复杂模型可解释性方法——LIME
一、模型可解释性
近年来,机器学习(深度学习)取得了一系列骄人战绩,但是其模型的深度和复杂度远远超出了人类理解的范畴,或者称之为黑盒(机器是否同样不能理解?),当一个机器学习模型泛化性能很好时,我们可以通过交叉验证验证其准确性,并将其应用在生产环境中,但是很难去解释这个模型为什么会做出此种预测,是基于什么样的考虑?作为机器学习从业者很容易想清楚为什么有些模型存在性别歧视、种族歧视和民族仇恨言论(训练样本的问题),但是很多场景下我们需要向模型使用方作出解释,让其清楚模型为什么要做出此种预测,如模型替代医生判断病情,给出病人合理的解释至关重要,在商业场景中,模型为公司做出决策,需要给出令管理层信服的解释。另外,给出解释也可以帮助我们进一步改善模型,优化特征,提高泛化性。
本文就LIME( Local Interpretable Model-Agnostic Explanations, LIME)方法如何解释黑盒模型作出简要的介绍和公式推导,介绍其优缺点,文末附上自己的一些简单思考
二、 LIME
LIME的主要思想是利用可解释性模型(如线性模型,决策树)局部近似目标黑盒模型的预测,此方法不深入模型内部,通过对输入进行轻微的扰动,探测黑盒模型的输出发生何种变化,根据这种变化在兴趣点(原始输入)训练一个可解释性模型。值得注意的是,可解释性模型是黑盒模型的局部近似,而不是全局近似,这也是其名字的由来。
LIME的数学表示如下:
\[
explanation(x)=arg\min_{g\in G}L(f,g,\pi_x)+\Omega(g)
\]
对于实例\(x\)的解释模型\(g\),我们通过最小化损失函数来比较模型\(g\)和原模型\(f\)的近似性,其中,\(\Omega (g)\)代表了解释模型\(g\)的模型复杂度,\(G\)表示所有可能的解释模型(例如我们想用线性模型解释,则\(G\)表示所有的线性模型),\(\pi_{x}\) 定义了\(x\)的邻域。我们通过最小化\(L\)使得模型\(f\)变得可解释。其中,模型\(g\),邻域范围大小,模型复杂度均需要定义。
下面对于结构化数据类型,简要说明LIME的工作流程。
对于结构化数据,首先确定可解释性模型,兴趣点x,邻域的范围。LIME首先在全局进行采样,然后对于所有采样点,选出兴趣点x的邻域,然后利用兴趣点的邻域范围拟合可解释性模型。如下图\(^1\)
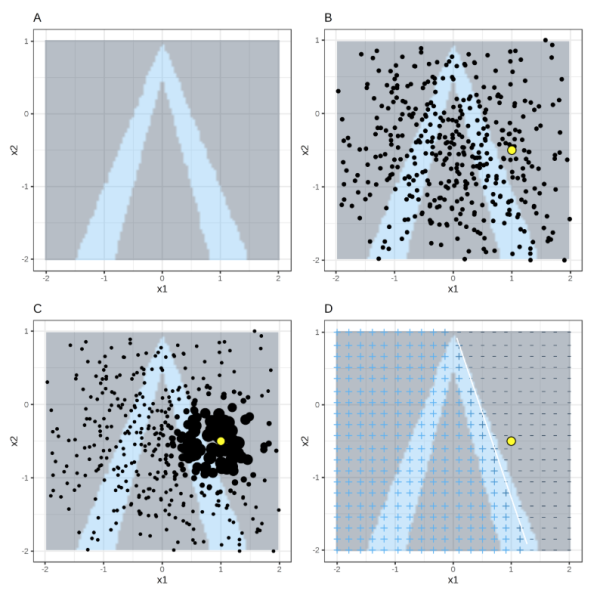
其中,背景灰色为负例,背景蓝色为正例,黄色为兴趣点,小粒度黑色点为采样点,大粒度黑点为邻域范围,右下图为LIME的结果。
LIME的优点我们很容易就可以看到,原理简单,适用范围广,可解释任何黑箱模型。但是在实际应用中,存在几个问题:
- 需要确定邻域范围;邻域范围不同,得到的局部可解释性模型可能会有很大的差别,如下图
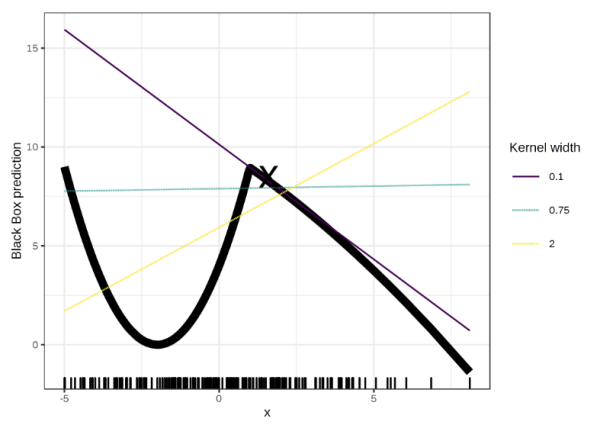
对于x=1.6,不同的邻域范围(0.1,0.75,2)对应的可解释性模型是完全不同的,甚至相悖。
