scrapy抓取斗鱼APP主播信息
如何进行APP抓包
首先确保手机和电脑连接的是同一个局域网(通过路由器转发的网络,校园网好像还有些问题)。
1.安装抓包工具Fiddler,并进行配置
Tools>>options>>connections>>勾选allow remote computers to connect
2.查看本机IP
在cmd窗口(win+R快捷键),输入ipconfig,查看(以太网)IP地址。
3.配置手机端。
手机连网后(和电脑端同一局域网),打开手机浏览器并访问:http://ip:8888(ip是你第二步查看到的IP地址, 8888端口是Fiddler默认端口),
有些浏览器打不开网页,换一下浏览器就行。
如果访问成功,会出现一个网页:
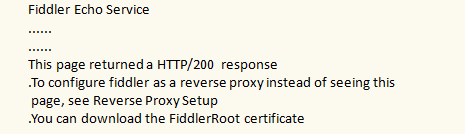
4.下载证书
点击FiddlerRoot certificate,下载证书。如果不下载证书的话,只能抓到http请求,抓不到https请求。
5.安装证书
部分手机可以直接点击安装
部分手机需要通过:
设置>>wifi(或WLAN)>>高级设置>>安装证书>>选中下载好的FiddlerRoot.cer>>确定
或:
设置>>更多设置>>系统安全>>从存储设备安装
安装后,可以按照自己的意愿,给证书起一个名字,例如Fiddler,确定后会显示安装完成!
6.设置手机代理

手机设置代理后,打开Fiddler,接下来在手机端打开app或者浏览器,所有通过手机发送的请求都会被Fiddler抓取。
scrapy框架下载图片
Scrapy用ImagesPipeline类提供一种方便的方式下载和存储图片(需要PIL库支持)。
主要特征:
- 将下载图片转化为通用的jpg和rgb格式
- 避免重复下载
- 缩略图生成
- 图片大小过滤
工作流程:
- 抓取一个item,将图片的urls放入image_urls字段
- 从Spider返回的item,传递到 Item Pipeline
- 当Item传递到ImagePipeline,将调用scrapy调度器和下载器完成image_urls中的url调度和下载。ImagePipeline会自动高优先级抓取这些url,同时,item会被锁定直到图片抓取完毕才解锁
- 图片下载成功后,图片下载路径,url和校验信息等会被填充到images字段中
scrapy抓取斗鱼主播图像
ImagePipeline简介
首先介绍一下图片下载中的ImagePipeline类中的两个重要方法。在自定义的ImagePipeline类中要重写:
get_media_requests(item, info)和item_completed(results, items, info);其中,正如工作流所述,Pipeline从item中获取图片的urls并下载,
所以必须重载get_media_requests,并返回一个Request对象,这些请求对象将被pipelines处理
下载完成后,结果发送发哦item_complete方法,下载结果为一个二元组的list, 每个元组包含:
(success, image_info_or_failure),其中:
success: bool值,true表示下载成功
image_info_or_error: 如果success为True,则该字典包含以下键值对:{path:本地存储路径, checksum:校验码}
分析及编码
通过Fiddler抓包工具分析,请求连接为:http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset=0,其中
offset为变量,每次翻页增加20。
首先,使用命令创建项目
scrapy startproject Douyu
来到items.py文件,编写需要抓取的字段如下:
# -*- coding: utf-8 -*- import scrapy class DouyuItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field() # 图片链接
image_link = scrapy.Field() # 图片保存路径
image_path = scrapy.Field() # 主播名
nick_name = scrapy.Field() # 房间号
room_id = scrapy.Field() # 所在城市
city = scrapy.Field() # 数据源
source = scrapy.Field()
明确抓取目标后,生成爬虫,开始编写爬虫逻辑
scrapy genspider douyu douyucdn.com # 生成爬虫
编写爬虫逻辑之前,在下载中间件中,给每个请求添加头部信息:
# -*- coding: utf-8 -*- # Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html from scrapy import signals
from Douyu.settings import USER_AGENTS as ua
import random class DouyuSpiderMiddleware(object):
def process_request(self, request, spider):
"""
给每一个请求随机分配一个代理
:param request:
:param spider:
:return:
"""
user_agent = random.choice(ua)
request.headers['User-Agent'] = user_agent
