学习用java基于webMagic+selenium+phantomjs实现爬虫Demo爬取淘宝搜索页面
由于业务需要,老大要我研究一下爬虫。
团队的技术栈以java为主,并且我的主语言是Java,研究时间不到一周。基于以上原因固放弃python,选择java为语言来进行开发。等之后有时间再尝试python来实现一个。
本次爬虫选用了webMagic+selenium+phantomjs,选用他们的原因如下:
webMagic(v:0.73),一个轻量级的Java爬虫框架(git地址:https://github.com/code4craft/webmagic,主页地址:http://webmagic.io/):
- 时间和个人水平关系,放弃重复造轮子实现一套,固上网找一个框架(技术不好限制了我的风骚想法)
- webMagic是一款国人实现的轻量级爬虫框架,注释肯定是中文(英文不好限制了我的选择范围)
- 文档不少,而且用的人多,有问题网上好找解答
selenium,一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样,配合chromeDriver就可以通过代码对谷歌浏览器为所欲为了,阶段测试时候需要驱动谷歌浏览器的chromeDriver(附上下载地址:http://npm.taobao.org/mirrors/chromedriver/)
- 因为本次爬取目标是淘宝网,淘宝使用的Js渲染加大了爬取的难度,如果根据接口去爬取,需要搞清楚各种接口参数在哪里,非常麻烦,而且可能某些参数实在找不到,所以选用selenium直接用浏览器渲染,降低了找不到参数的引起尴尬场面的风险
- 但是用浏览器爬取必然会大大降低爬取效率,如果简单网站还是不建议使用这种方式
phantomjs,一个基于webkit内核的无头浏览器,即没有UI界面,即它就是一个浏览器,只是其内的点击、翻页等人为相关操作需要程序设计实现。(附上下载地址:http://phantomjs.org/):
如果每次爬取都要开启一个chrome浏览器,那简直就是内存噩梦,所以采用phantomjs来充当浏览器
说完框架的选择, 我们先贴上设计图:
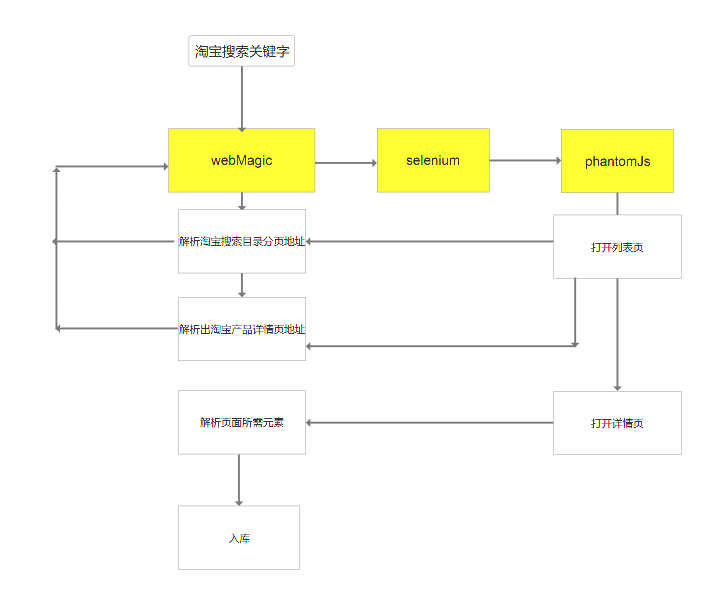
然后我们再贴上使用的jar包:
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.0.1</version>
</dependency>
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-chrome-driver</artifactId>
<version>3.0.1</version>
</dependency> <dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-remote-driver</artifactId>
<version>3.0.1</version>
</dependency> <dependency>
<groupId>com.codeborne</groupId>
<artifactId>phantomjsdriver</artifactId>
<version>1.2.1</version>
</dependency> <dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-exec</artifactId>
<version>1.3</version>
</dependency>
1、先让我们用chromeDriver测试一波selenium:
package com.chinaredstar.jc.crawler.biz.test.chrome; import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriverService;
import org.openqa.selenium.remote.DesiredCapabilities;
import org.openqa.selenium.remote.RemoteWebDriver;
import org.openqa.selenium.support.ui.ExpectedCondition;
import org.openqa.selenium.support.ui.WebDriverWait; import java.io.File;
import java.io.IOException; /**
* chromeDriver是谷歌的浏览器驱动,用来适配Selenium,有图形页面存在,在调试爬虫下载运行的功能的时候会相对方便
* @author zhuangj
* @date 2017/11/14
*/
public class TestChromeDriver { private static ChromeDriverService service; public static WebDriver getChromeDriver() throws IOException {
System.setProperty("webdriver.chrome.driver","C:/Users/sunlc/AppData/Local/Google/Chrome/Application/chrome.exe");