采样是全样本集采样,采样是利用高斯分布进行采样,忽略了特征之间的关系,这可能导致一些不大可能出现的样本点来解释模型。
解释模型的复杂度需要提前定义。
解释的不稳定性。利用相同参数相同方法进行的重复解释,得到的结果可能完全不同.\(^5\)
三、总结
模型可解释性作为目前机器学习领域研究的热门,LIME的成果是很有启发性的,通过对黑盒模型某局部点的无限次探测,拟合出一个局部可解释性的简单模型。但是其缺点同样明显,这些缺点也导致了LIME方法难以大规模应用。
后续将介绍基于Shapley值的SHAP方法(现在在研读,就是有点看不懂。看懂了再写)
参考链接:
- https://christophm.github.io/interpretable-ml-book/lime.html
- https://blog.csdn.net/a358463121/article/details/52313585
- https://cloud.tencent.com/developer/article/1096716
- 论文地址:https://arxiv.org/pdf/1602.04938v1.pdf
Alvarez-Melis, David, and Tommi S. Jaakkola. “On the robustness of interpretability methods.” arXiv preprint arXiv:1806.08049 (2018).)
本文由飞剑客原创,如需转载,请联系私信联系知乎:@AndyChanCD
复杂模型可解释性方法——LIME的更多相关文章
- NNs(Neural Networks,神经网络)和Polynomial Regression(多项式回归)等价性之思考,以及深度模型可解释性原理研究与案例
1. Main Point 0x1:行文框架 第二章:我们会分别介绍NNs神经网络和PR多项式回归各自的定义和应用场景. 第三章:讨论NNs和PR在数学公式上的等价性,NNs和PR是两个等价的理论方法 ...
- 基于 Koa平台Node.js开发的KoaHub.js的控制器,模型,帮助方法自动加载
koahub-loader koahub-loader是基于 Koa平台Node.js开发的KoaHub.js的koahub-loader控制器,模型,帮助方法自动加载 koahub loader I ...
- 评价指标的局限性、ROC曲线、余弦距离、A/B测试、模型评估的方法、超参数调优、过拟合与欠拟合
1.评价指标的局限性 问题1 准确性的局限性 准确率是分类问题中最简单也是最直观的评价指标,但存在明显的缺陷.比如,当负样本占99%时,分类器把所有样本都预测为负样本也可以获得99%的准确率.所以,当 ...
- thinkphp模型中的获取器和修改器(根据字段名自动调用模型中的方法)
thinkphp模型中的获取器和修改器(根据字段名自动调用模型中的方法) 一.总结 记得看下面 1.获取器的作用是在获取数据的字段值后自动进行处理 2.修改器的作用是可以在数据赋值的时候自动进行转换处 ...
