爬虫系列(十一) 用requests和xpath爬取豆瓣电影评论
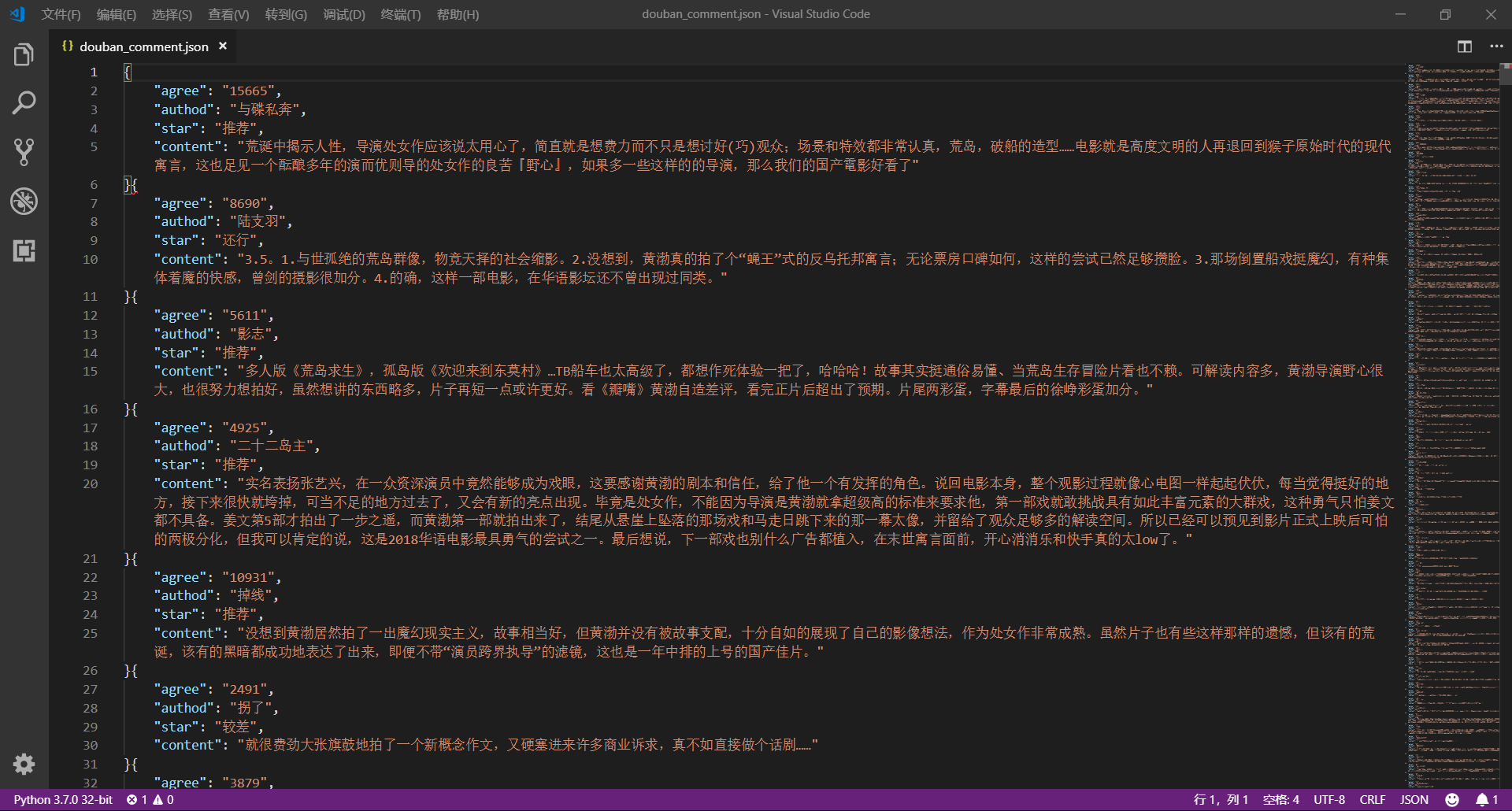
这篇文章,我们继续利用 requests 和 xpath 爬取豆瓣电影的短评,下面还是先贴上效果图:
1、网页分析
(1)翻页
我们还是使用 Chrome 浏览器打开豆瓣电影中某一部电影的评论进行分析,这里示例为《一出好戏》
和之前一样,我们可以通过构造 URL 获取全部网页的内容,但是这次我们尝试使用一种新的方法 —— 翻页
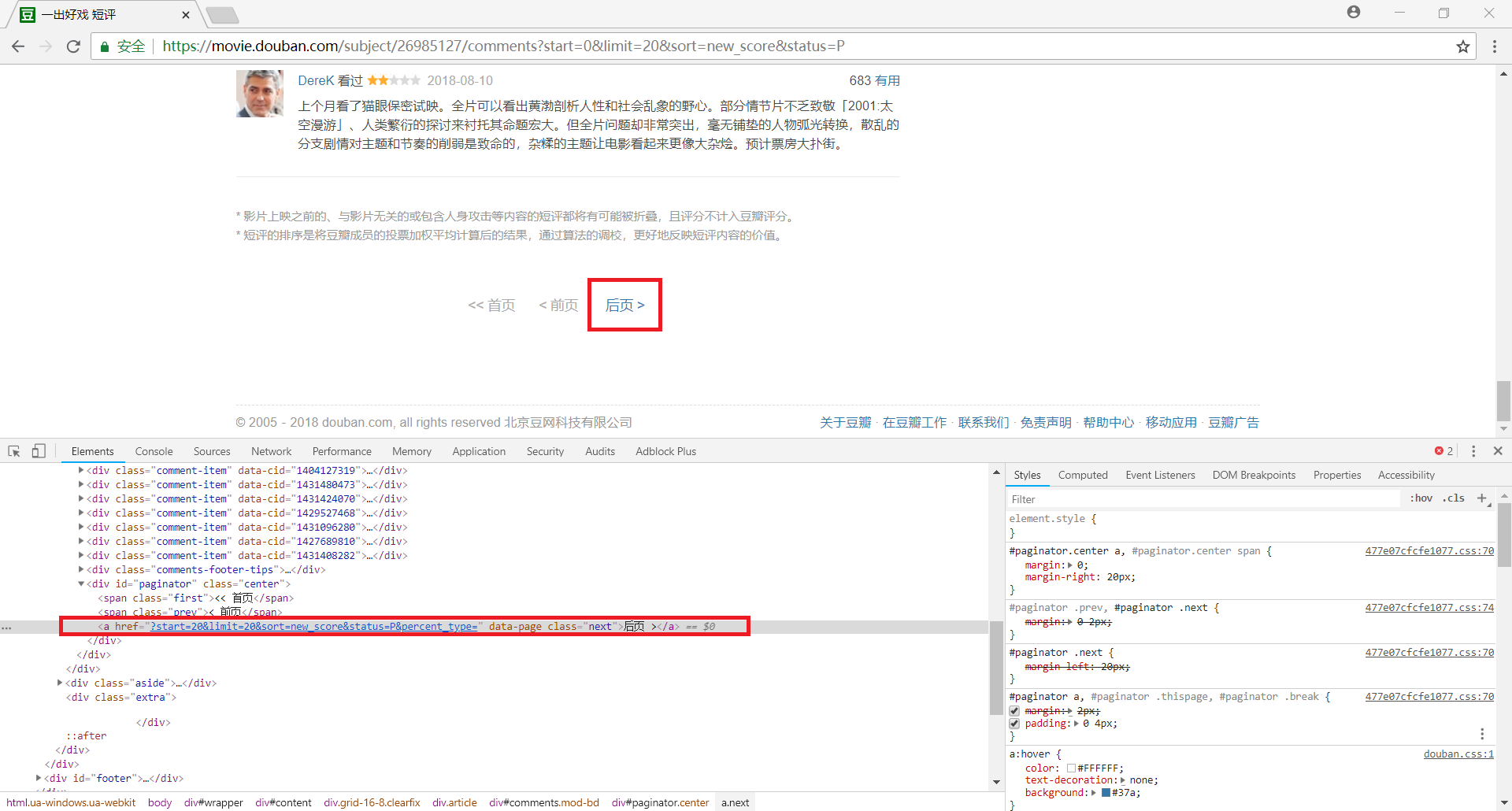
使用快捷键 Ctrl+Shift+I 打开开发者工具,然后使用快捷键 Ctrl+Shift+C 打开元素选择工具
此时用鼠标点击网页中的 后页,就会在源代码中自动定位到相应的位置
接下来我们用 xpath 匹配下一页的链接地址:
html.xpath('//div[@id="paginator"]/a[@class="next"]/@href')
这样一来,我们只要在每一页中通过循环不断获取下一页的内容即可
核心代码如下:
# 获取网页源代码
def get_page(url):
# 构造请求头部
headers = {
'USER-AGENT':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 发送请求,获得响应
response = requests.get(url=url,headers=headers)
# 获得网页源代码
html = response.text
# 返回网页源代码
return html
# 解析网页源代码,获取下一页链接
def parse4link(html,base_url):
# 初始化返回结果
link = None
# 构造 _Element 对象
html_elem = etree.HTML(html)
