scrapy 简介
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架。
Scrapy架构图(绿线是数据流向):
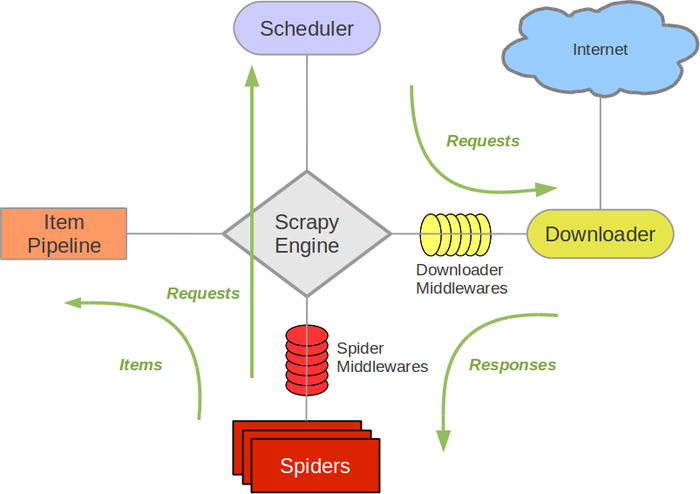
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
Scrapy的运作流程
代码写好,程序开始运行...
引擎:Hi!Spider, 你要处理哪一个网站?Spider:老大要我处理xxxx.com。引擎:你把第一个需要处理的URL给我吧。Spider:给你,第一个URL是xxxxxxx.com。引擎:Hi!调度器,我这有request请求你帮我排序入队一下。调度器:好的,正在处理你等一下。引擎:Hi!调度器,把你处理好的request请求给我。调度器:给你,这是我处理好的request引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。引擎:Hi !管道我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。管道``调度器:好的,现在就做!
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy也会重新下载。)
制作 Scrapy 爬虫 一共需要4步:
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
scrapy 简介的更多相关文章
- Scrapy简介
什么是Scrapy? Scrapy是一个快速.高级的爬行器和网页抓取框架,用来抓取网站和提取网页中结构化的数据.它被广泛的使用于监控数据采集和自动化测试. 参考:http://scrapy.org/
- 网络爬虫框架Scrapy简介
作者: 黄进(QQ:7149101) 一. 网络爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本:它是一个自动提取网页的程序,它为搜索引擎从万维 ...
- 爬虫-爬虫介绍及Scrapy简介
在编写案例之前首先理解几个问题,1:什么是爬虫2:为什么说python是门友好的爬虫语言?3:选用哪种框架编写爬虫程序 一:什么是爬虫? 爬虫 webSpider 也称之为网络蜘蛛,是使用一段编写好的 ...
- 爬虫之scrapy简介
原始的爬虫流程:效率低.同步.阻塞 scrapy执行流程:效率高.异步.非阻塞 scrapy的概念 scrapy是一个爬虫框架 开发速度快 稳定性高 性能优越 scrapy的流程 1. 爬虫模块(Sp ...
- Scrapy开发指南
一.Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. Scrapy基于事件驱动网络框架 Twis ...
- Scrapy安装介绍
一. Scrapy简介 Scrapy is a fast high-level screen scraping and web crawling framework, used to crawl we ...
- python爬虫入门(六) Scrapy框架之原理介绍
Scrapy框架 Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬 ...
- 爬虫框架之Scrapy(一)
scrapy简介 scrapy是一个用python实现为了爬取网站数据,提取结构性数据而编写的应用框架,功能非常的强大. scrapy常应用在包括数据挖掘,信息处理或者储存历史数据的一系列程序中. s ...
- scrapy爬虫学习系列一:scrapy爬虫环境的准备
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
随机推荐
- 表格中的IE BUG
在表格应用了跨列单元格后,在IE6/7下当跨列单元格中的元素长度超过其跨列单元格中第一个单元格的宽度时会产生换行,如下所示: 解决方法: 1. 设置 table 的 'table-layout' 特性 ...
- pig笔记
1.安装Pig 将pig添加到环境变量当中 2.pig使用 首先将数据库中的数据导入到HDFS上 sqoop import --connect jdbc:mysql://192.168.1.10:33 ...
- react-native 模仿原生 实现下拉刷新/上拉加载更多(RefreshListView)
1.下拉刷新/上拉加载更多 组件(RefreshListView) src/components/RefreshListView/index.js /** * 下拉刷新/上拉加载更多 组件(Refre ...
- android开发中,在java中怎样使用c提供过来char*
这个char*假设是一般的字符串的话,作为string传回去就能够了.假设是含有'\0'的buffer,最好作为bytearray传出,由于能够制定copy的length.假设copy到string, ...
- git 命令使用速查手册( 个人版)
1. 克隆远程库 git clone repository_address 通过 git clone 获取的git库只是远程库中的当前工作分支,如果想获取其它分支信息,可参考下面. 2. 查看远程 ...
- 用Darwin开发RTSP级联server(拉模式转发)(附源代码)
源代码下载地址:https://github.com/EasyDarwin orwww.easydarwin.org 在博客 在Darwin进行实时视频转发的两种模式 中,我们描写叙述了流媒体serv ...
- find命令下排除部分目录修改权限
#!/bin/bash # 项目文件夹.文件权限修改 # 批量修改文件夹或者文件的权限时,需要先忽略掉可写文件夹('./bootstrap/cache'.'./public/attachments'. ...
- 判断当前VC 是push还是present的
NSArray *viewcontrollers=self.navigationController.viewControllers; if (viewcontrollers.count>1) ...
- Windows下MySQL備份與還原
方法一 備份: C:\...\MySQL\MySQL Server 5.1\bin\>mysqldump aa -u root -p > d:\aaa.sql.bak 還原: C:\... ...
- Atitit. c# 语法新特性 c#2.0 3.0 4.0 4.5 5.0 6.0 attilax总结
Atitit. c# 语法新特性 c#2.0 3.0 4.0 4.5 5.0 6.0 attilax总结 1.1. C# 1.0-纯粹的面向对象 1.2. C# 2.0-泛型编程新概念 1.3. ...