爬虫之scrapy简介
Scrapy框架与原始爬虫的区别
原始爬虫
效率低、同步、阻塞
Scrapy框架
效率高、异步、非阻塞

Scrapy的概念
- 爬虫框架
- 开发速度快
- 稳定性高
- 性能优越
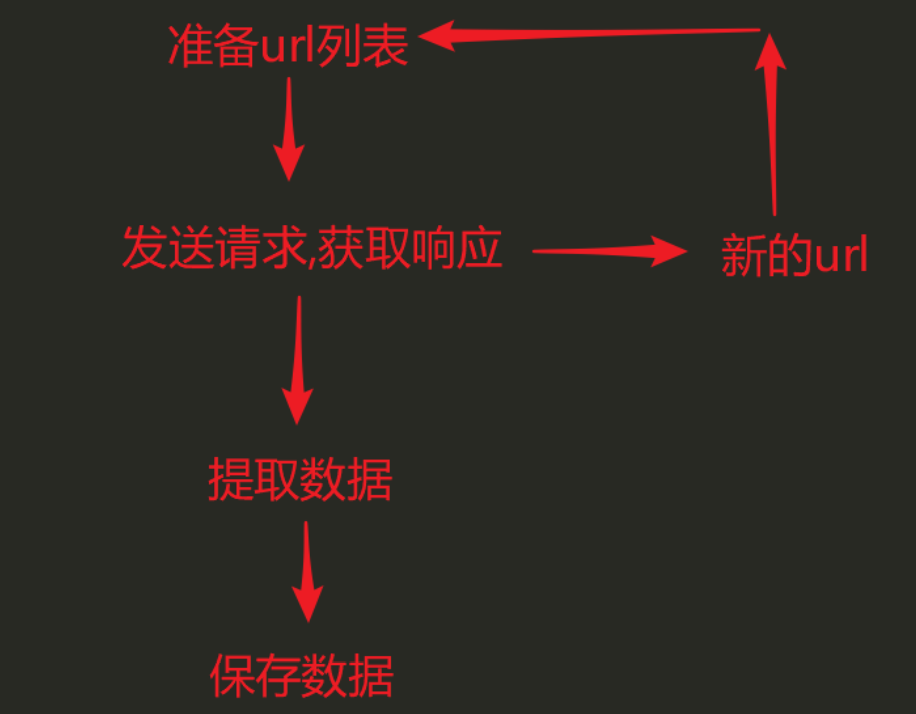
scrapy的流程
- 爬虫模块(Spiders) --> 准备起始URL(Request) --> 爬虫中间件 --> 引擎 --> 调度器(Scheduler):请求去重, 缓存请求(队列)
- 调度器 --> 请求(Request) --> 引擎 --> 下载器中间件 --> 下载器:发送请求, 获取响应, 把响应封装为Response对象
- 下载器 -Response --> 下载器中间件 --> 引擎 --> 爬虫中间件 --> 爬虫模块:解析响应数据, 提取数据, 提取请求
- 爬虫模块 --> 数据 --> 引擎 --> 管道(Pipeline):保存数据
- 爬虫模块 --> 请求 --> 爬虫中间件 --> 引擎 --> 调度器
scrapy各个组件作用
- 引擎模块:调度各个模块, 以及模块间数据传递.
- 调度器模块:请求去重, 缓存请求(队列)
- 下载器: 发送请求, 获取响应数据
- 爬虫模块:解析响应数据, 提取数据, 提取请求
- 管道模块:处理数据, 比如:保存数据
- 下载器中间件: 在引擎和下载器之间, 把请求交给下载器之前, 可以对请求进行处理, 比如设置代理, 设置随机请求头.
- 爬虫中间件: 在引擎和爬虫之间, 可以请求和响应数据进行过滤.
