Scrapy:创建爬虫程序的方式
Windows 10家庭中文版,Python 3.6.4,Scrapy 1.5.0,
在Scrapy中,建立爬虫程序或项目的方式有两种(在孤读过Scrapy的大部分文档后):
1.继承官方Spider类(5个)
2.命令行工具scrapy genspider(4个)
方式一:继承官方Spider类
下图是官网的示例:继承了scrapy.Spider
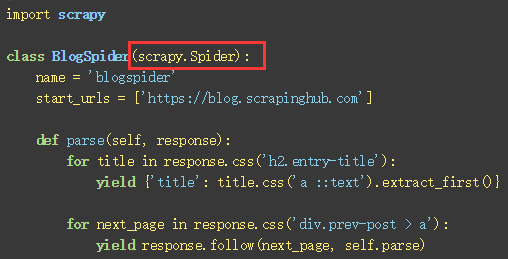
这里的scrapy.Spider是在scrapy包的__init__.py中导入的,实际上来自于scrapy.spiders.Spiders:

除了Spider类以外,scrapy内部还有几个Generic Spiders类:
-class scrapy.spiders.CrawlSpider
-class scrapy.spiders.XMLFeedSpider
-class scrapy.spiders.CSVFeedSpider
-class scrapy.spiders.SitemapSpider
上面的几个Spider类都可以被继承以实现自己的爬虫程序(目前自己不是很熟悉,仅在前面测试过SitemapSpider,但其官网SitemapSpider的示例没有name属性,故需要添加后才可以运行)。
更多资料:Scrapy官方Spiders文档
方式二:命令行工具scrapy genspider
还可以使用scrapy genspider命令建立爬虫程序。
在官文Command line tool介绍中,genspider是一个global命令,这意味着可以使用genspider在 Scrapy项目内 或 外 都可以建立爬虫程序。
下面几个配置项需要注意:
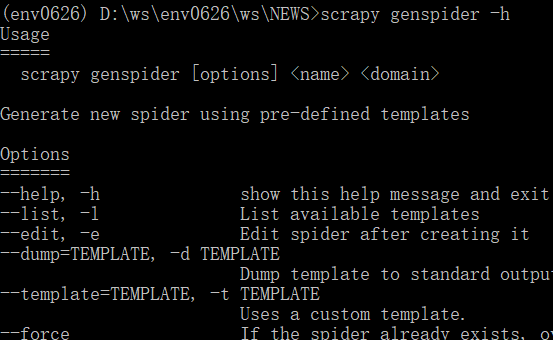
-scrapy genspider -h
genspider的帮助信息(下图展示了部分Usage信息)。
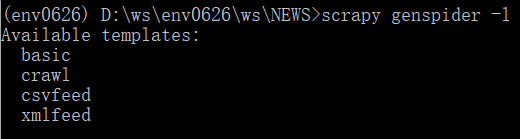
-scrapy genspider -l
显示可以使用的爬虫模板,就是 新建爬虫程序可以继承哪个内部爬虫类。这里存在一个疑问,没有SitemapSpider的模板。
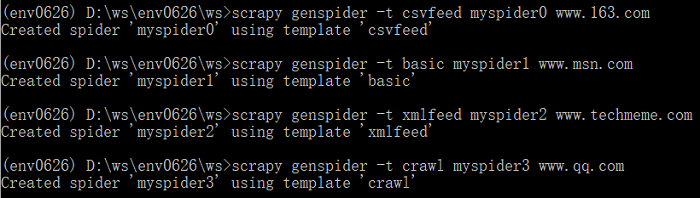
-scrapy genspider -t TEMPLATE ...
使用TEMPLATE对应的内部爬虫类建立爬虫程序(下图分别用四种模板建立了四个爬虫程序,其实,basic是默认的,可以不用写)。
打开其中的www.techmeme.com的爬虫程序看看:使用模板xmlfeed建立,继承了XMLFeedSpider。
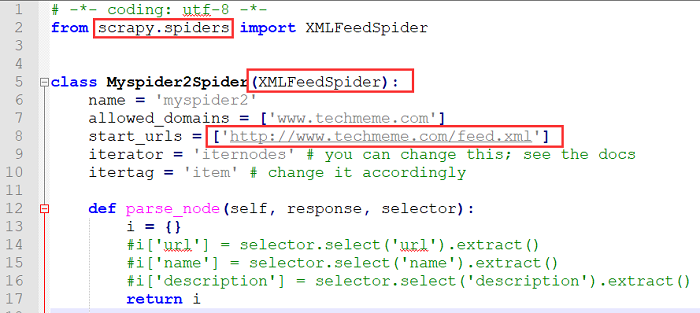
但这里存在问题:www.techmeme.com(一个很有名的科技资讯网站)的主页是HTTPS的,而这里的start_urls显示的是HTTP!