// 创建一个 ChromeDriver 的接口,用于连接 Chrome(chromedriver.exe 的路径可以任意放置,只要在newFile()的时候写入你放的路径即可)
service = new ChromeDriverService.Builder().usingDriverExecutable(new File("D:\\chromedriver\\qd-chromedriver_pc18\\qd-chromedriver_pc18\\chromedriver.exe")) .usingAnyFreePort().build();
service.start();
// 创建一个 Chrome 的浏览器实例
return new RemoteWebDriver(service.getUrl(), DesiredCapabilities.chrome());
} public static void main(String[] args) throws IOException { WebDriver driver = TestChromeDriver.getChromeDriver();
// 让浏览器访问 Baidu
driver.get("https://www.taobao.com/");
// 用下面代码也可以实现
//driver.navigate().to("http://www.baidu.com");
// 获取 网页的 title
System.out.println(" Page title is: " +driver.getTitle());
// 通过 id 找到 input 的 DOM
WebElement element =driver.findElement(By.id("q"));
// 输入关键字
element.sendKeys("东鹏瓷砖");
// 提交 input 所在的 form
element.submit();
// 通过判断 title 内容等待搜索页面加载完毕,间隔秒
new WebDriverWait(driver, 10).until(new ExpectedCondition() {
@Override
public Object apply(Object input) {
return ((WebDriver)input).getTitle().toLowerCase().startsWith("东鹏瓷砖");
}
});
// 显示搜索结果页面的 title
System.out.println(" Page title is: " +driver.getTitle());
// 关闭浏览器
driver.quit();
// 关闭 ChromeDriver 接口
service.stop();
} }
看结果:
经过上网查询,测试是chrome驱动器与我本地的chrome浏览器版本对不上,chromDriver和浏览器的对应版本如下:
| chromedriver版本 | 支持的Chrome版本 |
|---|---|
| v2.33 | v60-62 |
| v2.32 | v59-61 |
| v2.31 | v58-60 |
| v2.30 | v58-60 |
| v2.29 | v56-58 |
| v2.28 | v55-57 |
| v2.27 | v54-56 |
| v2.26 | v53-55 |
| v2.25 | v53-55 |
| v2.24 | v52-54 |
| v2.23 | v51-53 |
| v2.22 | v49-52 |
| v2.21 | v46-50 |
| v2.20 | v43-48 |
| v2.19 | v43-47 |
| v2.18 | v43-46 |
| v2.17 | v42-43 |
| v2.13 | v42-45 |
| v2.15 | v40-43 |
| v2.14 | v39-42 |
| v2.13 | v38-41 |
| v2.12 | v36-40 |
| v2.11 | v36-40 |
| v2.10 | v33-36 |
| v2.9 | v31-34 |
| v2.8 | v30-33 |
| v2.7 | v30-33 |
| v2.6 | v29-32 |
| v2.5 | v29-32 |
| v2.4 | v29-32 |
重新下载chromeDriver后:浏览器按照预想开启查询关闭:ide控制台打印如下:

2、然后我们来测试一波phantomJs:
(其实中间有一段测试失败,但是忘了是什么原因了,就不去重现了)
package com.chinaredstar.jc.crawler.biz.test.phantomjs; import org.openqa.selenium.WebDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriverService;
import org.openqa.selenium.remote.DesiredCapabilities; /**
* PhantomJs是一个基于webkit内核的无头浏览器,即没有UI界面,即它就是一个浏览器,只是其内的点击、翻页等人为相关操作需要程序设计实现;
