Python的scrapy之爬取豆瓣影评和排名
基于scrapy框架的爬影评
爬虫主程序:
import scrapy
from ..items import DoubanmovieItem class MoviespiderSpider(scrapy.Spider):
name = 'moviespider'
allowed_domains = ['douban.com']
start_urls = ['http://movie.douban.com/top250'] def parse(self, response):
movie_items=response.xpath('//div[@class="item"]')
for item in movie_items:
#print(type(item)) movie =DoubanmovieItem()
movie['rank']=item.xpath('div[@class="pic"]/em/text()').extract()
movie['title']=item.xpath('div[@class="info"]/div[@class="hd"]/a/span[@class="title"][1]/text()').extract()
movie['quote'] = item.xpath(
'div[@class="info"]/div[@class="bd"]/p[@class="quote"]/span[@class="inq"][1]/text()').extract()
movie['star'] = item.xpath(
'div[@class="info"]/div[@class="bd"]/div[@class="star"]/span/text()').extract() movie['src']=item.xpath(
'div[@class="pic"]/a/img/@src').extract() yield movie
pass #取下一页的地址
nextPageURL = response.xpath('//span[@class="next"]/a/@href').extract()
#print(nextPageURL)
if nextPageURL:
url = response.urljoin(nextPageURL[-1])
#print('url', url)
# 发送下一页请求并调用parse()函数继续解析
yield scrapy.Request(url, self.parse, dont_filter=False)
pass
else:
print("退出")
pass
items 对象
import scrapy class DoubanmovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
rank=scrapy.Field()
title=scrapy.Field()
quote=scrapy.Field()
star=scrapy.Field()
src=scrapy.Field()
pass
pipelines 输出管道
class DoubanmoviePipeline(object):
def process_item(self, item, spider):
print('电影排名:{0}'.format(item['rank'][0]))
print('电影名称:{0}'.format(item['title'][0]))
print('电影短评:{0}'.format(item['quote'][0]))
print('评价分数:{0}'.format(item['star'][0]))
print('评价人数:{0}'.format(item['star'][1]))
print('图片链接:{0}'.format(item['src']))
print('-' * 20)
return item
在控制台输出的结果
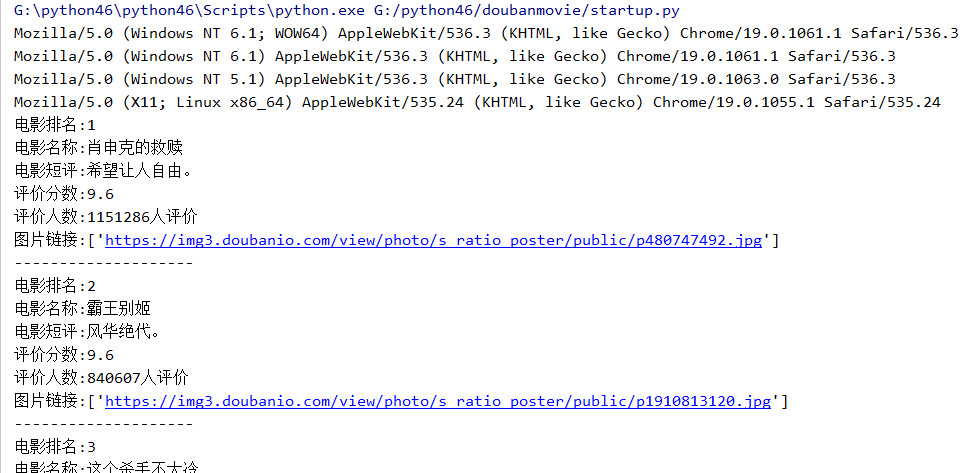
可以通过爬出的图片链接,下载电影的剧照,这就另说了,也可以设置一个插入数据库的管道,将这些数据插入到数据库中
Python的scrapy之爬取豆瓣影评和排名的更多相关文章
- 基于python的scrapy框架爬取豆瓣电影及其可视化
1.Scrapy框架介绍 主要介绍,spiders,engine,scheduler,downloader,Item pipeline scrapy常见命令如下: 对应在scrapy文件中有,自己增加 ...
