爬取编程常用词汇,保存为Excel
编程常用词汇
import requests
import openpyxl
from lxml import etree
import re
url = 'https://www.runoob.com/w3cnote/common-english-terminology-in-programming.html'
# 得到响应结果
res = requests.get(url)
# xpath取值
selector = etree.HTML(res.text)
# 字母的索引
word_letter = selector.xpath('//h2/text()')
# 删除列表里前两个多余的值
del word_letter[0:2]
# print(word_letter)
# word_letter 最后的值为
# ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '专业名词']
# 得到每个索引的table,每个table里包含各索引的所有单词
result = selector.xpath('//table')
# 删除多余的数据
result.pop(0)
# 创建workbook
wb = openpyxl.Workbook()
# 创建worksheet
ws = wb.active
# 利用下标取出词汇的索引
index = -1
for table in result:
# 一开始就进行计数,即从0开始
index += 1
# 先添加索引,再取出每个table里的所有单词
ws.append([word_letter[index]])
# 打印索引
print(word_letter[index])
# X索引里没有单词
if word_letter[index] == 'X':
# 每个字母索引之间空一行
ws.append([])
# 继续循环对后面table里的单词进行添加
continue
# 添加一行Excel数据
ws.append(['英文', '译法 1', '译法 2', '译法 3'])
# 将Element类型显示为字符,为byte类型,需要decode
# 中文不显示,需要设置 encoding='utf-8'
words_html = etree.tostring(table, encoding='utf-8').decode()
# 一个tr:单词和译法
# 利用正则得到一个table里所有tr的内容
word_html = re.findall('<tr>.*?</tr>', words_html, re.S)
# 删除带<strong>标签的'英文 译法1 译法2 译法3'这条数据
# 前面已经手动添加,后面不需要每条都去判断去除<strong>标签
word_html.pop(0)
for tr in word_html:
# 一个td:一个单词或一个译法
# 利用正则得到一个tr里所有td的内容
# 得到的为list,一个td_list里面包含一个单词和对应的译文(含空格)
td_list = re.findall('<td>(.*?)</td>', tr, re.S)
# 用新的列表接收去除空格后的单词和译文
word = []
for i in td_list:
# 去除每个td里包含的空格,添加为一个列表
word.append(i.strip())
# 打印单词
print(word)
# 一个word包含一个单词和对应的译文(不含空格)
# 将这个单词添加进Excel
ws.append(word)
# 每个字母索引之间空一行
ws.append([])
# 保存Excel
path = r'C:\Users\Hlzy\Desktop\编程常用词汇.xlsx'
wb.save(path)
# 没有设置单元格样式,可以直接打开Excel,设置边宽,全选居中
控制台打印
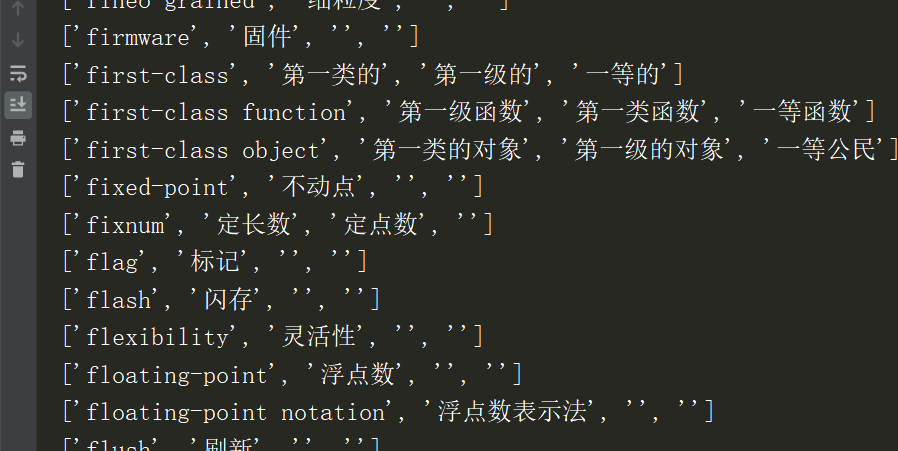
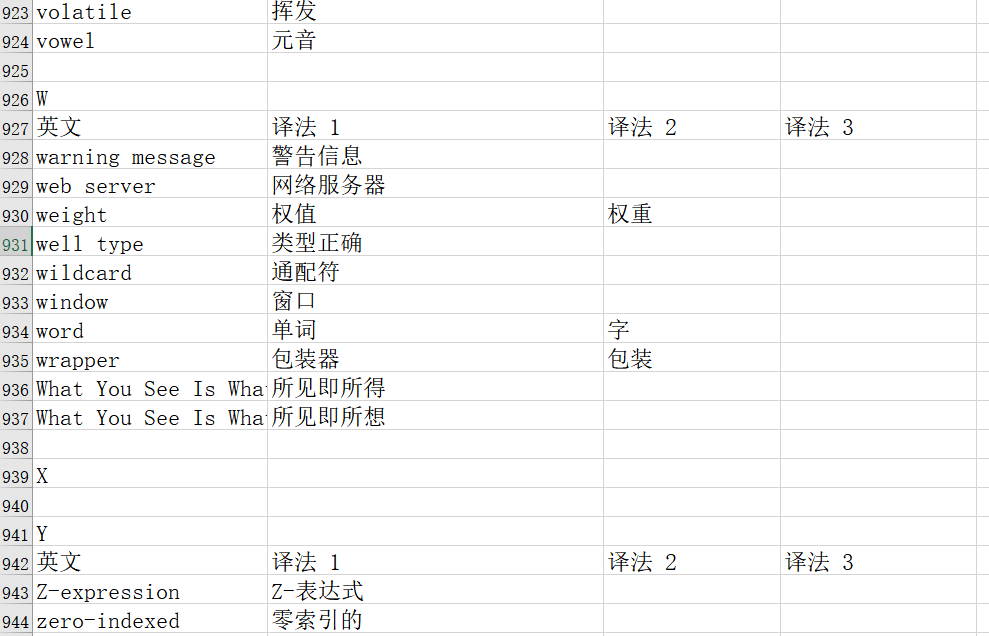
Excel内容
提取链接:https://pan.baidu.com/s/11kQnMQU_ilOtgf4Mom0nhw
爬取编程常用词汇,保存为Excel的更多相关文章
- VBA编程常用词汇英汉对照表
表 20‑1到表 20‑8是VBA编程中使用频率最高的英文单词,按字母排序.词性列中,a表示形容词,n表示名词,v表示动词,p表示介词以及其他词性. 表 20‑1 VBA编程常用词汇表 单词 中文 词 ...