* 因为爬虫如果每次爬取都调用一次谷歌浏览器来实现操作,在性能上会有一定影响,而且连续开启十几个浏览器简直是内存噩梦,
* 因此选用phantomJs来替换chromeDriver
* PhantomJs在本地开发时候还好,如果要部署到服务器,就必须下载linux版本的PhantomJs,相比window操作繁琐
* @author zhuangj
* @date 2017/11/14
*/
public class TestPhantomJsDriver { public static PhantomJSDriver getPhantomJSDriver(){
//设置必要参数
DesiredCapabilities dcaps = new DesiredCapabilities();
//ssl证书支持
dcaps.setCapability("acceptSslCerts", true);
//截屏支持
dcaps.setCapability("takesScreenshot", false);
//css搜索支持
dcaps.setCapability("cssSelectorsEnabled", true);
//js支持
dcaps.setJavascriptEnabled(true);
//驱动支持
dcaps.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY,"D:\\chromedriver\\phantomjs-2.1.1-windows\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe"); PhantomJSDriver driver = new PhantomJSDriver(dcaps);
return driver;
} public static void main(String[] args) {
WebDriver driver=getPhantomJSDriver();
driver.get("http://www.baidu.com");
System.out.println(driver.getCurrentUrl());
}
}
看结果:

3、我们用WebMagic把他们整合:
controller:
@RequestMapping("/testTaoBaoSearch")
public RestResultVo testTaoBaoSearch(String keyWord){
Spider spider=Spider.create(new TestTaoBaoPageProcessor(keyWord));
HttpClientDownloader httpClientDownloader = new HttpClientDownloader();
//免费代理不稳定老挂
// httpClientDownloader.setProxyProvider(SimpleProxyProvider.from(new Proxy("0.0.0.0",0000)));
spider.setDownloader(httpClientDownloader);
spider.addUrl("https://s.taobao.com/search?q="+keyWord).thread(1).run();
return null;
}
TestTaoBaoPageProcessor:
package com.chinaredstar.jc.crawler.biz.test.taobao; import com.chinaredstar.jc.crawler.biz.test.chrome.TestChromeDriver;
import com.chinaredstar.jc.crawler.biz.test.phantomjs.TestPhantomJsDriver;
import org.apache.commons.lang.StringUtils;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
import us.codecraft.webmagic.selector.Selectable; import java.io.IOException;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List; /**
*
* @author zhuangj
* @date 2017/11/13
*/
public class TestTaoBaoPageProcessor implements PageProcessor { private String keyWord; private static final String TAO_BAO_DETAIL_URL_START="https://item.taobao.com/item.htm"; private static final String TIAN_MAO_DETAIL_URL_START="https://detail.tmall.com/item.htm"; private Site site = Site
.me()
.setCharset("UTF-8")
