搭建模型,训练GaussianNB分类器
classifier=GaussianNB()
# classifier=BernoulliNB()
#开始训练
classifier.fit(x_train,y_train.ravel()) def show_accuracy(y_hat,y_test,parameter):
pass #(4)计算GaussianNB分类器的准确率
print("GaussianNB-输出训练集的准确率为:",classifier.score(x_train,y_train))
y_hat=classifier.predict(x_train)
show_accuracy(y_hat,y_train,'训练集')
print("GaussianNB-输出测试集的准确率为:",classifier.score(x_test,y_test))
y_hat=classifier.predict(x_test)
show_accuracy(y_hat,y_test,'测试集')
# GaussianNB-输出训练集的准确率为: 0.809523809524
# GaussianNB-输出测试集的准确率为: 0.755555555556 # # 查看决策函数,可以通过decision_function()实现。decision_function中每一列的值代表距离各类别的距离。
# print('decision_function:\n', classifier.decision_function(x_train))
# print('\npredict:\n', classifier.predict(x_train)) # (5)绘制图像
# 1.确定坐标轴范围,x,y轴分别表示两个特征
x1_min, x1_max = x[:, 0].min(), x[:, 0].max() # 第0列的范围
x2_min, x2_max = x[:, 1].min(), x[:, 1].max() # 第1列的范围
x1, x2 = np.mgrid[x1_min:x1_max:200j, x2_min:x2_max:200j] # 生成网格采样点
grid_test = np.stack((x1.flat, x2.flat), axis=1) # 测试点
# print 'grid_test = \n', grid_test
grid_hat = classifier.predict(grid_test) # 预测分类值
grid_hat = grid_hat.reshape(x1.shape) # 使之与输入的形状相同 # 2.指定默认字体
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
# 3.绘制
cm_light = mpl.colors.ListedColormap(['#A0FFA0', '#FFA0A0', '#A0A0FF'])
cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b']) alpha=0.5 plt.pcolormesh(x1, x2, grid_hat, cmap=cm_light) # 预测值的显示
# plt.scatter(x[:, 0], x[:, 1], c=y, edgecolors='k', s=50, cmap=cm_dark) # 样本
plt.plot(x[:, 0], x[:, 1], 'o', alpha=alpha, color='blue', markeredgecolor='k')
plt.scatter(x_test[:, 0], x_test[:, 1], s=120, facecolors='none', zorder=10) # 圈中测试集样本
plt.xlabel(u'花萼长度', fontsize=13)
plt.ylabel(u'花萼宽度', fontsize=13)
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.title(u'鸢尾花GaussianNB分类结果', fontsize=15)
plt.grid() #显示网格
plt.show()
程序运行结果:

数据可视化展示:
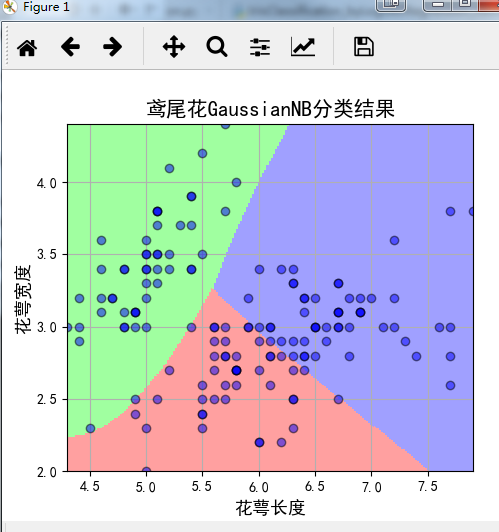
Python实现鸢尾花数据集分类问题——基于skearn的NaiveBayes的更多相关文章
- Python实现鸢尾花数据集分类问题——基于skearn的LogisticRegression
Python实现鸢尾花数据集分类问题——基于skearn的LogisticRegression 一. 逻辑回归 逻辑回归(Logistic Regression)是用于处理因变量为分类变量的回归问题, ...
- Python实现鸢尾花数据集分类问题——基于skearn的SVM
Python实现鸢尾花数据集分类问题——基于skearn的SVM 代码如下: # !/usr/bin/env python # encoding: utf-8 __author__ = 'Xiaoli ...