ScrapyShell
使用格式:scrapy shell URL
作用
- 可以用于测试response常见属性和方法
- 可用于用于测试/调试XPATH
response中重要属性
- response.body:响应的二进制数据
- response.text: 响应的文本字符串数据
- response.url: 响应的URL
- response.request.headers: 响应对应的请求的请求头
settings.py中的设置信息
- ROBOTSTXT_OBEY 是否遵守robots协议,默认是遵守
- DOWNLOAD_DELAY 下载延迟,默认0.5~1.5的随机延迟
- COOKIES_ENABLED 是否开启cookie,即每次请求带上前一次的cookie,默认是开启的
- DEFAULT_REQUEST_HEADERS 设置默认请求头
- DOWNLOADER_MIDDLEWARES 下载中间件
- LOG_LEVEL 控制日志输出的级别
- 日志等级: DEBUG,INFO,WARNING,ERROR,CRITICAL
- LOG_FILE 设置log日志文件的保存路径, 如果设置该参数,终端将不再显示日志信息
回调函数之间数据的传递
yield scrapy.Requst(url,[callback,method,headers,body,cookies,meta,dont_filter])
- callback:表示当前的url的响应交给哪个函数去处理
- meta:实现数据在不同的解析函数中传递,设置代理IP
- meta={'xx':yy}:在callback函数中使用response.meta['xx']获取传递过来的yy的数据
- dont_filter:默认为False,会过滤请求的url地址,即请求过的url地址不会继续被请求,对需要重复请求的url地址可以把它设置为True
- method:指定POST或GET请求
- headers:接收一个字典,其中不包括cookies
- cookies:接收一个字典,专门放置cookies
- body:接收字符串格式:name=aa&age=bb
scrapy中间件
- 先书写middlewares文件内部的process_request方法
- 再在setting文件中打开配置信息
DOWNLOADER_MIDDLEWARES = {
'middle.middlewares.MiddleDownloaderMiddleware': 543,
}
USER_AGENT_LIST = [
'',
'',
'...',] PROXY_LIST = [
'14.106.27.137:8118',
'27.193.49.150:8118',
'12.86.54.194:8118',
'115.218.132.203:8118',
'182.96.203.11:49225',
'114.249.112.65:9000',
'43.248.122.251:8123',
]
Downloader Middlewares默认的方法
process_request(self, request, spider)
- 当每个request通过下载中间件时,该方法被调用。
- 返回None值:继续请求
- 返回Response对象:不再请求,把response返回给引擎
- 返回Request对象:把request对象交给引擎 -> 调度器进行后续的请求
process_response(self, request, response, spider)
- 当下载器完成http请求,传递响应给引擎的时候调用
- 返回Resposne:交给process_response来处理
- 返回Request对象:交给调取器继续请求
def process_request(self, request, spider):
# 处理请求的下载器中间件
# Called for each request that goes through the downloader
# 每当有一个request经过下载中间件的时候,那么此方法就会被调用
# 随机获取一个user_agent
# USER_AGENT_LIST/PROXY_LIST:setting中配置
"""
随机User-Agent下载器中间件
1.在settings.py中准备USER_AGENT_LIST列表
2.实现 process_request`方法
3.随机中USER_AGENT_LIST, 选出一个UserAgent设置给request
request.headers['User-Agent']
在settings.py中配置中间件
"""
ua = random.choice(USER_AGENT_LIST)
request.headers['User-Agent'] = ua
"""
代理IP下载器中间件
request.meta['proxy']
"""
p = random.choice(PROXY_LIST)
request.meta['proxy'] = p
# return None 这个请求继续执行
# return request 换了一个新的请求,把request对象交给引擎 -> 调度器进行后续的请求
# return response 根本不会再发送请求,把response返回给引擎
return None
爬虫之scrapy简介的更多相关文章
- 网络爬虫框架Scrapy简介
作者: 黄进(QQ:7149101) 一. 网络爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本:它是一个自动提取网页的程序,它为搜索引擎从万维 ...
