大数据平台搭建 - cdh5.11.1 - hive客户端安装
一、简介
hive是基于hadoop的一种数据仓库工具,可以将结构化的文件映射成为数据库的一张表,并提供简单sql查询功能,底层实现是转化为MapReduce任务计算。
二、安装
(1)下载
从cdh下载页下载
http://archive.cloudera.com/cdh5/cdh/5/
hive-1.1.0-cdh5.11.1.tar.gz
下载好后上传至服务器的/home/hadoop/software,并解压至/home/hadoop/app目录下
mv hive-1.1.0-cdh5.11.1.tar.gz hive
(2)配置
配置hive-env.sh(在hive主目录下的conf文件夹下)
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/home/hadoop/app/hadoop # Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/home/hadoop/app/hive/conf
配置hive-site.xml
由于hive中的元数据(即所有的数据库信息、表信息、及表字段信息)需要存储在关系型数据库中,而hive内置了derby数据库,但是使用这个数据库的缺点是,
hive提供的hiveserver2只能一个用户访问,所以需要配置mysql,使元数据存储在mysql上
(3)安装mysql
安装mysql很容易,使用yum安装即可
首先卸载已经有的mysql
sudo rpa -qa|grep mysql
sudo yum remove ...
sudo rm -rf /etc/my.conf
安装:
sudo yum install mysql mysql-server mysql-devel -y
安装完成后,设置为跟随机器启动
chkconfig mysqld on
启动mysql服务
service mysqld start
设置mysql密码
(一开始安装好后,密码为空直接进去即可)
mysql -uroot -p
进去命令行之后,设置密码
SET PASSWORD=PASSWORD("123456")
设置所有用户都可以用root用户连接进来
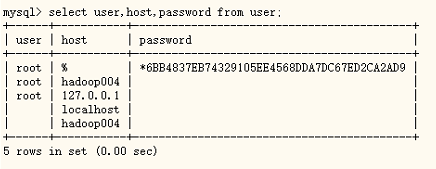
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop001:3306/metastore_new?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property> <property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property> <property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property> <property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property> <property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop001</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop001:9083</value>
</property>
</configuration>
(5)下载mysql驱动包到hive的lib目录下
(6)bin/hive
即可打开命令行
大数据平台搭建 - cdh5.11.1 - hive客户端安装的更多相关文章
- 大数据平台搭建 - cdh5.11.1 - hadoop集群安装
一.前言 由于线下测试的需要,需要在公司线下(测试)环境搭建大数据集群. 那么CDH是什么? hadoop是一个开源项目,所以很多公司再这个基础上进行商业化,不收费的hadoop版本主要有三个,分别是 ...
- 大数据平台搭建 - cdh5.11.1 - hue安装及集成其他组件
一.简介 hue是一个开源的apache hadoop ui系统,由cloudear desktop演化而来,最后cloudera公司将其贡献给了apache基金会的hadoop社区,它基于pytho ...
- 大数据平台搭建 - cdh5.11.1 - hbase集群搭建
一.简介 HBase是一种构建在HDFS之上的分布式.面向列的存储系统.在需要实时读写.随机访问超大规模数据集时,可以使用HBase. 尽管已经有许多数据存储和访问的策略和实现方法,但事实上大多数解决 ...
- 大数据平台搭建 - cdh5.11.1 - oozie安装
一.简介 oozie是hadoop平台开源的工作流调度引擎,用来管理hadoop作业,属于web应用程序,由oozie server 和oozie client构成. oozie server运行与t ...
- 大数据平台搭建 - cdh5.11.1 - spark源码编译及集群搭建
一.spark简介 Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎,Spark 是一种与 hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同 ...
- 大数据平台搭建 - Mysql在linux上的安装
一.简介 MySQL是一个关系型数据库系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下产品.MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 ...
- 大数据平台搭建(hadoop+spark)
大数据平台搭建(hadoop+spark) 一.基本信息 1. 服务器基本信息 主机名 ip地址 安装服务 spark-master 172.16.200.81 jdk.hadoop.spark.sc ...
- CDH构建大数据平台-使用自建的镜像地址安装Cloudera Manager
CDH构建大数据平台-使用自建的镜像地址安装Cloudera Manager 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.搭建CM私有仓库 详情请参考我的笔记: http ...
- product of大数据平台搭建------CM 和CDH安装
一.安装说明 CM是由cloudera公司提供的大数据组件自动部署和监控管理工具,相应的和CDH是cloudera公司在开源的hadoop社区版的基础上做了商业化的封装的大数据平台. 采用离线安装模式 ...
随机推荐
- 编程使用c#连接到IBM db2的两种方式
一:使用c#通过odbc连接到IBM db2使用 ConnectionString 属性连接到各种数据源. 部署:只要在客户端安装IBM DB2 ODBC driver.配置DSn即可. 1):可以单 ...
- (十一)c#Winform自定义控件-列表
前提 入行已经7,8年了,一直想做一套漂亮点的自定义控件,于是就有了本系列文章. 开源地址:https://gitee.com/kwwwvagaa/net_winform_custom_control ...
- 快速了解Python并发编程的工程实现(下)
关于我 一个有思想的程序猿,终身学习实践者,目前在一个创业团队任team lead,技术栈涉及Android.Python.Java和Go,这个也是我们团队的主要技术栈. Github:https:/ ...
- random库的使用
一.random库介绍 random库是使用随机数的Python标准库 伪随机数:采用梅森旋转算法生成的(伪)随机序列中元素 random库主要用于生成随机数 使用random库:import ran ...
- windows下 ionic 打包app --以安卓版本为例
环境安装 1.nodejs 安装版本5.7,尽量不要安装太新的版本,因为可能会出现兼容性问题,一开始本人安装的是6.+的版本,后来出现问题的,马上换回5.7的,问题就不会出现了. 安装教程网上教程很多 ...
- 《Java 8 in Action》Chapter 9:默认方法
传统上,Java程序的接口是将相关方法按照约定组合到一起的方式.实现接口的类必须为接口中定义的每个方法提供一个实现,或者从父类中继承它的实现. 但是,一旦类库的设计者需要更新接口,向其中加入新的方法, ...
- 基于springboot的websocket聊天室
WebSocket入门 1.概述 1.1 Http #http简介 HTTP是一个应用层协议,无状态的,端口号为80.主要的版本有1.0/1.1/2.0. #http1.0/1.1/2.0 1.HTT ...
- 一、mysql数据库,忘记密码怎么处理及处理过程中遇见的问题
1.输入cmd命令打开控制台: 2.进入mysql.exe所在的路径: 3.执行mysqld --skip-grant-tables(注意:在输入此命令之前先在任务管理器中结束mysqld.exe进程 ...
- evevt
EventEvent 是一个事件对象,当一个事件发生后,和当前事件发生相关的详细信息会被临时存储到一个指定的地方,也就是event对象,以方便我们在需要的时候调用. 在这一点上,非常类似于飞机当中的黑 ...
- HTML连载34-背景关联和缩写以及插图图片和背景图片的区别
一.背景属性缩写的格式 1.backgound:背景颜色 背景图片 平铺方式 关联方式 定位方式 2.注意点: 这里的所有值都可以省略,但是至少需要一个 3.什么是背景关联方式 默认情况下,背 ...