- Python:爬取网站图片并保存至本地
Python:爬取网页图片并保存至本地 python3爬取网页中的图片到本地的过程如下: 1.爬取网页 2.获取图片地址 3.爬取图片内容并保存到本地 实例:爬取百度贴吧首页图片. 代码如下: imp ...
- Python爬虫学习(二) ——————爬取前程无忧招聘信息并写入excel
作为一名Pythoner,相信大家对Python的就业前景或多或少会有一些关注.索性我们就写一个爬虫去获取一些我们需要的信息,今天我们要爬取的是前程无忧!说干就干!进入到前程无忧的官网,输入关键字&q ...
- pyhton 网络爬取软考题库保存text
#-*-coding:utf-8-*-#参考文档#https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#find-al ...
- Python爬取拉勾网招聘信息并写入Excel
这个是我想爬取的链接:http://www.lagou.com/zhaopin/Python/?labelWords=label 页面显示如下: 在Chrome浏览器中审查元素,找到对应的链接: 然后 ...
- Python-爬虫实战 简单爬取豆瓣top250电影保存到本地
爬虫原理 发送数据 获取数据 解析数据 保存数据 requests请求库 res = requests.get(url="目标网站地址") 获取二进制流方法:res.content ...
- Python使用requests爬取一个网页并保存
#导入 requests模块import requests #设置请求头,让网站监测是浏览器 headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 6. ...
- 将爬取的网页数据保存到数据库时报错不能提交JPA,Caused by: java.sql.SQLException: Incorrect string value: '\xF0\x9F\x98\xB6 \xE2...' for column 'content' at row 1
错误原因:我们可以看到错误提示中的字符0xF0 0x9F 0x98 0x84 ,这对应UTF-8编码格式中的4字节编码(UTF-8编码规范).正常的汉字一般不会超过3个字节,为什么为出现4个字节呢?实 ...
- 爬取豆瓣电影信息保存到Excel
from bs4 import BeautifulSoup import requests import html.parser from openpyxl import Workbook,load_ ...
随机推荐
- canvas的介绍
1.我们前端的绘图技术有哪些: 统计图表:echarts 实时走势图:canvas: 在线画板:魔猴: HTML5游戏:three.js 2.我这里主要讲的是canvas绘图: <canvas& ...
- 【zabbix监控】zabbix监控tomcat服务
服务器配置(zabbix_server) 1. 安装jdk 版本需要1.7以上,我这边安装的是1.8的,可以参考我jdk安装的文章 # 上传到zabbix_server服务端.安装(jdk-8u171 ...
- Flutter - flutter desktop embedding / flutter 桌面支持
2019年5月9日,随着谷歌在IO19宣布Flutter支持Web平台,就标志着Flutter已经全面支持所有平台(移动.网页.桌面.嵌入式). 现编一个跨平台小段子: 微软Xarmarin:喵喵喵? ...
- 一个随机切换user_agent的第三方python库:my_fake_useragent
因为my_fake_useragent 是第三方,所以需要自己进行安装. 不用担心,它没有任何依赖或者附加环境,只安装它自己就行. 方法1: pycharm传统安装方式. 方法2: pip insta ...
- How to: Apply Attributes to Entity Properties when Using Model First 如何:在ModelFirst时将属性应用于实体属性
In a Model First data model, object properties are declared in the designer-generated files, and you ...
- 【转载】C#中decimal保留2位有效小数
在C#的数字运算过程中,有时候针对十进制decimal类型的计算需要保留2位有效小数,针对decimal变量保留2位有效小数有多种方法,可以使用Math.Round方法以及ToString先转换为字符 ...
- 搭建ES集群
服务版本选择 TEG的ctsdb当前最高版本采用的是es的6.4.3版本,为了日后与ctsdb衔接方便,部署开源版es时也采用该版本.6.4.3版本的es依赖的jdk版本要求在8u181以上,测试环境 ...
- windows中常见后门持久化方法总结
转自:https://www.heibai.org/category-13.html 前言 当我们通过各种方法拿到一个服务器的权限的时候,我们下一步要做的就是后渗透了,而后门持久化也是我们后渗透很重要 ...
- arcgis api for javascript 学习(一) 调用在线发布的动态地图
1.图中显示为arcgis软件中显示的地图文件 2.调用动态地图主要的是知道动态地图的URL地址 3.通过IDE(webstorm)调用动态地图,如图 4.话不多说,直接上代码 <!DOCTYP ...
- Android app targetSdk升级到27碰到的一个bug补充说明
版权声明:本文为xing_star原创文章,转载请注明出处! 本文同步自http://javaexception.com/archives/203 完美解决google nexus设备全面屏主题cra ...