吴恩达深度学习笔记(七) —— Batch Normalization
主要内容:
一.Batch Norm简介
二.归一化网络的激活函数
三.Batch Norm拟合进神经网络
四.测试时的Batch Norm
一.Batch Norm简介
1.在机器学习中,我们一般会对输入数据进行归一化处理,使得各个特征的数值规模处于同一个量级,有助于加速梯度下降的收敛过程。
2.在深层神经网络中,容易出现梯度小时或者梯度爆炸的情况,导致训练速度慢。那么,除了对输入数据X进行归一化之外,我们是否还可以对隐藏层的输出值进行归一化,从而加速梯度下降的收敛速度呢?答案是可以的。
3.Batch Norm,即基于mini-batch gradient descent的归一化,将其应用于深层神经网络。
二..归一化网络的激活函数
1.一般地,我们并非对a[0](a[0]即输入值X)、a[1]、a[2]……等进行归一化,而是对z[1]、z[2]……等进行归一化(没有z[0])。
2.对于第l层的某个batch数据,计算出z[l]的均值和方差,然后对其进行归一化,使其均值为0,方差为1:
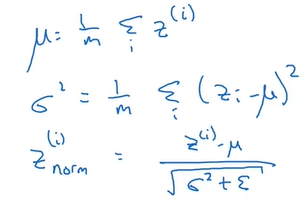 (注意,z的上标i表示数据,而非层数。在课程中层数使用中括号[],这里不标示层数是为了简便。)
(注意,z的上标i表示数据,而非层数。在课程中层数使用中括号[],这里不标示层数是为了简便。)
3.但是,我们不总希望隐藏单元总是含有均值为0,方差为1,也许隐藏单元有了不同的分布会有意义。(这里没能想明白,大概的意思是:如果总是“均值为0,方差为1”,那么深层神经网络的表示能力就减弱。)所以就再对其进行缩放和平移:

其中,β、γ是需要学习的参数。所以总的来说,需要学习四类参数:w、b、β、γ。
三.Batch Norm拟合进神经网络
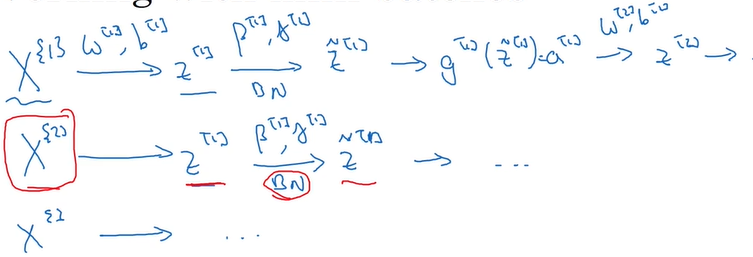
1.在一次梯度下降中(用的batch可能不同),z[1]、z[2]……的均值和方差可能一直在变化,所以对于第l层,需要重新计算z[l]的均值和方差,然后再对其归一化
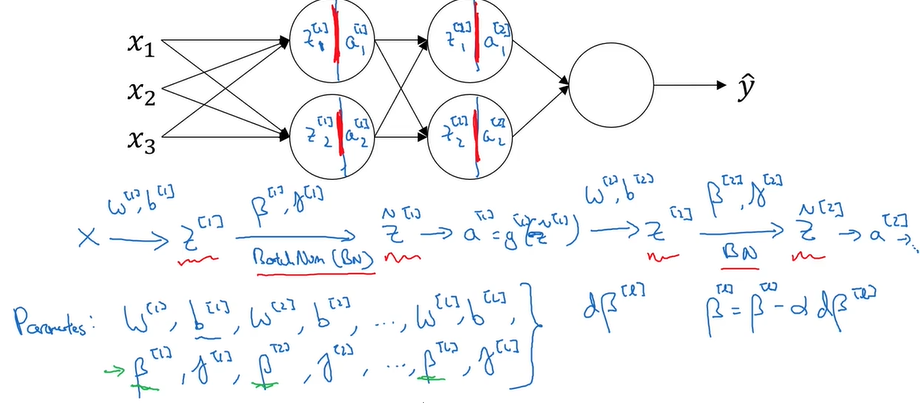
2.当进行了一次梯度下降之后,就利用下一个batch继续梯度下降(大括号标示batch):
四.测试时的Batch Norm
由于每一层中z的均值和方差在每一次梯度下降时都是变化的(与平常的机器学习的不同,机器学习中只需对输入数据X进行归一化,X的均值和方差是恒定的),所以在测试时,用哪个均值和方差进行归一化就成了一个问题。
解决方法是:在训练的过程中,利用指数加权平均去追踪和计算,最终得到用于测试数据的均值和方差。
吴恩达深度学习笔记(七) —— Batch Normalization的更多相关文章
- 【Deeplearning.ai 】吴恩达深度学习笔记及课后作业目录
吴恩达深度学习课程的课堂笔记以及课后作业 代码下载:https://github.com/douzujun/Deep-Learning-Coursera 吴恩达推荐笔记:https://mp.weix ...