- 深度学习模型调优方法(Deep Learning学习记录)
深度学习模型的调优,首先需要对各方面进行评估,主要包括定义函数.模型在训练集和测试集拟合效果.交叉验证.激活函数和优化算法的选择等. 那如何对我们自己的模型进行判断呢?——通过模型训练跑代码,我们可以 ...
- ASP.NET MVC中的模型装配 封装方法 非常好用
下面说一下 我们知道在asp.net mvc中 视图可以绑定一个实体模型 然后我们三层架构中也有一个model模型 但是这两个很多时候却是不一样的对象来的 就拿微软的官方mvc例子来说明 微软的视图实 ...
- PRML读书会第三章 Linear Models for Regression(线性基函数模型、正则化方法、贝叶斯线性回归等)
主讲人 planktonli planktonli(1027753147) 18:58:12 大家好,我负责给大家讲讲 PRML的第3讲 linear regression的内容,请大家多多指教,群 ...
- sklearn中树模型可视化的方法
在机器学习的过程中,我们常常会用到树模型的方式来解决我们的问题.在工业界,我们不仅要针对某个问题利用机器学习的方法来解决问题,而且还需要能力解释其中的原理或原因.今天主要在这里记录一下树模型是怎么做可 ...
- IRT模型的参数估计方法(EM算法和MCMC算法)
1.IRT模型概述 IRT(item response theory 项目反映理论)模型.IRT模型用来描述被试者能力和项目特性之间的关系.在现实生活中,由于被试者的能力不能通过可观测的数据进行描述, ...
随机推荐
- Go 语言基础——变量常量的定义
go语言不支持隐式类型转换,别名和原有类型也不能进行隐式类型转换 go语言不支持隐式转换 变量 变量声明 var v1 int var v2 string var v3 [10]int // 数组 v ...
- Mysql高手系列 - 第8篇:详解排序和分页(order by & limit),及存在的坑
这是Mysql系列第8篇. 环境:mysql5.7.25,cmd命令中进行演示. 代码中被[]包含的表示可选,|符号分开的表示可选其一. 本章内容 详解排序查询 详解limit limit存在的坑 分 ...
- virtualbox下给centos7固定ip
在virtualbox桥接连接模式下,固定虚拟机的ip. 修改/etc/sysconfig/network-scripts/ifcfg-ens33文件 添加如下信息: 保存 重启网卡: sudo se ...
- SpringMVC的工作原理图
SpringMVC的工作原理图: SpringMVC流程 1. 用户发送请求至前端控制器DispatcherServlet. 2. DispatcherServlet收到请求调用HandlerMa ...
- 使用secureCRT进行linux和windows之间的nginx文件夹传输
1.首先进入secureCRT软件,新建一个链接,我现在已经创建好了进入这个页面: 注意:新建链接时里面的hostname是你linux的ip地址,使用ifconfig就可以看到 2.在secureC ...
- 彻底解决android拍照后无法显示的问题
这是对上篇"android 图片拍照,相册选图,剪切并显示"的文章之后的 改进 上一篇文章虽然能解决图片的拍照剪切以及显示,但是发现他有一个缺点, 如果该程序单独运行,貌似没有任何 ...
- 表达式树练习实践:C# 五类运算符的表达式树表达
目录 表达式树练习实践:C# 运算符 一,算术运算符 + 与 Add() - 与 Subtract() 乘除.取模 自增自减 二,关系运算符 ==.!=.>.<.>=.<= 三 ...
- java获取电脑mac物理地址
import java.net.InetAddress;import java.net.NetworkInterface;import java.net.SocketException;import ...
- P0.0口驱动一个LED闪烁
#include<reg51.h> //头文件 sbit LED=P0^; //led接P0.0,定义P0.0为P0^0 void delay(unsigned int x) //延时函数 ...
- 第二次作业:使用Packet Tracer分析应用层协议(DNS、FTP、DHCP、SMTP、POP3)
0 个人信息 张樱姿 201821121038 计算1812 1 实验目的 熟练使用Packet Tracer工具.分析抓到的应用层协议数据包,深入理解应用层协议,包括语法.语义.时序. 2 实验内容 ...