Kettle实现MapReduce之WordCount
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 欢迎转载
抽空用kettle配置了一个Mapreduce的Word count,发现还是很方便快捷的,废话不多说,进入正题.
一.创建Mapper转换
如下图,mapper读取hdfs输入,进行word的切分,输出每个word和整数常量值
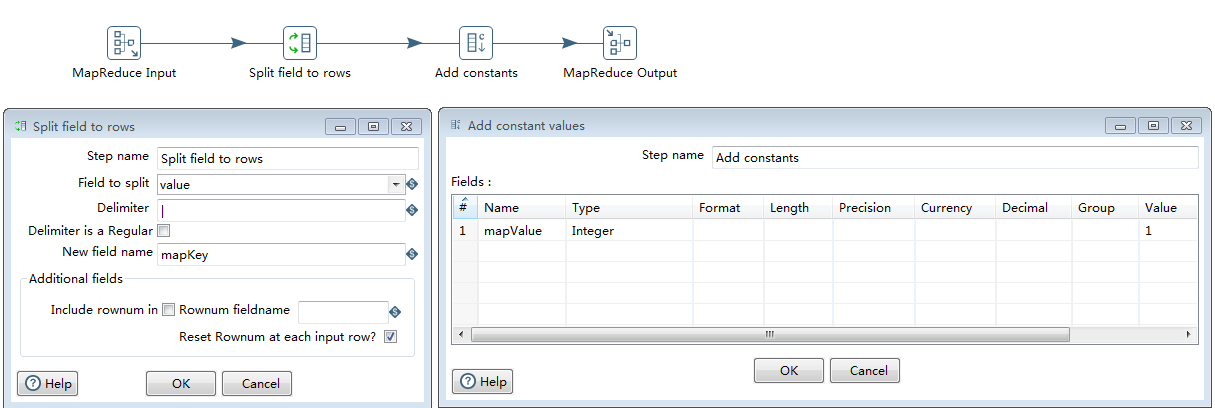
1>MapReduce Input:Mapper输入,读取HDFS上的输入文件内容以键值对存储;
2>Spit filed to rows:读取value值以分隔符 "|" 进行切分(注意我这里hdfs文件中的word是以"|"隔开的)
3>Add constants:给每次出现的word追加一个常量字段mapValue,值为整数1.
4>MapReduce Output:Mapper输出,key为每个word,这里为mapKey,value为常量值mapValue.
二.创建Reducer转换
如下图,Reducer读取mapper的输出.按照每个key值进行分组,对相应的常量值字段进行聚合,这里是做sum,然后最终输出到hdfs文件中去.
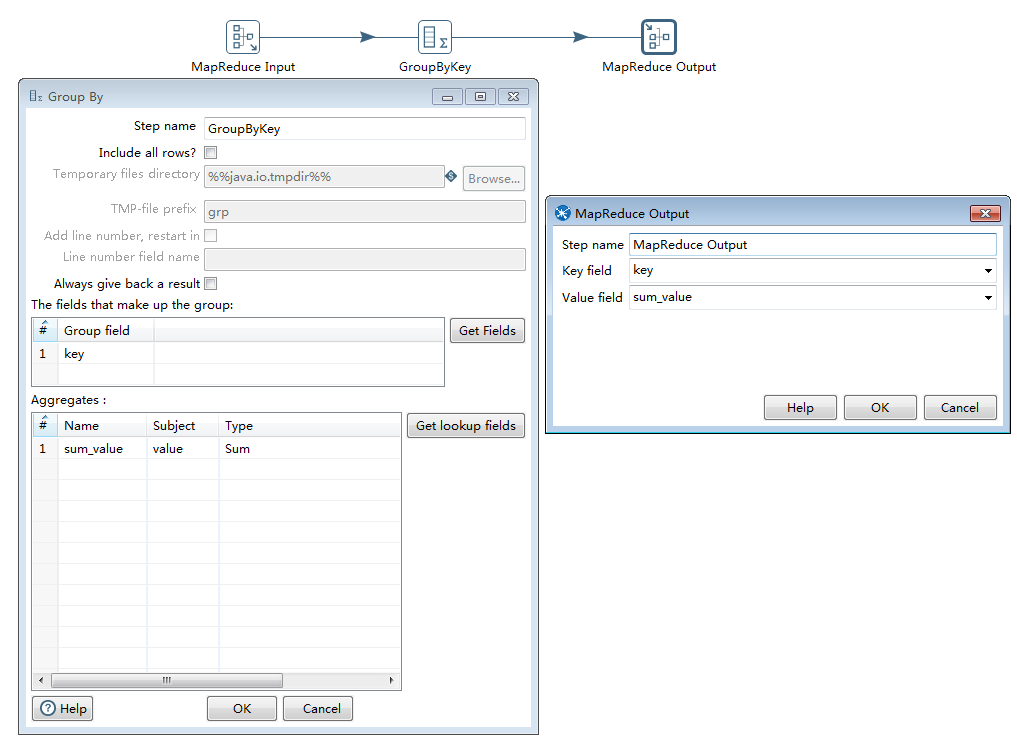
1>MapReduce input:读取Mapper中的输出作为Reducer的输入
2>GroupByKey:按照key进行分组(这里key是每个word), 然后对value进行聚合sum,求出每个word出现的总次数;
3>MapReduce Output:最终的键值对,每行以<单词,总次数>来输出到hdfs上去.