- 吴恩达深度学习笔记(八) —— ResNets残差网络
(很好的博客:残差网络ResNet笔记) 主要内容: 一.深层神经网络的优点和缺陷 二.残差网络的引入 三.残差网络的可行性 四.identity block 和 convolutional bloc ...
- 吴恩达深度学习笔记(十二)—— Batch Normalization
主要内容: 一.Normalizing activations in a network 二.Fitting Batch Norm in a neural network 三.Why does ...
- 吴恩达深度学习笔记(deeplearning.ai)之卷积神经网络(二)
经典网络 LeNet-5 AlexNet VGG Ng介绍了上述三个在计算机视觉中的经典网络.网络深度逐渐增加,训练的参数数量也骤增.AlexNet大约6000万参数,VGG大约上亿参数. 从中我们可 ...
- 吴恩达深度学习笔记(deeplearning.ai)之卷积神经网络(CNN)(上)
作者:szx_spark 1. Padding 在卷积操作中,过滤器(又称核)的大小通常为奇数,如3x3,5x5.这样的好处有两点: 在特征图(二维卷积)中就会存在一个中心像素点.有一个中心像素点会十 ...
- 吴恩达深度学习笔记(deeplearning.ai)之循环神经网络(RNN)(三)
1. 导读 本节内容介绍普通RNN的弊端,从而引入各种变体RNN,主要讲述GRU与LSTM的工作原理. 事先声明,本人采用ng在课堂上所使用的符号系统,与某些学术文献上的命名有所不同,不过核心思想都是 ...
- 吴恩达深度学习笔记(五) —— 优化算法:Mini-Batch GD、Momentum、RMSprop、Adam、学习率衰减
主要内容: 一.Mini-Batch Gradient descent 二.Momentum 四.RMSprop 五.Adam 六.优化算法性能比较 七.学习率衰减 一.Mini-Batch Grad ...
- 吴恩达深度学习笔记(deeplearning.ai)之卷积神经网络(一)
Padding 在卷积操作中,过滤器(又称核)的大小通常为奇数,如3x3,5x5.这样的好处有两点: 在特征图(二维卷积)中就会存在一个中心像素点.有一个中心像素点会十分方便,便于指出过滤器的位置. ...
- 吴恩达深度学习笔记1-神经网络的编程基础(Basics of Neural Network programming)
一:二分类(Binary Classification) 逻辑回归是一个用于二分类(binary classification)的算法.在二分类问题中,我们的目标就是习得一个分类器,它以对象的特征向量 ...
随机推荐
- Apache的下载以及安装
前言:生活,生下来,活下去 第一步:在浏览器的搜索栏输入:apache下载:显示如下,单机进入Apache的官网
- 转:: 刺鸟:用python来开发webgame服务端(3)
来源:http://ciniao.me/article.php?id=11 --------------- 刺鸟原创文章,转载请注明出处 在之前的准备工作中,我们已经建立了一个socket服务器 ...
- X明X源面试题《三》
本文转自自zhangxh_Doris 昨天(05.23)下午去参加了明源软件的暑期实习宣讲+笔试,第一次听说这个行业,行业和笔试风格完全不一样啊,5道行测智力题+1个问答+ 斐波那契数列 + 洗牌算法 ...
- P2424 约数和
题目背景 Smart最近沉迷于对约数的研究中. 题目描述 对于一个数X,函数f(X)表示X所有约数的和.例如:f(6)=1+2+3+6=12.对于一个X,Smart可以很快的算出f(X).现在的问题是 ...
- 第五课 nodejs 路由实现并处理请求作出响应
1创建一个http Server 文件server.js var http = require('http');var url = require('url');function start(rout ...
- MySQL中因为unique key 非空唯一索引存在导致修改主键失败案例
研发在早期的设计中,由于设计方面的问题,导致在设计表结构的时候,有个表有非空唯一索引而没有主键 在InnoDB存储引擎中,如果没有主键的情况下,有非空唯一索引的话,非空唯一索引即为主键. 那么这就会有 ...
- linux下查看cpu,内存,硬盘等硬件信息的方法
说明:Linux下可以在/proc/cpuinfo中看到每个cpu的详细信息.但是对于双核的cpu,在cpuinfo中会看到两个cpu.常常会让人误以为是两个单核的cpu. 一.linux CPU大小 ...
- 0x07 MySQL 多表查询
Some Content From——Egon's Blog http://www.cnblogs.com/linhaifeng/articles/7126847.html 一 准备表 准备表 #建表 ...
- Python——用正则求时间差
如有求时间差的需求,可直接套用此方法: import time true_time=time.mktime(time.strptime('2017-09-11 08:30:00','%Y-%m-%d ...
- Linux中的输出重定向
标准输入输出: 键盘 /dev/stdin 0 标准输入 显示器 /dev/stdout 1 标准输出 显示器 /dev/st ...