- Python实现鸢尾花数据集分类问题——使用LogisticRegression分类器
. 逻辑回归 逻辑回归(Logistic Regression)是用于处理因变量为分类变量的回归问题,常见的是二分类或二项分布问题,也可以处理多分类问题,它实际上是属于一种分类方法. 概率p与因变量往 ...
- 基于SVM的鸢尾花数据集分类实现[使用Matlab]
iris数据集的中文名是安德森鸢尾花卉数据集,英文全称是Anderson’s Iris data set.iris包含150个样本,对应数据集的每行数据.每行数据包含每个样本的四个特征和样本的类别信息 ...
- ML学习笔记之XGBoost实现对鸢尾花数据集分类预测
import xgboost as xgb import numpy as np import pandas as pd from sklearn.model_selection import tra ...
- BP神经网络算法程序实现鸢尾花(iris)数据集分类
作者有话说 最近学习了一下BP神经网络,写篇随笔记录一下得到的一些结果和代码,该随笔会比较简略,对一些简单的细节不加以说明. 目录 BP算法简要推导 应用实例 PYTHON代码 BP算法简要推导 该部 ...
- 做一个logitic分类之鸢尾花数据集的分类
做一个logitic分类之鸢尾花数据集的分类 Iris 鸢尾花数据集是一个经典数据集,在统计学习和机器学习领域都经常被用作示例.数据集内包含 3 类共 150 条记录,每类各 50 个数据,每条记录都 ...
- 实验一 使用sklearn的决策树实现iris鸢尾花数据集的分类
使用sklearn的决策树实现iris鸢尾花数据集的分类 要求: 建立分类模型,至少包含4个剪枝参数:max_depth.min_samples_leaf .min_samples_split.max ...
- python 鸢尾花数据集报表展示
import seaborn as snsimport pandas as pdimport matplotlib.pyplot as pltsns.set_style('white',{'font. ...
随机推荐
- Centos7 搭建lnmp环境 (centos7+nginx+MySQL5.7.9+PHP7)
阿里云一台服务器出现问题! 我估计是一键安装包环境的原因,所以打算重新搭建下环境! 首先,当然是先做好快照!安全第一! 对系统盘做更换系统操作,装上纯净版的centos. 装好后,进入系统 一.挂载数 ...
- javascript学习笔记——怎样改动<a href="#">url name</a>
0.前言 使用了一段时间javascript,再花了点时间学习了jquery.可是总是感觉自己非常"迷糊",比如<a href="#">ur ...
- mysql主从备份及原理分析
一.mysql主从备份(复制)的基本原理mysql支持单向.异步复制,复制过程中一个服务器充当主服务器,而一个或多个其它服务器充当从服务器.mysql复制基于主服务器在二进制日志中跟踪所有对数据库的更 ...
- 在浏览器中直接调用webservice的正确写法
此文章针对webwork+spring+hibernate的工程,对于其他框架应该一样适用,首先在wsdd文件中找到所需webservice的名称,例如以下写法: <service name=& ...
- 【应用】R--判断类别型属性之间是否有相关性(相互之间是否独立)
检验某学区所有在售房源中,小区与楼栋类别(低层:多层;小高层:高层)是否相关 导入数据: > house<- read.table("house_data.txt", ...
- [Algorithm] Reservoir Sampling
Given a stream of elements too large to store in memory, pick a random element from the stream with ...
- FastDFS_v4.06+nginx-1.4.2配置详解
径不带group名(storage只有一个group的情况),如/M00/00/00/xxx: location /M00 { ngx_fastdfs_module; ...
- springboot结合jwt实现基于restful接口的身份认证
基于restful接口的身份认证,可以采用jwt的方式实现,想了解jwt,可以查询相关资料,这里不做介绍~ 下面直接看如何实现 1.首先添加jwt的jar包,pom.xml中添加依赖包: <de ...
- ES6 箭头函数(arrow function)
例行声明:接下来的文字内容全部来自 Understanding ECMAScript 6,作者是Nicholas C.Zakas,也就是大名鼎鼎的Professional JavaScript for ...
- Linux netstat命令介绍
关注Linux的系统状态,主要从两个角度出发,一个角度是系统正在运行什么服务(ps命令):另外一个就是有什么连接或服务可用(netstat命令).netstat还可以显示ps无法显示的.从inetd或 ...