三.创建MapReduce Job.
创建最终的MapReduce Job,配置相应参数,调用Mapper和Reducer,见下图
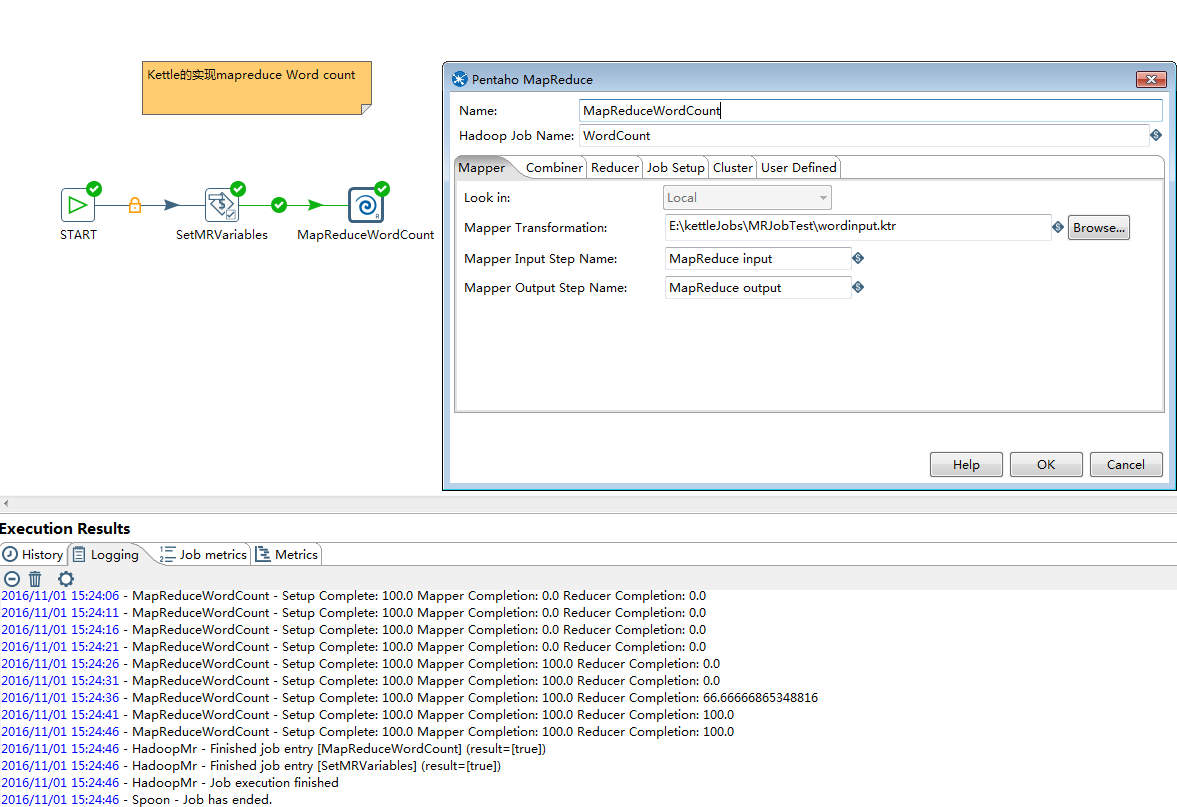
1>START:表示job的开始
2>SetMRVariables:组件是set variables,用于设置一些MapReduce执行所需要的参数的全局变量值,如hdfs input path等;
3>MapReduceWordCount:组件是Pentaho MapReduce组件,用来配置需要调用的Mapper和Reducer以及集群相关信息.
以上配置好以后执行MapReduce Job,会提交至Hadoop集群并运行成功,如上图,可以同时看到MapReduce的执行进度。
鉴于kettle能对字段做各种切分,组合以及正则等处理,还可以自定义java class,所以基本的MR程序都可以快速配置出来.
以上配置的Job下载链接:http://files.cnblogs.com/files/cssdongl/MRJobTest.7z
参考资料:http://wiki.pentaho.com/display/BAD/Understanding+How+Pentaho+works+with+Hadoop
Kettle实现MapReduce之WordCount的更多相关文章
- Java编程MapReduce实现WordCount
Java编程MapReduce实现WordCount 1.编写Mapper package net.toocruel.yarn.mapreduce.wordcount; import org.apac ...