.setCycleRetryTimes(3)
.setSleepTime(3 * 1000)
.addHeader("Connection", "keep-alive")
.addHeader("Cache-Control", "max-age=0")
.addHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0"); public String getKeyWord() {
return keyWord;
} public void setKeyWord(String keyWord) {
this.keyWord = keyWord;
} public TestTaoBaoPageProcessor() {
} public TestTaoBaoPageProcessor(String keyWord) {
this.keyWord = keyWord;
} @Override
public Site getSite() {
return site;
} @Override
public void process(Page page) {
WebDriver driver= TestPhantomJsDriver.getPhantomJSDriver();
// WebDriver driver= null;
// try {
// driver = TestChromeDriver.getChromeDriver();
// } catch (IOException e) {
// e.printStackTrace();
// }
driver.get(page.getRequest().getUrl());
WebElement webElement = driver.findElement(By.id("page"));
String str = webElement.getAttribute("outerHTML"); Html html = new Html(str);
if(isFirstPage(html)){
analysisPagination(page,html);
}else if(isListPage(html)){
analysisListPage(page,html,driver);
}else {
analysisDetailPage(page,html,driver);
}
} private void analysisListPage(Page page, Html html, WebDriver driver) {
List<String> detailPageList= html.xpath("//*[@id=\"mainsrp-itemlist\"]").$("a[id^='J_Itemlist_TLink_']").xpath("//a/@href").all();
page.addTargetRequests(detailPageList);
} /**
* 分析分页规则
* @param page
* @param html
*/
private void analysisPagination(Page page,Html html){
List<String> pageList= html.xpath("//*[@id=\"mainsrp-pager\"]/div/div/div/ul/li/a/@data-value").all();
pageList = new ArrayList(new HashSet(pageList)); List<String> pageParameterList=new ArrayList<>();
for(String value:pageList){
pageParameterList.add("https://s.taobao.com/search?q="+getKeyWord()+"&s="+value);
}
page.addTargetRequests(pageParameterList);
} /**
* 分析详情页
* @param page
* @param html
* @param driver
*/
private void analysisDetailPage(Page page,Html html,WebDriver driver){
String url=page.getUrl().toString();
if(url.startsWith(TAO_BAO_DETAIL_URL_START)){
analysisTaoBaoDetailPage(page,html,driver);
}else if(url.startsWith(TIAN_MAO_DETAIL_URL_START)){
analysisTianMaoDetailPage(page,html,driver);
}
} /**
* 分析淘宝详情页
* @param page
* @param html
* @param driver
*/
private void analysisTaoBaoDetailPage(Page page,Html html,WebDriver driver){
page.putField("price", html.xpath("//[@id=\"J_StrPrice\"]/em[2]/text()").toString());