- Python爬虫框架Scrapy安装使用步骤
一.爬虫框架Scarpy简介Scrapy 是一个快速的高层次的屏幕抓取和网页爬虫框架,爬取网站,从网站页面得到结构化的数据,它有着广泛的用途,从数据挖掘到监测和自动测试,Scrapy完全用Python ...
- 97、爬虫框架scrapy
本篇导航: 介绍与安装 命令行工具 项目结构以及爬虫应用简介 Spiders 其它介绍 爬取亚马逊商品信息 一.介绍与安装 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, ...
- 爬虫(scrapy第一篇)
---------------------------------------------------------------------------------------------------- ...
- 爬虫框架Scrapy 之(一) --- scrapy初识
Scrapy框架简介 scrapy是基于Twisted的一个第三方爬虫框架,许多功能已经被封装好,方便提取结构性的数据.其可以应用在数据挖掘,信息处理等方面.提供了许多的爬虫的基类,帮我们更简便使用爬 ...
- 爬虫框架 Scrapy
一 介绍 crapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速.简单.可扩展的方式从网站中提取所需的数据.但目前Scrapy的用途十分广泛,可用 ...
- Python 爬虫七 Scrapy
Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设 ...
- 5、爬虫之scrapy框架
一 scrapy框架简介 1 介绍 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速.简单.可扩展的方式从网站中提取所需的数据.但目前Sc ...
- 05 爬虫之scrapy
一 scrapy框架简介 01 什么是scrapy: Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队 ...
随机推荐
- 品Spring:关于@Scheduled定时任务的思考与探索,结果尴尬了
非Spring风格的代码与Spring的结合 现在的开发都是基于Spring的,所有的依赖都有Spring管理,这没有问题. 但是要突然写一些非Spring风格的代码时,可能会很不习惯,如果还要和Sp ...
- 利用双重检查锁定和CAS算法:解决并发下数据库的一致性问题
背景 最近有一个场景遇到了数据库的并发问题.现在先由我来抽象一下,去掉不必要的繁杂业务. 数据库表book存储着每本书的阅读量,一开始数据库是空的,不存在任何的数据.当用户访问接口的时候,判断 ...
- Linux防火墙常用操作
/tcp —— 配置白名单 sudo systemctl start firewalld — 启动防火墙 sudo firewall-cmd --state - 看状态 sudo firewall-c ...
- Ubuntu 查看已安装软件
apt list --installed dpkg -l
- XSS中的同源策略和跨域问题
转自 https://www.cnblogs.com/chaoyuehedy/p/5556557.html 1 同源策略 所谓同源策略,指的是浏览器对不同源的脚本或者文本的访问方式进行的限制.比如源a ...
- .NET实时2D渲染入门·动态时钟
.NET实时2D渲染入门·动态时钟 从小以来"坦克大战"."魂斗罗"等游戏总令我魂牵梦绕.这些游戏的基础就是2D实时渲染,以前没意识,直到后来找到了Direct ...
- [JoyOI1519] 博彩游戏
题目限制 时间限制 内存限制 评测方式 题目来源 1000ms 131072KiB 标准比较器 Local 题目背景 Bob最近迷上了一个博彩游戏…… 题目描述 这个游戏的规则是这样的:每花一块钱可以 ...
- Shell多进程执行任务
展示代码 #!/bin/bash trap "exec 1000>&-;exec 1000<&-;exit 0" 2 # 分别为 创建管道文件,文件操作 ...
- PageObjec页面对象模式(理论)
ui自动化测试的分层思想:实现测试数据与业务数据分离 1. 基础层 2. 对象层:每个页面的操作元素封装为一个文件 3.测试用例层:调用对象层封装的方法进行测试用例编写
- Bootstrap应用核心
Bootstrap是当前世界最受欢迎的响应式.移动设备优先的门户和应用前端框架.它不是单一的CSS或JavaScript框架,而是完整的HTML.CSS.JavaScript框架,你可以仅通过Boot ...