# 匹配下一页的链接地址,注意,它是一个相对地址
url = html_elem.xpath('//div[@id="paginator"]/a[@class="next"]/@href')
# 若匹配成功,则将匹配结果与初始 URL 拼接,构成完整的链接地址
if url:
link = base_url + url[0]
return link
(2)分析网页内容
这一次我们需要的数据包括(这里还是使用 xpath 进行匹配):
- 赞同人数:
//div[@class="comment-item"]/div[2]/h3/span[1]/span/text() - 评论者:
//div[@class="comment-item"]/div[2]/h3/span[2]/a/text() - 评价:
//div[@class="comment-item"]/div[2]/h3/span[2]/span[2]/@title - 评论内容:
//div[@class="comment-item"]/div[2]/p/span/text()

核心代码如下:
# 解析网页源代码,获取数据
def parse4data(html):
# 构造 _Element 对象
html = etree.HTML(html)
# 赞同人数
agrees = html.xpath('//div[@class="comment-item"]/div[2]/h3/span[1]/span/text()')
# 评论作者
authods = html.xpath('//div[@class="comment-item"]/div[2]/h3/span[2]/a/text()')
# 评价
stars = html.xpath('//div[@class="comment-item"]/div[2]/h3/span[2]/span[2]/@title')
# 评论内容
contents = html.xpath('//div[@class="comment-item"]/div[2]/p/span/text()')