page.putField("shopName", html.xpath("//*[@id=\"J_ShopInfo\"]/div/div[1]/div[1]/dl/dd/strong/a/text()").toString());
page.putField("title", html.xpath("////*[@id=\"J_Title\"]/h3/text()").toString()); } /**
* 分析天猫详情页
* @param page
* @param html
* @param driver
*/
private void analysisTianMaoDetailPage(Page page,Html html,WebDriver driver){
page.putField("price", html.xpath("//[@id=\"J_StrPriceModBox\"]/dd/span/text()").toString());
page.putField("shopName", driver.findElement(By.name("seller_nickname")).getAttribute("value"));
page.putField("name", html.xpath("//[@id=\"J_DetailMeta\"]/div[1]/div[1]/div/div[1]/h1/text()").toString());
} /**
* 是否为列表页
* @param html
* @return
*/
private boolean isListPage(Html html) {
String tmp = html.$("#mainsrp-pager").get();
if (StringUtils.isNotBlank(tmp)) {
return true;
}
return false;
} /**
* 列表页获取当前页码
* @param html
* @return
*/
private String getCurrentPageNo(Html html){
return html.xpath("//*[@id=\"mainsrp-pager\"]/div/div/div/ul/li[contains(@class,'active')]/span/text()").toString();
} /**
* 判断是否列表页的第一页
* @param html
* @return
*/
private Boolean isFirstPage(Html html){
return isListPage(html)&&getCurrentPageNo(html).equals("1");
} }
数据保存到数据库:
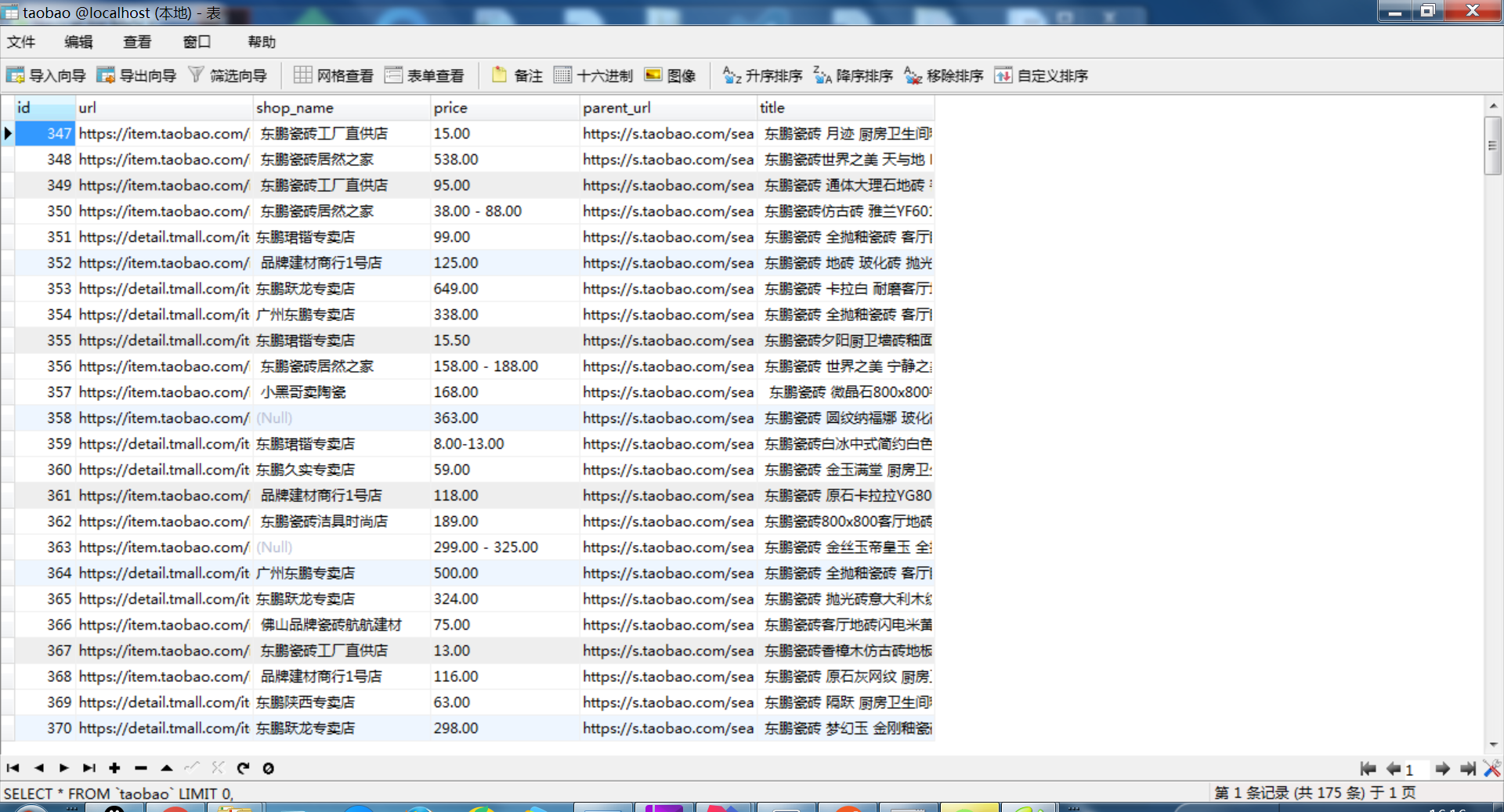
这里有几点:
- WebMagic的抽取主要用到了Jsoup和webMagic作者开发的工具Xsoup,并不懂这个语法还自己学了下。xpath如果自己抓取绝对累死,可以用chrome浏览器自带功能
使用chrome抓取时候数据正常,改为phantomJs时候数据错乱,一脸懵逼。为了查找原因,就到追溯爬虫爬取过程,修改了webMagic的Request类,给他添加parentUrl属性。
package com.chinaredstar.jc.crawler.biz.test.extend; import us.codecraft.webmagic.Request; /**
*
* @author zhuangj
* @date 2017/11/15
*/
public class RequestExtend extends Request { private String parentUrl; public RequestExtend(String url,String parentUrl) {
super(url);
this.parentUrl = parentUrl;
} public String getParentUrl() {
return parentUrl;
} public void setParentUrl(String parentUrl) {
this.parentUrl = parentUrl;
}
}
- WebMagic的抽取主要用到了Jsoup和webMagic作者开发的工具Xsoup,并不懂这个语法还自己学了下。xpath如果自己抓取绝对累死,可以用chrome浏览器自带功能
- 分析方法的时候写上父级的URl,方便如果有数据问题进行追溯。
private void analysisListPage(Page page, Html html, WebDriver driver) {
RequestExtend requestExtend= (RequestExtend) page.getRequest();
System.out.println("parentUrl:"+requestExtend.getParentUrl());
System.out.println("nowUrl:"+page.getUrl());
