【Python3 爬虫】14_爬取淘宝上的手机图片
现在我们想要使用爬虫爬取淘宝上的手机图片,那么该如何爬取呢?该做些什么准备工作呢?
首先,我们需要分析网页,先看看网页有哪些规律
打开淘宝网站http://www.taobao.com/
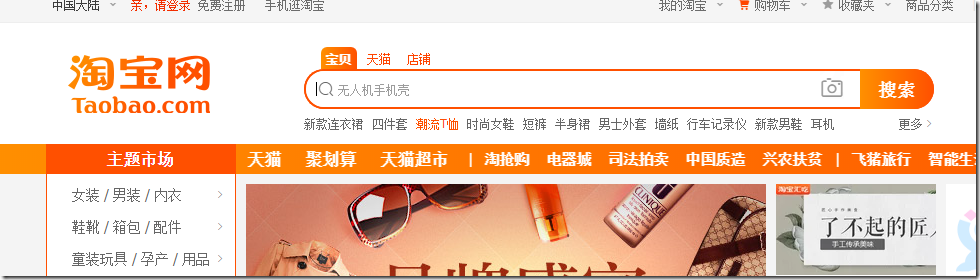
我们可以看到左侧是主题市场,将鼠标移动到【女装/男装/内衣】这一栏目,我们可以看到更细类的展示
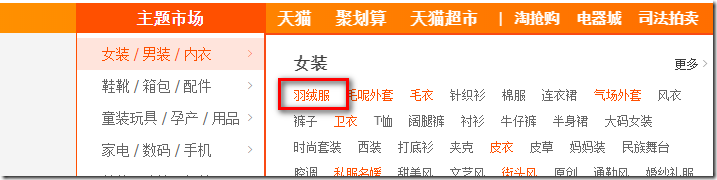
假如我们现在需要爬取【羽绒服】,那么我们进入到【羽绒服】衣服这个界面
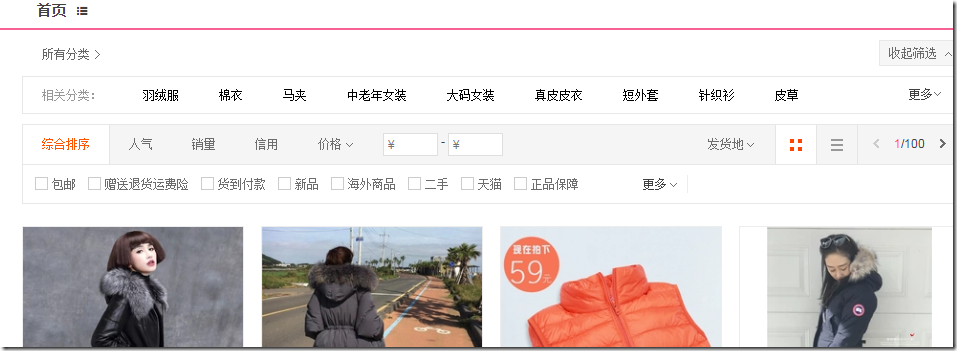
此时查看浏览器地址,我们可以看到

网址复制到word或者其他地方会发生url转码
我们可以选中【羽绒服模块的第1,2,3页进行网址对比】,对比结果如下:
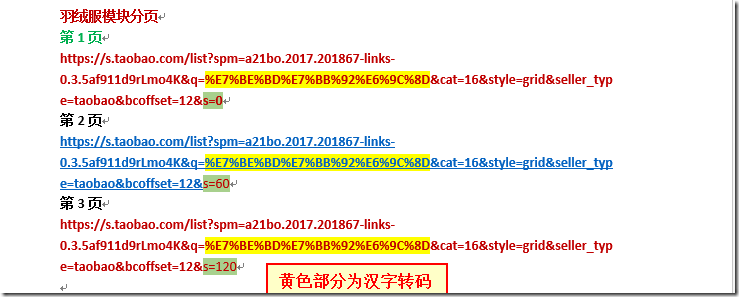
从上图我们可以看出:三页的s值都是相差60
然后我们再看下图片地址:
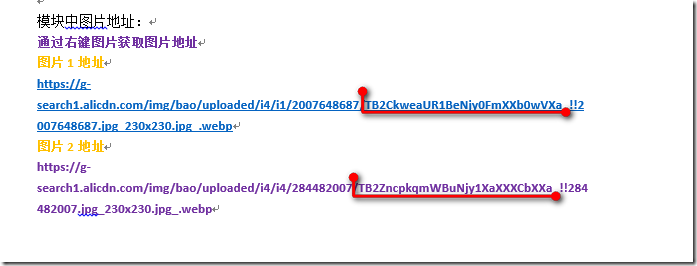
图片中标记的地方或许是两个图片最大的差别,于是打开源代码搜索
图片1搜索结果

图片2搜索结果

从两个网址我们发现了共同的特征:都是以"pic_url":"//开头,网址分析到此结束,那么我们接下来就写代码了。
代码如下:
import urllib.request
import re
#设置关键字
keywords = "羽绒服"
#quote函数进行url编码(屏蔽特殊的字符)
key = urllib.request.quote(keywords)
#设置User-Agent
headers=("User_Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0")
#自定义opener
opener = urllib.request.build_opener()
opener.addheaders = [headers]
urllib.request.install_opener(opener)
#循环遍历抓取
for i in range(0,2):
url = "https://s.taobao.com/list?spm=a21bo.2017.201867-links-0.3.5af911d9rLmo4K&q="+key+"&cat=16&style=grid&seller_type=taobao&bcoffset=12&s="+str(i*60)
