kettle 链接oracle12c
jdbc连接cdb数据库时,url兼容以下2种模式:
"jdbc:oracle:thin:@192.168.75.131:1521:oracle12c"
"jdbc:oracle:thin:@192.168.75.131:1521/oracle12c"
jdbc连接pdb数据库时url必须使用:" jdbc:oracle:thin:@192.168.75.131:1521/oracle12c"格式,
若使用传统格式" jdbc:oracle:thin:@192.168.75.131:1521:oracle12c"则会报一下错误:
java.sql.SQLException: Listenerrefused the connection with the following error:
ORA-12505, TNS:listener does notcurrently know of SID given in connect descriptor
Kettle 如果用Native(JDBC)方式连接Oracle,默认是第一种方式,是无法连接上的
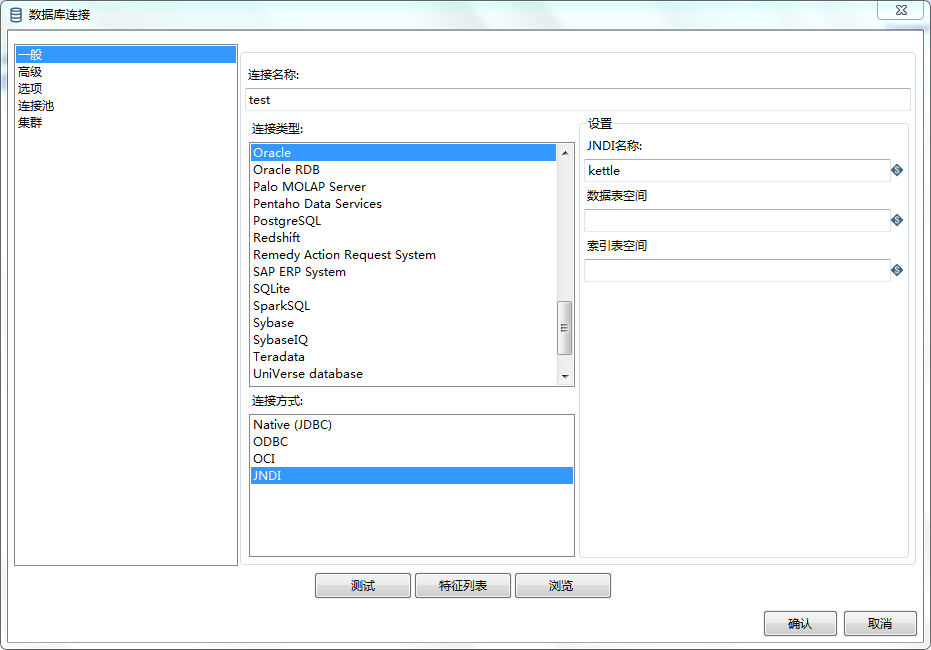
故我们采用JNDI方式连接:
打开Keetle安装目录以下找到jdbc.properties文件,并输入以下内容:
kettle/type=javax.sql.DataSource
kettle/driver=oracle.jdbc.driver.OracleDriver
kettle/url=jdbc:oracle:thin:@127.0.0.1:1535/szorcl
kettle/user=ps_ztb
kettle/password=ps_ztb
kettle链接设置:
kettle 链接oracle12c的更多相关文章
- kettle 连接oracle12c问题解决办法:
在oracle的安装文件目录......\NETWORK\ADMIN\sqlnet.ora 文件中添加该语句:SQLNET.ALLOWED_LOGON_VERSION_SERVER = 8window ...
- kettle与各数据库建立链接的链接字符串
kettle与各数据库建立链接的链接字符串 Sybase: TO_DB_URL = jdbc:sybase:Tds:192.168.168.163:5000/testdb?charset=eucgb& ...
- kettle使用命令行传入数据库链接参数(ip、数据库、端口、用户、密码)执行job时子转换失败。
使用cmd 传参数执行 kettle job 遇到错误: 错误原因,无法找到文件.... 原来使用,通过目录指定转换,好处是:当以文件资源库保存时,可以直接将文件夹复制走,直接运行就可以,不需要单独针 ...
- Kettle建立数据库链接报错-'MS SQL Server' driver (jar file) is installed. kettle的bug,对于12.2而言
1.链接sql server数据库报错 错误连接数据库 [My_vm_win_sql] : org.pentaho.di.core.exception.KettleDatabaseException: ...