# 获得结果
data = zip(agrees,authods,stars,contents)
# 返回结果
return data
(3)保存数据
下面将数据分别保存为 txt 文件、json 文件和 csv 文件
import json
import csv
# 打开文件
def openfile(fm):
fd = None
if fm == 'txt':
fd = open('douban_comment.txt','w',encoding='utf-8')
elif fm == 'json':
fd = open('douban_comment.json','w',encoding='utf-8')
elif fm == 'csv':
fd = open('douban_comment.csv','w',encoding='utf-8',newline='')
return fd
# 将数据保存到文件
def save2file(fm,fd,data):
if fm == 'txt':
for item in data:
fd.write('----------------------------------------\n')
fd.write('agree:' + str(item[0]) + '\n')
fd.write('authod:' + str(item[1]) + '\n')
fd.write('star:' + str(item[2]) + '\n')
fd.write('content:' + str(item[3]) + '\n')
if fm == 'json':
temp = ('agree','authod','star','content')
for item in data:
json.dump(dict(zip(temp,item)),fd,ensure_ascii=False)
if fm == 'csv':
writer = csv.writer(fd)
for item in data:
writer.writerow(item)
2、代码实现
注意,本程序需要用户输入电影 ID,用于构造初始 URL ,例如:
如果电影的链接地址为:https://movie.douban.com/subject/26985127/comments?status=P
那么电影 ID 为:26985127
【PS:虽然这种做法对用户不太友好,但是由于个人水平以及时间问题,目前也还没想到比较好的解决方法,
最初的想法是让用户输入电影名称,然后由程序自动将电影名称映射为电影 ID,从而构造出初始 URL】
import requests
from lxml import etree
import re
import json
import csv
import time
import random
# 获取网页源代码
def get_page(url):
headers = {
'USER-AGENT':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
response = requests.get(url=url,headers=headers)
html = response.text
return html
# 解析网页源代码,获取下一页链接
def parse4link(html,base_url):
link = None
html_elem = etree.HTML(html)
url = html_elem.xpath('//div[@id="paginator"]/a[@class="next"]/@href')
if url:
link = base_url + url[0]
return link
# 解析网页源代码,获取数据
def parse4data(html):