List<String> detailPageList= html.xpath("//*[@id=\"mainsrp-itemlist\"]").$("a[id^='J_Itemlist_TLink_']").xpath("//a/@href").all();
for(String deetailPage:detailPageList){
RequestExtend extend=new RequestExtend("https:"+deetailPage,page.getUrl().toString());
page.addTargetRequest(extend);
}
}
- 详情页获取父节点也可以完成。
/**
* 分析淘宝详情页
* @param page
* @param html
* @param driver
*/
private void analysisTaoBaoDetailPage(Page page,Html html,WebDriver driver){
RequestExtend requestExtend= (RequestExtend) page.getRequest();
System.out.println("parentUrl:"+requestExtend.getParentUrl());
System.out.println("nowUrl:"+page.getUrl());
page.putField("price", html.xpath("//[@id=\"J_StrPrice\"]/em[2]/text()").toString());
String shopName=html.xpath("//*[@id=\"J_ShopInfo\"]/div/div[1]/div[1]/dl/dd/strong/a/text()").toString();
if(StringUtils.isBlank(shopName)){
shopName=html.xpath("//*[@id=\"header-content\"]/div[2]/div[1]/div[1]/a/text()").toString();
}
page.putField("shopName", shopName);
page.putField("title", html.xpath("////*[@id=\"J_Title\"]/h3/text()").toString()); TaoBaoPo po=new TaoBaoPo();
po.setParentUrl(requestExtend.getParentUrl());
po.setPrice(page.getResultItems().get("price"));
po.setShopName(page.getResultItems().get("shopName"));
po.setTitle(page.getResultItems().get("title"));
po.setUrl(page.getUrl().toString());
taoBaoCrawlerService.saveProductDetail(po);
}
- 问题的排查结果是我查询时候keyWord是中文。chromeDriver可以处理而phantomJs不能识别,给加一个url转码:
/**
* 使用chromeDriver程序正常运行,转换成PhtanomJs后发现查询到的数据不是想要的数据,复制HTML查看页面后,
* 发现搜索的数据是错乱的,搜索框上显示着???,猜测是转码的问题,经过URLEncode之后,程序正常运行。
* @return
*/
public String getKeyWord() {
try {
return URLEncoder.encode(keyWord,"UTF-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return StringUtils.EMPTY;
}- 测试的时候代码越跑越慢,打开进程发现一堆phantomJs,固在process结束之后调用driver.quit()关闭phantomJs。
结语:本次demo虽然能跑起来但是还有很多很多不足,每次爬取搜索页只爬了四页,搜索的第一页也没爬,但是懒得再弄,保存数据应该用webMagic的Pipeline来处理,而且频繁的单次保存可以想办法用批量保存来替换;频繁的创建销毁driverJs并不合理,应该使用池化技术做一个DriverPool来管理;demo没有使用IP代理,容易被封,应该写一个IP代理池来管理第三方ip,不过要钱所以就算了。毕竟只是一个demo,剩余问题就不一一列举。
学习用java基于webMagic+selenium+phantomjs实现爬虫Demo爬取淘宝搜索页面的更多相关文章
- 一个小demo 实用selenium 抓取淘宝搜索页面内的产品内容
废话少说,上代码 #conding:utf-8 import re from selenium import webdriver from selenium.webdriver.common.by i ...
- selenium五十行代码自动化爬取淘宝
先看一下代码,真的只是五十行: # coding=gbk from selenium import webdriver import time options = webdriver.ChromeOp ...