然后来到spiders文件夹下的爬虫文件,开始编写爬虫逻辑:
# -*- coding: utf-8 -*-
import json
import scrapy
from Douyu.items import DouyuItem class DouyuSpider(scrapy.Spider):
name = 'douyu'
allowed_domains = ['douyucdn.cn'] offset = 0 # 请求url
base_url = "http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset="
start_urls = [base_url + str(offset)] def parse(self, response): # 手机端斗鱼返回的是json格式的数据,所有数据都在data中
# 直接从请求响应体中获取数据
node_list = json.loads(response.body)['data'] # 如果拿不到数据,说明已经爬取完所有翻页
if not node_list:
return # 对具体数据进行解析
for node in node_list: # 数据保存
item = DouyuItem()
item['image_link'] = node['vertical_src']
item['nick_name'] = node['nickname']
item['room_id'] = node['room_id']
item['city'] = node['anchor_city'] yield item # 实现翻页
self.offset += 20
yield scrapy.Request(self.base_url + str(self.offset), callback=self.parse)
编写完爬虫逻辑后,可以开始编写图片下载逻辑了,来到pipelines文件:
# -*- coding: utf-8 -*-
import os
import scrapy # scrapy下载图片专用管道
from scrapy.pipelines.images import ImagesPipeline
# 在setting中指定图片存储路径
from Douyu.settings import IMAGES_STORE class ImageSourcePipeline(object): # 添加数据源
def process_item(self, item, spider):
item['source'] = spider.name
return item class DouyuImagePipeline(ImagesPipeline): # 发送图片链接请求
def get_media_requests(self, item, info):
# 获取item数据的图片链接
image_link = item['image_link'] # 发送图片请求,响应会保存在settings中指定的路径下(IMAGES_STORE)
try:
yield scrapy.Request(url=image_link)
except:
print(image_link) def item_completed(self, results, item, info):
"""
:param results: 下载图片结果,包含一个二元组(下载状态,图片路径)
:param item:
:param info:
:return:
"""
# 取出每个图片的原本路径
# path为设定的图片存储路径
image_path = [x['path'] for ok, x in results if ok] # 默认保存当前图片的路径
old_name = IMAGES_STORE + '\\' + image_path[0] # 新建当前图片路径,因为默认路径有一些不需要的东西
new_name = IMAGES_STORE + '\\'+item['nick_name'] + '.jpg' item['image_path'] = new_name
try:
# 将原本路径的图片名,修改为新建的图片名
os.rename(old_name, new_name)
except:
print("INFO:图片更名错误!") return item
整体逻辑编写完成,在settings文件中分别打开中间件、管道等的注释信息,即可运行爬虫!
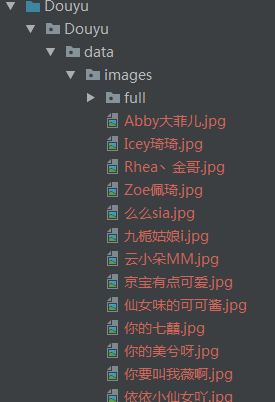
运行结果:
完整代码
参见:https://github.com/zInPython/Douyu
scrapy抓取斗鱼APP主播信息的更多相关文章
- scrapy抓取拉勾网职位信息(一)——scrapy初识及lagou爬虫项目建立
本次以scrapy抓取拉勾网职位信息作为scrapy学习的一个实战演练 python版本:3.7.1 框架:scrapy(pip直接安装可能会报错,如果是vc++环境不满足,建议直接安装一个visua ...
- scrapy自动抓取蛋壳公寓最新房源信息并存入sql数据库
利用scrapy抓取蛋壳公寓上的房源信息,以北京市为例,目标url:https://www.dankegongyu.com/room/bj 思路分析 每次更新最新消息,都是在第一页上显示,因此考虑隔一 ...
- scrapy抓取淘宝女郎
scrapy抓取淘宝女郎 准备工作 首先在淘宝女郎的首页这里查看,当然想要爬取更多的话,当然这里要查看翻页的url,不过这操蛋的地方就是这里的翻页是使用javascript加载的,这个就有点尴尬了,找 ...