html = etree.HTML(html)
agrees = html.xpath('//div[@class="comment-item"]/div[2]/h3/span[1]/span/text()')
authods = html.xpath('//div[@class="comment-item"]/div[2]/h3/span[2]/a/text()')
stars = html.xpath('//div[@class="comment-item"]/div[2]/h3/span[2]/span[2]/@title')
contents = html.xpath('//div[@class="comment-item"]/div[2]/p/span/text()')
data = zip(agrees,authods,stars,contents)
return data
# 打开文件
def openfile(fm):
fd = None
if fm == 'txt':
fd = open('douban_comment.txt','w',encoding='utf-8')
elif fm == 'json':
fd = open('douban_comment.json','w',encoding='utf-8')
elif fm == 'csv':
fd = open('douban_comment.csv','w',encoding='utf-8',newline='')
return fd
# 将数据保存到文件
def save2file(fm,fd,data):
if fm == 'txt':
for item in data:
fd.write('----------------------------------------\n')
fd.write('agree:' + str(item[0]) + '\n')
fd.write('authod:' + str(item[1]) + '\n')
fd.write('star:' + str(item[2]) + '\n')
fd.write('content:' + str(item[3]) + '\n')
if fm == 'json':
temp = ('agree','authod','star','content')
for item in data:
json.dump(dict(zip(temp,item)),fd,ensure_ascii=False)
if fm == 'csv':
writer = csv.writer(fd)
for item in data:
writer.writerow(item)
# 开始爬取网页
def crawl():
moveID = input('请输入电影ID:')
while not re.match(r'\d{8}',moveID):
moveID = input('输入错误,请重新输入电影ID:')
base_url = 'https://movie.douban.com/subject/' + moveID + '/comments'
fm = input('请输入文件保存格式(txt、json、csv):')
while fm!='txt' and fm!='json' and fm!='csv':
fm = input('输入错误,请重新输入文件保存格式(txt、json、csv):')
fd = openfile(fm)
print('开始爬取')
link = base_url
while link:
print('正在爬取 ' + str(link) + ' ......')
html = get_page(link)
link = parse4link(html,base_url)
data = parse4data(html)
save2file(fm,fd,data)
time.sleep(random.random())