- Selenium+Chrome/phantomJS模拟浏览器爬取淘宝商品信息
#使用selenium+Carome/phantomJS模拟浏览器爬取淘宝商品信息 # 思路: # 第一步:利用selenium驱动浏览器,搜索商品信息,得到商品列表 # 第二步:分析商品页数,驱动浏 ...
- selenium+PhantomJS 抓取淘宝搜索商品
最近项目有些需求,抓取淘宝的搜索商品,抓取的品类还多.直接用selenium+PhantomJS 抓取淘宝搜索商品,快速完成. #-*- coding:utf-8 -*-__author__ =''i ...
- 利用Selenium爬取淘宝商品信息
一. Selenium和PhantomJS介绍 Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样.由于这个性质,Selenium也是一 ...
- selenium跳过webdriver检测并爬取淘宝我已购买的宝贝数据
简介 上一个博文已经讲述了如何使用selenium跳过webdriver检测并爬取天猫商品数据,所以在此不再详细讲,有需要思路的可以查看另外一篇博文. 源代码 # -*- coding: utf-8 ...
- python3编写网络爬虫16-使用selenium 爬取淘宝商品信息
一.使用selenium 模拟浏览器操作爬取淘宝商品信息 之前我们已经成功尝试分析Ajax来抓取相关数据,但是并不是所有页面都可以通过分析Ajax来完成抓取.比如,淘宝,它的整个页面数据确实也是通过A ...
- Java 基于WebMagic 开发的网络爬虫
第一次接触爬虫,之所以选择WebMagic,是因为文档齐全.用法简单.而且框架一直在维护. WebMagic是一个简单灵活的Java爬虫框架.基于WebMagic,我们可以快速开发出一个高效.易维护的 ...
- Python selenium+phantomjs的js动态爬取
Selenium是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE.Mozilla Firefox.Chrome等.Phanto ...
随机推荐
- [Scikit-learn] 2.1 Clustering - Variational Bayesian Gaussian Mixture
最重要的一点是:Bayesian GMM为什么拟合的更好? PRML 这段文字做了解释: Ref: http://freemind.pluskid.org/machine-learning/decid ...
- 软硬链接、文件删除原理、linux中的三种时间、chkconfig优化
第1章 软硬链接 1.1 硬链接 1.1.1 含义 多个文件拥有相同的inode号码 硬链接即文件的多个入口 1.1.2 作用 防止你误删除文件 1.1.3 如何创建硬链接 ln 命令,前面是源文件 ...
- zepto在操作dom的selected和checked属性时尽量使用prop方法
zepto在操作dom的selected和checked属性时尽量使用prop方法.
- setInterval计时器延时问题
计时器延时问题 js计时器 使用setTimeout.setInterval函数时,第二个参数的设置的时间间隔t是自该函数(setTimeout(f1,t).setInterval(f1,t))被调用 ...
- jQuery选择器(子元素过滤选择器)第七节
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/stri ...
- HTML学习笔记 w3sCss盒子模型应用案例(div布局) 第十一节 (原创) 参考使用表
* { margin: 0px; padding: 0px; } .top { width: 100%; height: 50px; background-color: antiquewhite; } ...
- C#之可选参数和命名参数
设计方法的参数是,可以将部分参数和全部参数分配默认值,然后调用这些方法的时候可以选择不提供部分实参,使用参数定义的默认值,另外,还可以在调用方法的时候通过指定参数名称来传递实参. 例如: public ...
- Linux上jdk的安装
安装jdk a.检测是否安装了jdk 运行java -version b.若有需要将其卸载 c.查看安装那些jdk rpm -qa | grep java d. ...
- SElinux用户管理操作
查看当前用户上下文 id -Z 查看登陆的用户和其对应的SELinux用户 semanage login -l 改变用户和SELinux的对应关系 semanage login -a选项能改变,-s用 ...
- java的linux命令
1.查找文件find / -name filename.txt 根据名称查找/目录下的filename.txt文件.find . -name “*.xml” 递归查找所有的xml文件2.查看一个程序是 ...