吴恩达深度学习笔记(七) —— Batch Normalization
主要内容:
一.Batch Norm简介
二.归一化网络的激活函数
三.Batch Norm拟合进神经网络
四.测试时的Batch Norm
一.Batch Norm简介
1.在机器学习中,我们一般会对输入数据进行归一化处理,使得各个特征的数值规模处于同一个量级,有助于加速梯度下降的收敛过程。
2.在深层神经网络中,容易出现梯度小时或者梯度爆炸的情况,导致训练速度慢。那么,除了对输入数据X进行归一化之外,我们是否还可以对隐藏层的输出值进行归一化,从而加速梯度下降的收敛速度呢?答案是可以的。
3.Batch Norm,即基于mini-batch gradient descent的归一化,将其应用于深层神经网络。
二..归一化网络的激活函数
1.一般地,我们并非对a[0](a[0]即输入值X)、a[1]、a[2]……等进行归一化,而是对z[1]、z[2]……等进行归一化(没有z[0])。
2.对于第l层的某个batch数据,计算出z[l]的均值和方差,然后对其进行归一化,使其均值为0,方差为1:
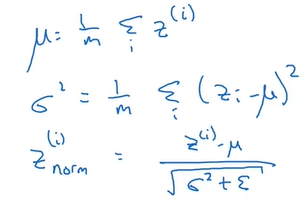 (注意,z的上标i表示数据,而非层数。在课程中层数使用中括号[],这里不标示层数是为了简便。)
(注意,z的上标i表示数据,而非层数。在课程中层数使用中括号[],这里不标示层数是为了简便。)
3.但是,我们不总希望隐藏单元总是含有均值为0,方差为1,也许隐藏单元有了不同的分布会有意义。(这里没能想明白,大概的意思是:如果总是“均值为0,方差为1”,那么深层神经网络的表示能力就减弱。)所以就再对其进行缩放和平移:

其中,β、γ是需要学习的参数。所以总的来说,需要学习四类参数:w、b、β、γ。
三.Batch Norm拟合进神经网络
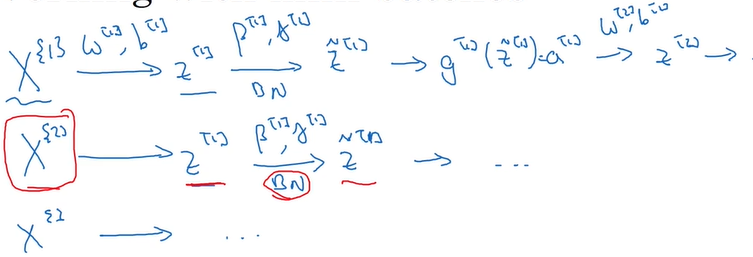
1.在一次梯度下降中(用的batch可能不同),z[1]、z[2]……的均值和方差可能一直在变化,所以对于第l层,需要重新计算z[l]的均值和方差,然后再对其归一化
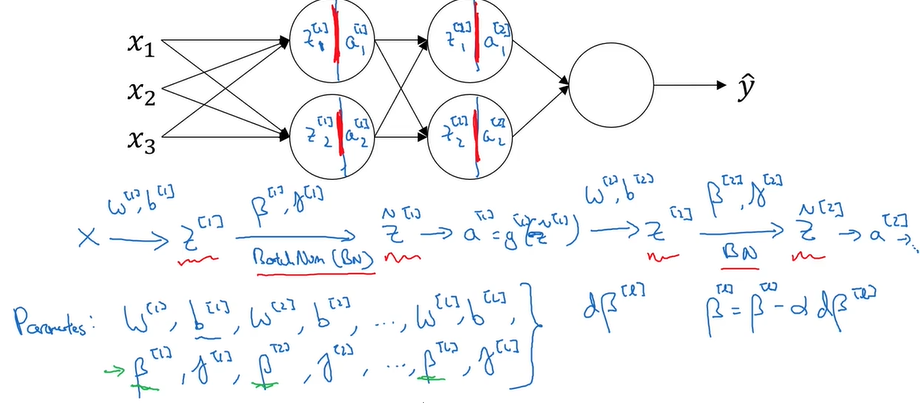
2.当进行了一次梯度下降之后,就利用下一个batch继续梯度下降(大括号标示batch):
四.测试时的Batch Norm
由于每一层中z的均值和方差在每一次梯度下降时都是变化的(与平常的机器学习的不同,机器学习中只需对输入数据X进行归一化,X的均值和方差是恒定的),所以在测试时,用哪个均值和方差进行归一化就成了一个问题。
解决方法是:在训练的过程中,利用指数加权平均去追踪和计算,最终得到用于测试数据的均值和方差。
吴恩达深度学习笔记(七) —— Batch Normalization的更多相关文章
- 【Deeplearning.ai 】吴恩达深度学习笔记及课后作业目录
吴恩达深度学习课程的课堂笔记以及课后作业 代码下载:https://github.com/douzujun/Deep-Learning-Coursera 吴恩达推荐笔记:https://mp.weix ...
- 吴恩达深度学习笔记(八) —— ResNets残差网络
(很好的博客:残差网络ResNet笔记) 主要内容: 一.深层神经网络的优点和缺陷 二.残差网络的引入 三.残差网络的可行性 四.identity block 和 convolutional bloc ...