- eclipse运行mapreduce的wordcount
1,eclipse安装hadoop插件 插件下载地址:链接: https://pan.baidu.com/s/1U4_6kLFNiKeLsGfO7ahXew 提取码: as9e 下载hadoop-ec ...
- MapReduce实现WordCount
package algorithm; import java.io.IOException; import java.util.StringTokenizer; import org.apache.h ...
- Hadoop实战5:MapReduce编程-WordCount统计单词个数-eclipse-java-windows环境
Hadoop研发在java环境的拓展 一 背景 由于一直使用hadoop streaming形式编写mapreduce程序,所以目前的hadoop程序局限于python语言.下面为了拓展java语言研 ...
- Hadoop实战3:MapReduce编程-WordCount统计单词个数-eclipse-java-ubuntu环境
之前习惯用hadoop streaming环境编写python程序,下面总结编辑java的eclipse环境配置总结,及一个WordCount例子运行. 一 下载eclipse安装包及hadoop插件 ...
- Hadoop 6、第一个mapreduce程序 WordCount
1.程序代码 Map: import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.h ...
- Hadoop Mapreduce中wordcount 过程解析
将文件split 文件1: 分割结果: hello world ...
- 三.hadoop mapreduce之WordCount例子
目录: 目录见文章1 这个案列完成对单词的计数,重写map,与reduce方法,完成对mapreduce的理解. Mapreduce初析 Mapreduce是一个计算框架,既然是做计算的框架,那么表现 ...
- 大数据技术 - 通俗理解MapReduce之WordCount(三)
上一章我们编写了简单的 MapReduce 程序,掌握这些就能编写大多数数据处理的代码.但是 MapReduce 框架提供给用户的能力并不止如此,本章我们仍然以上一章 word count 为例,继续 ...
随机推荐
- toolControls添加工具项
最近参考Arcengine的Samples做的功能,虽然简单,但是示例代码的确体现出了很好的封装性,值得学习,效果图如下: 闲话休絮,直入正题: 一.首先建立工具类,实现IMenuDef接口 clas ...
- Jumony快速抓取网页 --- Jumony使用笔记--icode
作者:郝喜路 个人主页:http://www.cnicode.com 博客地址:http://haoxilu.cnblogs.com 时间:2014年6月26日 19:25:02 ...
- SqlServer2012 数据库的同步之SQL JOB + 建立链接服务器
文章参考百度过的文章,现在忘了具体哪篇,感谢其分享,这里根据自己的操作和遇到的问题整理一下. 需求:在两个不同的SQL SERVER 2012的服务器之间进行数据访问和更新.我们需 ...
- Aoite 系列(03) - 一起来 Redis 吧!
Aoite 是一个适于任何 .Net Framework 4.0+ 项目的快速开发整体解决方案.Aoite.Data 适用于市面上大多数的数据库提供程序,通过统一封装,可以在日常开发中简单便捷的操作数 ...
- Java提高篇(三八)-----Java集合细节(四):保持compareTo和equals同步
在Java中我们常使用Comparable接口来实现排序,其中compareTo是实现该接口方法.我们知道compareTo返回0表示两个对象相等,返回正数表示大于,返回负数表示小于.同时我们也知道e ...
- FusionCharts简单教程(八)-----使用网格组件
有时候我们会觉得使用图像不够直接,对于数据的显示没有表格那样直接明了.所以这里就介绍如何使用网格组件.将网格与图像结合起来.网格组件能够将FusionCharts中的单序列数据以列表的 ...
- video.js html5 视频播放器
我个人感觉很不错 https://github.com/videojs/video.js <head> <title>Video.js | HTML5 Video Player ...
- 如何为编程爱好者设计一款好玩的智能硬件(七)——LCD1602点阵字符型液晶显示模块驱动封装(上)
当前进展: 一.我的构想:如何为编程爱好者设计一款好玩的智能硬件(一)——即插即用.积木化.功能重组的智能硬件模块构想 二.别人家的孩子:如何为编程爱好者设计一款好玩的智能硬件(二)——别人是如何设计 ...
- 三天学会HTML5 ——多媒体元素的使用
目录 1. HTML5 Media-Video 2. HTML5 Media-Audio 3. 拖拽操作 4. 获取位置信息 5. 使用Google 地图获取位置信息 多媒体是互联网中的最重要的一部分 ...
- IBatisNet:让insert操作返回新增记录的主键值
项目引用ibatis包: IBatisNet.Common.dll --文件版本1.6.2.0 IBatisNet.DataAccess.dll IBatisNet.DataMapper.dll 项目 ...