#print(url)
content = urllib.request.urlopen(url).read().decode("utf-8","ignore")
rule = '"pic_url":"//(.*?)"' #正则匹配
imglist = re.compile(rule).findall(content) #获取图片列表
for j in range(0,len(imglist)):
img = imglist[j]
imgurl = "http://"+img
file = "D://source//img//"+str(i)+str(j)+".jpg"
urllib.request.urlretrieve(imgurl,filename=file)
爬取完毕后,我们可以打开D:\source\img查看
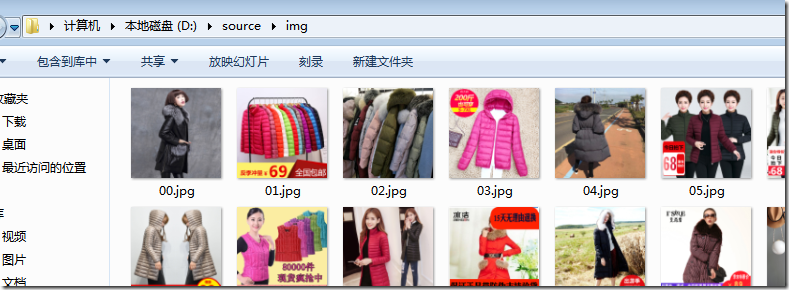
我们已经成功爬取,并且爬取的图片与页面上是一致的。
【Python3 爬虫】14_爬取淘宝上的手机图片的更多相关文章
- 甜咸粽子党大战,Python爬取淘宝上的粽子数据并进行分析
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 爬虫 爬取淘宝数据,本次采用的方法是:Selenium控制Chrome浏览 ...
- 学习用java基于webMagic+selenium+phantomjs实现爬虫Demo爬取淘宝搜索页面
由于业务需要,老大要我研究一下爬虫. 团队的技术栈以java为主,并且我的主语言是Java,研究时间不到一周.基于以上原因固放弃python,选择java为语言来进行开发.等之后有时间再尝试pytho ...
- Python 002- 爬虫爬取淘宝上耳机的信息
参照:https://mp.weixin.qq.com/s/gwzym3Za-qQAiEnVP2eYjQ 一般看源码就可以解决问题啦 #-*- coding:utf-8 -*- import re i ...
- python 网路爬虫(二) 爬取淘宝里的手机报价并以价格排序
今天要写的是之前写过的一个程序,然后把它整理下,巩固下知识点,并对之前的代码进行一些改进. 今天要爬取的是淘宝里的关于手机的报价的信息,并按照自己想要价格来筛选. 要是有什么问题希望大佬能指出我的错误 ...