- 分布式爬虫:使用Scrapy抓取数据
分布式爬虫:使用Scrapy抓取数据 Scrapy是Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘. ...
- 通过Scrapy抓取QQ空间
毕业设计题目就是用Scrapy抓取QQ空间的数据,最近毕业设计弄完了,来总结以下: 首先是模拟登录的问题: 由于Tencent对模拟登录比较讨厌,各个防备,而本人能力有限,所以做的最简单的,手动登录后 ...
- python scrapy 抓取脚本之家文章(scrapy 入门使用简介)
老早之前就听说过python的scrapy.这是一个分布式爬虫的框架,可以让你轻松写出高性能的分布式异步爬虫.使用框架的最大好处当然就是不同重复造轮子了,因为有很多东西框架当中都有了,直接拿过来使用就 ...
- Fiddler高级用法-抓取手机app数据包
在上一篇中介绍了Fiddler的基本使用方法.通过上一篇的操作我们可以直接抓取浏览器的数据包.但在APP测试中,我们需要抓取手机APP上的数据包,应该怎么操作呢? Andriod配置方法 1)确保手机 ...
- 利用scrapy爬取腾讯的招聘信息
利用scrapy框架抓取腾讯的招聘信息,爬取地址为:https://hr.tencent.com/position.php 抓取字段包括:招聘岗位,人数,工作地点,发布时间,及具体的工作要求和工作任务 ...
- scrapy抓取中国新闻网新闻
目标说明 利用scrapy抓取中新网新闻,关于自然灾害滑坡的全部国内新闻:要求主题为滑坡类新闻,包含灾害造成的经济损失等相关内容,并结合textrank算法,得到每篇新闻的关键词,便于后续文本挖掘分析 ...
随机推荐
- 数据结构(四十二)散列表查找(Hash Table)
一.散列表查找的基础知识 1.散列表查找的定义 散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key).查找时,根据这个确定的对应关系找到 ...
- C#基本网络操作
建档操作如ping,查询本机主机ip,同步异步查询局域网内主机,同步异步邮件发送等 1)ping 通过ping类测试网络 using System; using System.Text; using ...
- 2018.8.15 python中的冒泡法排序
# 给出一个纯数字列表. 请对列表进行排序. # 思路: # 1.完成a和b的数据交换. 例如, a = 10, b = 24 交换之后, a = 24, b = 10 # 2.循环列表. 判断a[i ...
- github实用的搜索小技巧
查资源,学习优秀的框架,搜索是一种能力! 作为程序猿开发中最大的同性交友网站,github当之无愧,里面有很多优秀的开源框架,各种技术大佬混迹其中,有他们总结的学习教程,造好的轮子(开发的各种工具,技 ...
- 分手是祝愿:dp
Description Zeit und Raum trennen dich und mich. 时空将你我分开. B 君在玩一个游戏,这个游戏n个灯和n个开关组成,给定这n个灯的初始状态,下标为从1 ...
- 「CF52C」Circular RMQ
更好的阅读体验 Portal Portal1: Codeforces Portal2: Luogu Description You are given circular array \(a_0, a_ ...
- 基于 JavaFX 开发的聊天客户端 OIM-即时通讯
OIM 详细介绍 一.简介 OIM是一套即时通讯的聊天系统,在这里献给大家,一方面希望能够帮助对即时通讯有兴趣研究的朋友,希望我们能够共同进步,另一个就是希望能够帮助到需要即时通讯系统的朋友或者企业, ...
- 004.Kubernetes二进制部署创建证书
一 创建CA证书和密钥 1.1 安装cfssl工具集 [root@k8smaster01 ~]# mkdir -p /opt/k8s/cert [root@k8smaster01 ~]# curl - ...
- 开启docker远程访问
开启docker远程访问 进入到/lib/systemd/system/docker.service vim /lib/systemd/system/docker.service 找到ExecStar ...
- [视频演示].NET Core开发的iNeuOS物联网平台,实现从设备&PLC、云平台、移动APP数据链路闭环
目 录 1. 概述... 1 2. 登陆信息... 2 3. 设备驱动... 3 4. 组态建模... 3 5. 手机APP. 5 6. ...