python 读取文件1
1、脚本
from sys import argv
script,filename = argv
txt = open(filename)
print ("the filename is %s" %filename)
print (txt.read())
print ("Type the filename again:")
file_again = input(">")
txt_again = open(file_again)
print(txt_again.read())
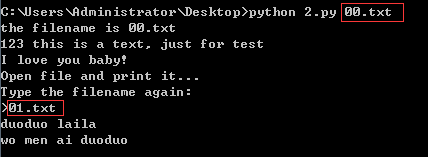
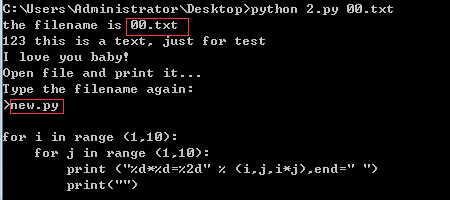
2、执行结果
3、备注
00.txt和01.txt,new.py都是我桌面的文档

4、读取个别文档时候,提示:UnicodeDecodeError: 'gbk' codec can't decode byte 0xa2 in position 50: illegal multibyte sequence
使用python的时候经常会遇到文本的编码与解码问题,其中很常见的一种解码错误如题目所示,下面介绍该错误的解决方法,将‘gbk’换成‘utf-8’也适用。
(1)首先在打开文本的时候,设置其编码格式,如:open(‘1.txt’,encoding=’gbk’);
(2)若(1)不能解决,可能是文本中出现的一些特殊符号超出了gbk的编码范围,可以选择编码范围更广的‘gb18030’,如:open(‘1.txt’,encoding=’gb18030’);
(3)若(2)仍不能解决,说明文中出现了连‘gb18030’也无法编码的字符,可以使用‘ignore’属性进行忽略,如:open(‘1.txt’,encoding=’gb18030’,errors=‘ignore’);
(4)还有一种常见解决方法为open(‘1.txt’).read().decode(‘gb18030’,’ignore’)
python 读取文件1的更多相关文章
- python 读取文件时报错UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 205: illegal multibyte sequence
python读取文件时提示"UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 205: illegal m ...
- 解决 python 读取文件乱码问题(UnicodeDecodeError)
解决 python 读取文件乱码问题(UnicodeDecodeError) 确定你的文件的编码,下面的代码将以'utf-8'为例,否则会忽略编码错误导致输出乱码 解决方案一 with open(r' ...
- python 读取文件read.csv报错 OSError: Initializing from file failed
小编在用python 读取文件read.csv的时候 报了一个错误 OSError: Initializing from file failed 初始化 文件失败 检查了文件路径,没问题 那应该是我文 ...
- python 读取文件时报错UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 205: illegal multib
python 读取文件时报错UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 205: illegal multib ...
- Python 读取文件中unicode编码转成中文显示问题
Python读取文件中的字符串已经是unicode编码,如:\u53eb\u6211,需要转换成中文时有两种方式 1.使用eval: eval("u"+"\'" ...
- python读取文件首行和最后一行
python读取文件最后一行两种方式 1)常规方法:从前往后依次读取 步骤:open打开文件. 读取文件,把文件所有行读入内存. 遍历所有行,提取指定行的数据. 优点:简单,方便 缺点:当文件大了以后 ...
- python操作txt文件中数据教程[3]-python读取文件夹中所有txt文件并将数据转为csv文件
python操作txt文件中数据教程[3]-python读取文件夹中所有txt文件并将数据转为csv文件 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 python操作txt文件中 ...
- 【python】python读取文件报错UnicodeDecodeError: 'gbk' codec can't decode byte 0xac in position 2: illegal multibyte sequence
python读取文件报错UnicodeDecodeError: 'gbk' codec can't decode byte 0xac in position 2: illegal multibyte ...
- python 读取文件时报错: UnicodeDecodeError: 'gbk' codec can't decode byte 0xa4 in position 127: illegal multibyte sequence
UnicodeDecodeError: 'gbk' codec can't decode byte 0xa4 in position 127: illegal multibyte sequence p ...
- Python读取文件编码及内容
Python读取文件编码及内容 最近做一个项目,需要读取文件内容,但是文件的编码方式有可能都不一样.有的使用GBK,有的使用UTF8.所以在不正确读取的时候会出现如下错误: UnicodeDecode ...
随机推荐
- MySQL8.0 DDL原子性特性
1. DDL原子性概述 8.0之前并没有统一的数据字典dd,server层和引擎层各有一套元数据,sever层的元数据包括(.frm,.opt,.par,.trg等),用于存储表定义,分区表定义,触发 ...
- 在java项目启动时就执行某操作
在java启动时大概有四种,此处只介绍3种 1.在启动的方法上使用通过@PostConstruct方法实现初始化bean进行操作 2.通过bean实现InitializingBean接口 @Overr ...
- Python 爬虫从入门到进阶之路(十一)
之前的文章我们介绍了一下 Xpath 模块,接下来我们就利用 Xpath 模块爬取<糗事百科>的糗事. 之前我们已经利用 re 模块爬取过一次糗百,我们只需要在其基础上做一些修改就可以了, ...
- Python操作ElasticSearch
Python批量向ElasticSearch插入数据 Python 2的多进程不能序列化类方法, 所以改为函数的形式. 直接上代码: #!/usr/bin/python # -*- coding:ut ...
- 利用切片操作,实现一个trim()函数,去除字符串首尾的空格,注意不要调用str的strip()方法
1.利用切片操作,实现一个trim()函数,去除字符串首尾的空格,注意不要调用str的strip()方法 首先判断字符串的长度是否为0,如果是,直接返回字符串 第二,循环判断字符串的首部是否有空格,如 ...
- python多线程爬取图片实例
今天试着把前面那个爬取图片的爬虫改成了多线程爬取,虽然最后可以爬取存储图片了,但仍存在一些问题.网址还是那个网址https://www.quanjing.com/category/1286521/1. ...
- mount -- 挂载理解
1.挂载? 在windows操作系统中, 挂载通常是指给磁盘分区(包括被虚拟出来的磁盘分区)分配一个盘符. 第三方软件,如磁盘分区管理软件.虚拟磁盘软件等,通常也附带挂载功能. 在linux操作系统中 ...
- Qt之股票组件-股票检索--支持预览框、鼠标、键盘操作
目录 一.感慨一下 二.效果展示 三.搜索编辑框 1.编辑框 2.预览框 四.相关文章 原文链接:Qt之股票组件-股票检索--支持预览框.鼠标.键盘操作 一.感慨一下 之前做过一款炒股软件,个人觉着是 ...
- Z点餐系统项目下期改进计划
随着计算机应用范围的日益广泛深人,应用软件的规模及复杂程度也日趋大型化.复杂化,这就导致软件开发的方式也从早期的单兵作战式或手工作坊式渐渐转变为集团化.工厂流水 问题: (一)缺乏项目管理系统培训.项 ...
- kuangbin专题 专题二 搜索进阶 哈密顿绕行世界问题 HDU - 2181
题目链接:https://vjudge.net/problem/HDU-2181 题意:一个规则的实心十二面体,它的 20个顶点标出世界著名的20个城市,你从一个城市出发经过每个城市刚好一次后回到出发 ...