- kettle两表内链接的查询结果与sql语句的查询结果不符合?
1.教师表输入 2.学生表 查 3.学生表中查出的教师id进行排序 5.教师表中查出的同样也对教师的id进行排序 6.进行左连接 总结: 进行连接的时候的关键是同样对教师的id进行先排序
- 大量数据快速导出的解决方案-Kettle
1.开发背景 在web项目中,经常会需要查询数据导出excel,以前比较常见的就是用poi.使用poi的时候也有两种方式,一种就是直接将集合一次性导出为excel,还有一种是分批次追加的方式适合数据量 ...
- Kettle实现MapReduce之WordCount
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 欢迎转载 抽空用kettle配置了一个Mapreduce的Word count,发现还是很方便快捷的,废话不多说 ...
- Pentaho Kettle 6.1连接CDH5.4.0集群
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 欢迎转载 最近把之前写的Hadoop MapReduce程序又总结了下,发现很多逻辑基本都是大致相同的,于是想到 ...
- Kettle 合并记录报错!
在Kettle的合并记录过程的时候,在“为了转换解除补丁开始 ”这一步的时候报错.具体错误如图所示: Kettle的转换如图所示: 问题原因:可能是你的数据库链接驱动和Kettle的版本不兼容. 解决 ...
- kettle教程(1) 简单入门、kettle简单插入与更新。打开kettle
本文要点:Kettle的建立数据库连接.使用kettle进行简单的全量对比插入更新:kettle会自动对比用户设置的对比字段,若目标表不存在该字段,则新插入该条记录.若存在,则更新. Kettle ...
随机推荐
- Elasticsearch基础但非常有用的功能之一:别名
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484454&idx=1&sn=43e95a2 ...
- 使用 Loki 搭建个人日志平台
文章转载自:https://blog.kelu.org/tech/2020/01/31/grafana-loki-for-logging-aggregation.html 背景 Loki的第一个稳定版 ...
- 5_SpringMVC
一. 什么是MVC框架 MVC全名是Model View Controller, 是模型(model), 视图(view), 控制器(controller)的缩写, 一种软件设计典范, 用一种业务逻辑 ...
- PAT (Basic Level) Practice 1021 个位数统计 分数 15
给定一个 k 位整数 N=dk−110k−1+⋯+d1101+d0 (0≤di≤9, i=0,⋯,k−1, dk−1>0),请编写程序统计每种不同的个位数字出现的次数.例如:给定 N= ...
- POJ2823 滑动窗口 (单调队列)
来学习一下单调队列: 他只可以从队尾入队,但可以从队尾或队首出队,来维护队列的单调性.单调队列有两种单调性:元素的值单调和元素的下标单调. 单调队列可以用来优化DP.状态转移方程形如dp[i]=min ...
- Js实现一键复制小功能
function copyToClipboard(textToCopy) { // navigator clipboard 需要https等安全上下文 if (navigator.clipboard ...
- rowkey设计原则和方法
rowkey设计首先应当遵循三大原则: 1.rowkey长度原则 rowkey是一个二进制码流,可以为任意字符串,最大长度为64kb,实际应用中一般为10-100bytes,它以byte[]形式保存, ...
- SpringBoot 2.5.5整合轻量级的分布式日志标记追踪神器TLog
TLog能解决什么痛点 随着微服务盛行,很多公司都把系统按照业务边界拆成了很多微服务,在排错查日志的时候.因为业务链路贯穿着很多微服务节点,导致定位某个请求的日志以及上下游业务的日志会变得有些困难. ...
- laravel 浏览器谷歌network返回报错html
laravel 在谷歌报错的时候会返回html,对于调试来说很不方便.原因是在于: 这里返回的格式是json,但是报错时候返回的是整个html所以 相对路径: app\Exceptions\Handl ...
- VScode将代码提交到远程服务器、同时解决每次提交都要输入密码的问题(这里以gitee为例子)
文章目录 1.第一种情况.项目直接从gitee上拉取下来 2.第二种情况.将新建的项目提交到远程服务器 3.解决将代码提交到远程每次都要输入用户名和密码 4.个人遇到的奇葩问题 1.第一种情况.项目直 ...