fd.close()
print('结束爬取')
if __name__ == '__main__':
crawl()
写完之后,我们运行代码试一下效果:
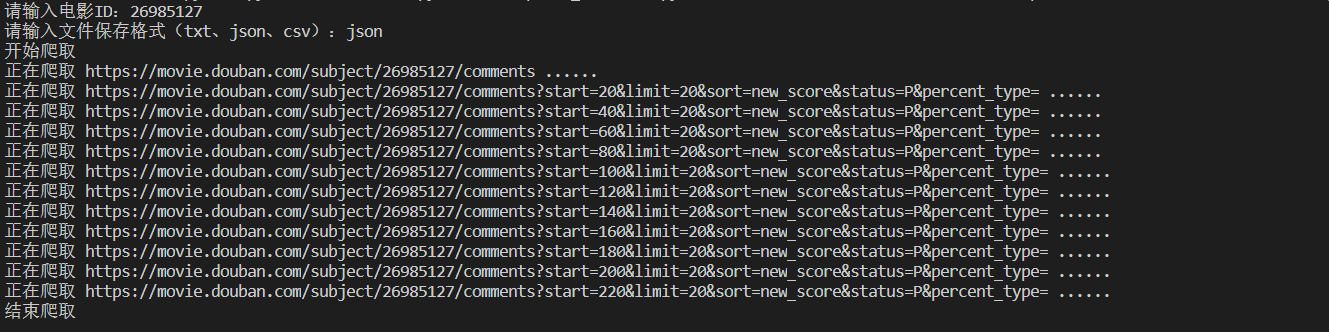
咦?好像有点怪怪的,怎么只有 11 页评论?不科学呀,《一出好戏》这部电影明明有十多万条评论的呀
我们直接用浏览器打开最后一个链接看一下:
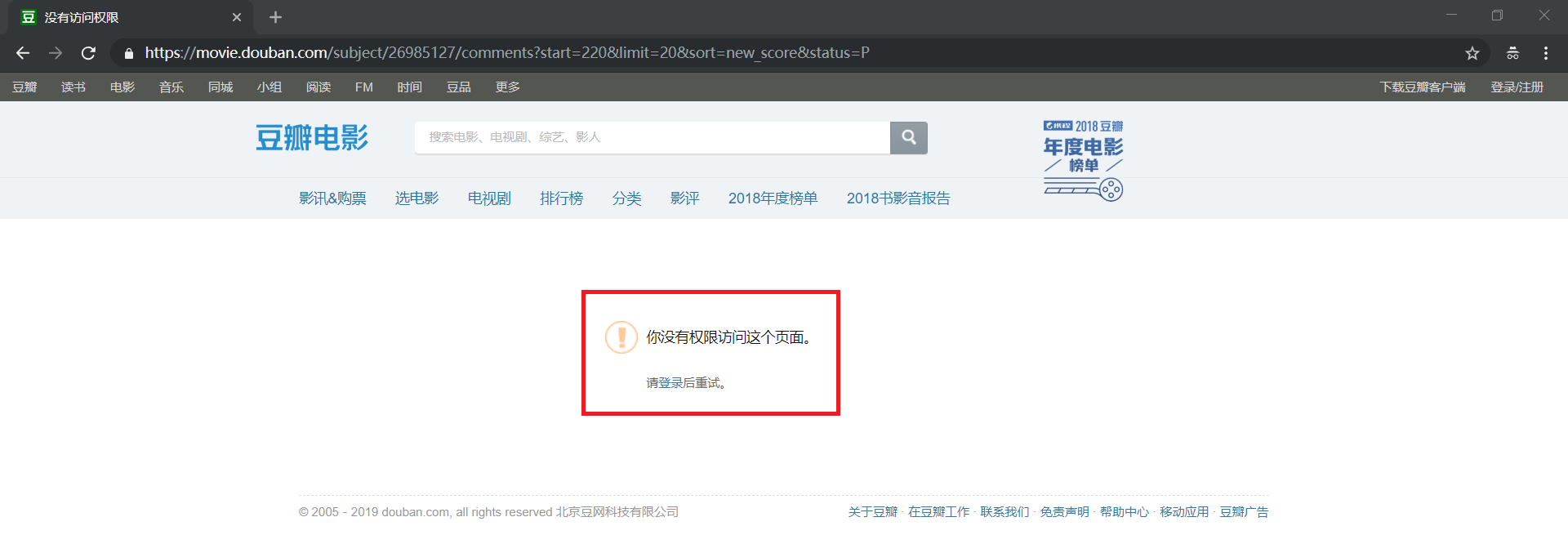
原来,11 页之后的评论是需要登陆之后才有权限访问的,没办法,那就只好再写一个模拟登陆呗
我们这里使用最最简单的方法进行模拟登陆,那就是使用 Cookie,并且是手动获取 Cookie (懒)
简单来说,Cookie 是为了记录用户信息而储存在用户本地终端上的数据
当我们在浏览器上登陆后,我们登陆的信息会被记录在 Cookie 中
之后的操作,浏览器会自动在请求头中加上 Cookie,说明这是一个特定用户发送的请求
那么怎样获取 Cookie 呢?也很简单,用浏览器打开 豆瓣电影首页 进行登陆,然后进行抓包就可以
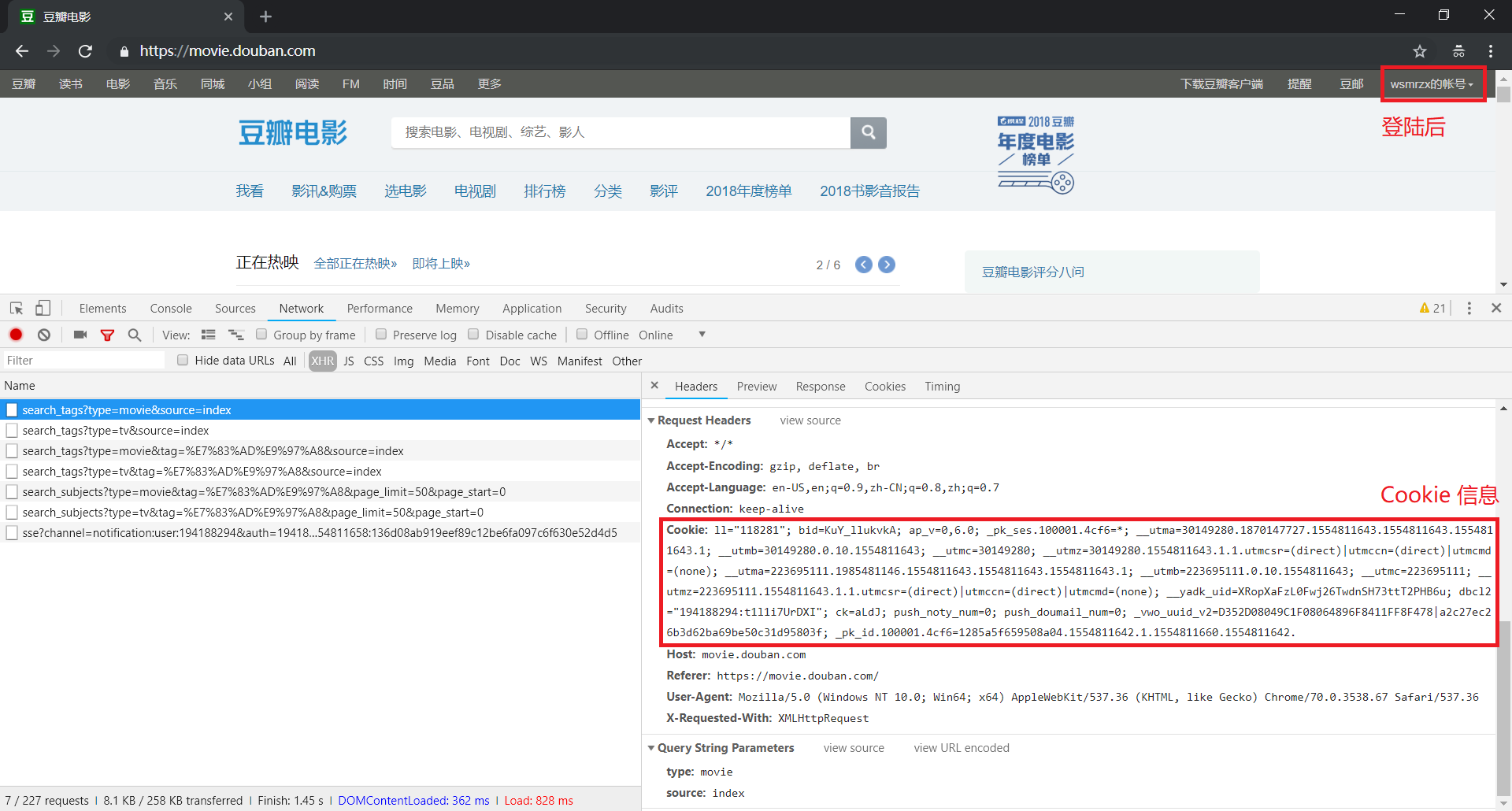
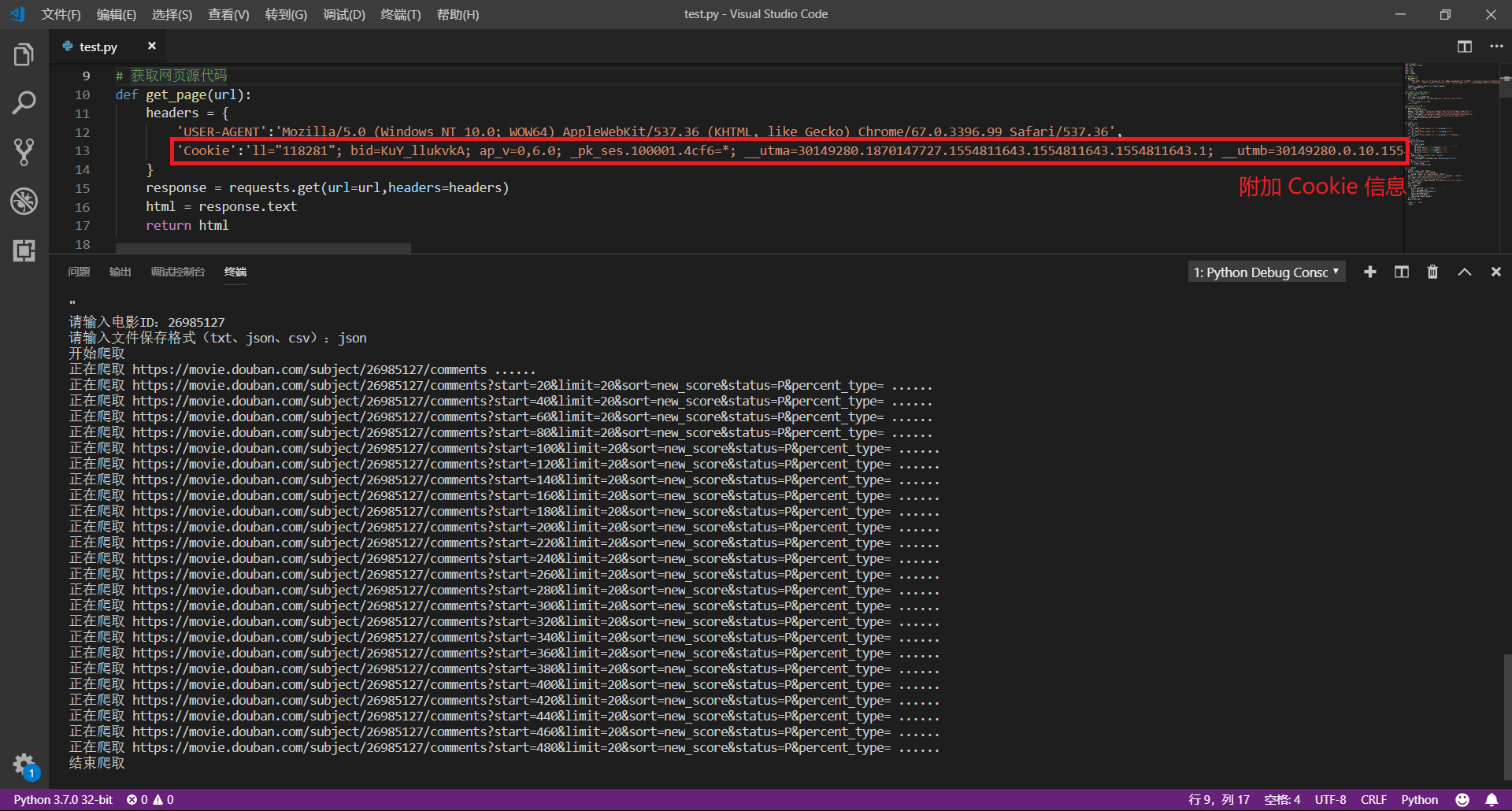
最后,我们只需要把 Cookie 信息复制下来,放到请求头中一起发送,这样就可以继续愉快的爬取评论啦
【PS:注意 Cookie 的有效期,获取 Cookie 后应该尽快使用】
【爬虫系列相关文章】
爬虫系列(十一) 用requests和xpath爬取豆瓣电影评论的更多相关文章
- 爬虫系列(十) 用requests和xpath爬取豆瓣电影
这篇文章我们将使用 requests 和 xpath 爬取豆瓣电影 Top250,下面先贴上最终的效果图: 1.网页分析 (1)分析 URL 规律 我们首先使用 Chrome 浏览器打开 豆瓣电影 T ...