- 吴恩达深度学习笔记(十二)—— Batch Normalization
主要内容: 一.Normalizing activations in a network 二.Fitting Batch Norm in a neural network 三.Why does ...
- 吴恩达深度学习笔记(deeplearning.ai)之卷积神经网络(二)
经典网络 LeNet-5 AlexNet VGG Ng介绍了上述三个在计算机视觉中的经典网络.网络深度逐渐增加,训练的参数数量也骤增.AlexNet大约6000万参数,VGG大约上亿参数. 从中我们可 ...
- 吴恩达深度学习笔记(deeplearning.ai)之卷积神经网络(CNN)(上)
作者:szx_spark 1. Padding 在卷积操作中,过滤器(又称核)的大小通常为奇数,如3x3,5x5.这样的好处有两点: 在特征图(二维卷积)中就会存在一个中心像素点.有一个中心像素点会十 ...
- 吴恩达深度学习笔记(deeplearning.ai)之循环神经网络(RNN)(三)
1. 导读 本节内容介绍普通RNN的弊端,从而引入各种变体RNN,主要讲述GRU与LSTM的工作原理. 事先声明,本人采用ng在课堂上所使用的符号系统,与某些学术文献上的命名有所不同,不过核心思想都是 ...
- 吴恩达深度学习笔记(五) —— 优化算法:Mini-Batch GD、Momentum、RMSprop、Adam、学习率衰减
主要内容: 一.Mini-Batch Gradient descent 二.Momentum 四.RMSprop 五.Adam 六.优化算法性能比较 七.学习率衰减 一.Mini-Batch Grad ...
- 吴恩达深度学习笔记(deeplearning.ai)之卷积神经网络(一)
Padding 在卷积操作中,过滤器(又称核)的大小通常为奇数,如3x3,5x5.这样的好处有两点: 在特征图(二维卷积)中就会存在一个中心像素点.有一个中心像素点会十分方便,便于指出过滤器的位置. ...
- 吴恩达深度学习笔记1-神经网络的编程基础(Basics of Neural Network programming)
一:二分类(Binary Classification) 逻辑回归是一个用于二分类(binary classification)的算法.在二分类问题中,我们的目标就是习得一个分类器,它以对象的特征向量 ...
随机推荐
- OpenCV学习笔记一:OpenCV概览与配置编译
一,OpenCV OpenCV官方网站:http://opencv.org/ OpenCV目前最新代码库地址:https://github.com/itseez/opencv 二,简介: OpenC ...
- 使用PHP函数输出前一天的时间和后一天的时间
1.明确date()函数和time()函数的功能,其中time()函数是获取时间戳函数 2.输出前一天的当前时间: echo '一天之前的时间为:'.date('Y-m-d H:i:s',time() ...
- Android开发:《Gradle Recipes for Android》阅读笔记1.1
第一章1.1节 注:下面都是用android studio新建出来的默认项目配置,没有修改 1.settings.gradle记录了哪些子目录包含了它们自己的工程,例如:include':app',如 ...
- zoj 3349 dp + 线段树优化
题目:给出一个序列,找出一个最长的子序列,相邻的两个数的差在d以内. /* 线段树优化dp dp[i]表示前i个数的最长为多少,则dp[i]=max(dp[j]+1) abs(a[i]-a[j])&l ...
- 【BZOJ4817】[Sdoi2017]树点涂色 LCT+线段树
[BZOJ4817][Sdoi2017]树点涂色 Description Bob有一棵n个点的有根树,其中1号点是根节点.Bob在每个点上涂了颜色,并且每个点上的颜色不同.定义一条路径的权值是:这条路 ...
- JavaScript处理数据完成左侧二级菜单的搭建
我们在项目中应用的后台管理框架基本上都是大同小异,左侧是一个二级菜单,点击选中的菜单,右侧对应的页面展示.我把前端页面封装数据的过程整理了一下,虽然不一定适合所有的管理页面,仅作为案例来参考,只是希望 ...
- 简述Python的深浅拷贝以及应用场景
深浅拷贝的原理 深浅拷贝用法来自copy模块. 导入模块:import copy 浅拷贝:copy.copy 深拷贝:copy.deepcopy 字面理解:浅拷贝指仅仅拷贝数据集合的第一层数据,深拷贝 ...
- Linux中权限管理之ACL权限
1.简介: a.作用: 是为了防止权限不够用的情况,一般的权限有所有者.所属组.其他人这三种,当这三种满足不了我们的需求的时候就可以使用ACL权限 b.故事背景: 一个老师,给一个班的学员上课,他在l ...
- requirejs神奇问题,data-main修改后,刷新没有重新载入
同事在使用require的时候,在配置地方增加 urlArgs: "bust=" + (new Date()).getTime(), 然后问题又来了,这个相当于js版本的东东会把 ...
- 软件工作考核项(zcl)——
注意:这里没有对代码风格做要求,因为要代码走查! 考核项 考核标准 分数等级 需求规格说明书编写 主要用例图缺失 -1 主要软件界面设计图缺失 -1 主要功能清单项目缺失 -1 主要复 ...