- 【Python爬虫案例学习】python爬取淘宝里的手机报价并以价格排序
第一步: 先分析这个url,"?"后面的都是它的关键字,requests中get函数的关键字的参数是params,post函数的关键字参数是data, 关键字用字典的形式传进去,这 ...
- python3编写网络爬虫16-使用selenium 爬取淘宝商品信息
一.使用selenium 模拟浏览器操作爬取淘宝商品信息 之前我们已经成功尝试分析Ajax来抓取相关数据,但是并不是所有页面都可以通过分析Ajax来完成抓取.比如,淘宝,它的整个页面数据确实也是通过A ...
- 利用Python爬虫爬取淘宝商品做数据挖掘分析实战篇,超详细教程
项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 项目目的 1. 对商品标题进行文本分析 词云可视化 2. ...
- python爬虫学习(三):使用re库爬取"淘宝商品",并把结果写进txt文件
第二个例子是使用requests库+re库爬取淘宝搜索商品页面的商品信息 (1)分析网页源码 打开淘宝,输入关键字“python”,然后搜索,显示如下搜索结果 从url连接中可以得到搜索商品的关键字是 ...
- selenium跳过webdriver检测并爬取淘宝我已购买的宝贝数据
简介 上一个博文已经讲述了如何使用selenium跳过webdriver检测并爬取天猫商品数据,所以在此不再详细讲,有需要思路的可以查看另外一篇博文. 源代码 # -*- coding: utf-8 ...
随机推荐
- QTP自动化测试框架的基础知识
1. 什么是自动化测试框架? 假定你有一个活,需要构建许多自动化测试用例来测试这个应用程序.当你对这个应用程序完成自动化测试后,你对自己创建脚本应该有什么期望吗?你难道不想要- 脚本应该按照预期的来执 ...
- secureCRT的自动登录设置
具体设置的步骤如下: 1. 打scrt,创建一个新的回话 2. 右击该回话选择属性,定位到左边选项卡的登录动作 3. 第一行:预期是$; 发送是ssh username@machine name 第二 ...
- JavaWEB开发框架:Shiro
通过了三个月的实习,在javaWEB开发的过程当中,学习到了一些新的知识,特此记录一下学习到的一种新的WEB开发当中常用的用户认证和授权的安全框架,Shiro. 首先,要先知道shiro这个框架主要在 ...
- mysql TIMESTAMPDIFF
在MySQL应用时,经常要使用这两个函数TIMESTAMPDIFF和TIMESTAMPADD. 一,TIMESTAMPDIFF 语法: TIMESTAMPDIFF(interval,datetime_ ...
- bisect二分查找模块使用
import bisectL = [1, 3, 3, 6, 8, 12, 15]x = 5x_insert_point = bisect.bisect_left(L, x)# 在L中查找x,x存在时返 ...
- POJ 1988 Cube stacking【并查集高级应用+妙用deep数组】
Description Farmer John and Betsy are playing a game with N (1 <= N <= 30,000)identical cubes ...
- Problem E: 零起点学算法25——判断是否直角三角形
#include<stdio.h> int main() { int a,b,c; while(scanf("%d %d %d",&a,&b,& ...
- Java小问题的解决方法系列
1)IDEA中文乱码,解决方法:http://blog.csdn.net/zht666/article/details/8953516 2)卸载OpenJdk,http://my.oschina.ne ...
- 【转载】Mini6410启动过程
这段时间在尝试使用uBoot来替代友善的Superboot,让板子支持从SD卡启动,所以就仔细研究了一下友善提供的内核和它的启动参数,发现 友善真的蛮聪明,把电脑的启动方式借鉴到它们自己的开发板上了. ...
- identifier is too long 异常处理
修改了oracle中的表. 报 identifier is too long 错误 我执行的脚本是: ---备份create table MDT_AGREEMENTMANAGEMENT_2018080 ...