- requests+lxml+xpath爬取豆瓣电影
(1)lxml解析html from lxml import etree #创建一个html对象 html=stree.HTML(text) result=etree.tostring(html,en ...
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
- python 爬取豆瓣电影评论,并进行词云展示及出现的问题解决办法
本文旨在提供爬取豆瓣电影<我不是药神>评论和词云展示的代码样例 1.分析URL 2.爬取前10页评论 3.进行词云展示 1.分析URL 我不是药神 短评 第一页url https://mo ...
- Python爬虫:现学现用xpath爬取豆瓣音乐
爬虫的抓取方式有好几种,正则表达式,Lxml(xpath)与BeautifulSoup,我在网上查了一下资料,了解到三者之间的使用难度与性能 三种爬虫方式的对比. 这样一比较我我选择了Lxml(xpa ...
- requests结合xpath爬取豆瓣最新上映电影
# -*- coding: utf-8 -*- """ 豆瓣最新上映电影爬取 # ul = etree.tostring(ul, encoding="utf-8 ...
- python3+requests+BeautifulSoup+mysql爬取豆瓣电影top250
基础页面:https://movie.douban.com/top250 代码: from time import sleep from requests import get from bs4 im ...
- 爬虫系列(六) 用urllib和re爬取百度贴吧
这篇文章我们将使用 urllib 和 re 模块爬取百度贴吧,并使用三种文件格式存储数据,下面先贴上最终的效果图 1.网页分析 (1)准备工作 首先我们使用 Chrome 浏览器打开 百度贴吧,在输入 ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
随机推荐
- PHP5+标准函数库观察者之实现
PHP的观察者设计模式实现相对简单,可是PHP5+版本号中已经有标准库类库支持,我们仅仅需简单继承并实现就能够了. 观察者:实现标准接口类库SplSubject. 一个注冊方法:attach.一个取消 ...
- MapReduce编程实战之“高级特性”
本篇介绍MapReduce的一些高级特性,如计数器.数据集的排序和连接.计数器是一种收集作业统计信息的有效手段.排序是MapReduce的核心技术,MapReduce也可以运行大型数据集间的" ...
- js获取单独一个checkbox是否被选中
<script language=javascript> function check(){ var xz=document.getElementById("xz"); ...
- 请求文件下载URL过长处理
/* * PostNewWin * Author:ppchen */var PostNewWin = function(url){ var urlArr = url.split("?& ...
- [POJ 1745] Divisbility
[题目链接] http://poj.org/problem?id=1745 [算法] DP [代码] #include <algorithm> #include <bitset> ...
- 给.Net Core添加Docker文件支持和运行
1.添加一个Dockerfile文件,将其移到解决方案文件夹,模板如下: FROM mcr.microsoft.com/dotnet/core/sdk:2.2 AS build WORKDIR /ap ...
- MYSQL 数据库命令行终端操作笔记
1.数据库登录: 1.登录本地的MYSQL数据库:mysql -u root -p 2.连接远程主机上的MYSQL数据库:mysql -h 192.168.191.2 -u root -p 123 ...
- pjax使用小结
简介 虽然传统的ajax方式可以异步无刷新改变页面内容,但无法改变页面URL,因此有种方案是在内容发生改变后通过改变URL的hash的方式获得更好的可访问性(如https://liyu365.gith ...
- [转载]Android平台第三方应用分享到微信开发
一.申请APPID 微信公共平台和微博分享一样,也需要申请一个ID,来作为调起微信.分享到微信的唯一标识. 申请微信APPID可以到微信平台http://open.weixin.qq.com/app/ ...
- 算法之dfs篇
dfs算法是深度搜索算法.从某一节点开始遍历直至到路径底部,如果不是所寻找的,则回溯到上个节点后,再遍历其他路径.不断重复这个过程.一般此过程消耗很大,需要一些优化才能保持算法的高效. hdu1010 ...