- Scrapy 通过登录的方式爬取豆瓣影评数据
Scrapy 通过登录的方式爬取豆瓣影评数据 爬虫 Scrapy 豆瓣 Fly 由于需要爬取影评数据在来做分析,就选择了豆瓣影评来抓取数据,工具使用的是Scrapy工具来实现.scrapy工具使用起来 ...
- 【python数据挖掘】爬取豆瓣影评数据
概述: 爬取豆瓣影评数据步骤: 1.获取网页请求 2.解析获取的网页 3.提速数据 4.保存文件 源代码: # 1.导入需要的库 import urllib.request from bs4 impo ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- [超详细] Python3爬取豆瓣影评、去停用词、词云图、评论关键词绘图处理
爬取豆瓣电影<大侦探皮卡丘>的影评,并做词云图和关键词绘图第一步:找到评论的网页url.https://movie.douban.com/subject/26835471/comments ...
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- Python的scrapy之爬取顶点小说网的所有小说
闲来无事用Python的scrapy框架练练手,爬取顶点小说网的所有小说的详细信息. 看一下网页的构造: tr标签里面的 td 使我们所要爬取的信息 下面是我们要爬取的二级页面 小说的简介信息: 下面 ...
- python爬虫scrapy框架——爬取伯乐在线网站文章
一.前言 1. scrapy依赖包: 二.创建工程 1. 创建scrapy工程: scrapy staratproject ArticleSpider 2. 开始(创建)新的爬虫: cd Artic ...
随机推荐
- redis的使用方式
常用的语法以及使用方式: key中不能包含回车空格等,key不要太长,占用内存. 概念介绍: 差集: a:{1,2,3} b:{2,3,4},以a为锚点,差集 ...
- spring与mybatis的整合
整合的思路 SqlSessionFactory对象放到spring容器中作为单例存在. 传统dao的开发方式中,从spring容器中获得sqlsession对象. Mapper代理形式中,从sprin ...
- JavaScript 面向对象编程(四)的常用方法、属性总结
面向对象的属性.方法.操作符总结,都是干货.想深入掌握面向对象的程序设计模式,必须掌握一下知识点.下列知识点注重于实现,原理还请借鉴<javascript高级程序设计> (基于javasc ...
- Oracle服务端及客户端搭建帮助文档
Oracle服务端及客户端搭建帮助文档 目录 简介 Oracle服务端安装 Oracle客户端安装 PLSQL安装 登录测试 系统配置修改 用户操作 解锁账户.密码 创建账户及密码 配置监听文件 监听 ...
- CRUD全栈式编程架构之数据层的设计
CodeFirst 一直以来我们写应用的时候首先都是创建数据库 终于在orm支持codefirst之后,我们可以先建模. 通过模型去创建数据库,并且基于codefirst可以实现方便的 实现数据库迁移 ...
- 转载:em(倍)与px的区别
转载出处:http://www.cnblogs.com/showker/archive/2010/05/24/1742821.html 在国内网站中,包括三大门户,以及“引领”中国网站设计潮流的蓝色理 ...
- python:正则模块
1,正则表达式 正则表达式是用来做字符串的匹配的,正则有他自己的规则,和python没有关系,一种匹配字符串的规则. 2,字符组 在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表 ...
- Photoshop 画布的渐变填充
之前丢掉的要开始慢慢的捡起来,因为学如逆水行舟,不进则退.古人诚不欺我等. 1.新建图层,或者就在当前图层进行操作,选择图层 2.工具箱---1渐变工具---2径向渐变---模式--正常.不透明100 ...
- Linux 安装ruby编译环境
1.输入:yum install ruby 1.1如果安装文件出错Error Downloading Packages: 输入:yum clean all 输入:yum makecache,此时如果出 ...
- 【洛谷P2184】贪婪大陆
贪婪大陆 题目链接 对于一个区间[l,r],右端点在l左边即[1,l-1]中的区间与区间[l,r]没有交集, 左端点在r右边即[r,n]中的区间与区间[l,r]没有交集, 其余区间必与[l,r]有交集 ...