前面看资料说在DNS服务器还是什么地方可以配置自动跳转到HTTPS版本。 可是, 这里是否需要更改为HTTPS呢?孤认为是需要的!做 试验 验证会更好哦!)
注意,上面是使用genspider命令在项目外建立爬虫程序,而要在项目内建立爬虫程序时,需要选择Scrapy项目中的spiders目录,否则,无法自动检测到(按理说是这样,总不能在项目下的任何位置建立吧,项目要有项目的规矩)。
总结
从建立爬虫程序的效率来看,使用命令行的方式快速很多,但不能创建SitemapSpider类;
上面讲的都是 继承Scrapy内部的爬虫类, 那么,是否可以 继承自定义的爬虫类 呢?按理说是可以的,实际上也应该可以,需要验证;
无论哪种方式,都需要后续更多的coding工作,因此,在继续之前,请熟悉Scrapy的爬虫的工作机制,见官文Spiders;
如果还有更多的方式,或者,读者自己研发的方式,欢迎告知,会很感激;
当然,使用其它命令行工具也可以建立一些看不见的爬虫程序,就不是本文所涉及的了,需要更理解Scrapy才可以。
0704-0951 Update
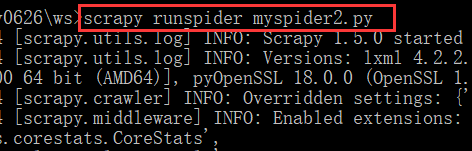
关于www.techmeme.com的爬虫程序,使用runspider进行了测试:
-默认的HTTP时会发生 重定向(302)

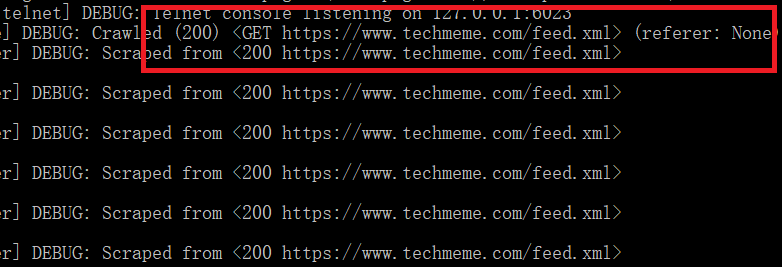
-更改为HTTPS后则不会 发生 重定向
也可以使用scrapy parse命令进行测试,但是,首先要将上面的myspider2放到某个Scrapy项目的spiders目录下:
scrapy parse --spider=myspider2 -d 3 "https://www.techmeme.com"
Scrapy:创建爬虫程序的方式的更多相关文章
- Scrapy:运行爬虫程序的方式
Windows 10家庭中文版,Python 3.6.4,Scrapy 1.5.0, 在创建了爬虫程序后,就可以运行爬虫程序了.Scrapy中介绍了几种运行爬虫程序的方式,列举如下: -命令行工具之s ...
- 使用scrapy 创建爬虫项目
使用scrapy 创建爬虫项目 步骤一: scrapy startproject tutorial 步骤二: you can start your first spider with: cd tuto ...
- Scrapy创建爬虫项目
1.打开cmd命令行工具,输入scrapy startproject 项目名称 2.使用pycharm打开项目,查看项目目录 3.创建爬虫,打开CMD,cd命令进入到爬虫项目文件夹,输入scrapy ...
- Scrapy框架-爬虫程序相关属性和方法汇总
一.爬虫项目类相关属性 name:爬虫任务的名称 allowed_domains:允许访问的网站 start_urls: 如果没有指定url,就从该列表中读取url来生成第一个请求 custom_se ...
- 使用Scrapy编写爬虫程序中遇到的问题及解决方案记录
1.创建与域名不一致的Request时,请求会报错 解决方法:创建时Request时加上参数dont_filter=True 2.当遇到爬取失败(对方反爬检测或网络问题等)时,重试,做法为在解析res ...
- scrapy工具创建爬虫工程
1.scrapy创建爬虫工程:scrapy startproject scrape_project_name >scrapy startproject books_scrapeNew Scrap ...
- 第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令 Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --u ...
- 十 web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --upgrade pip2.安装,wheel(建议网络安装) pip install wheel ...
- liunx系统下crontab定时启动Scrapy爬虫程序
定时启动爬虫 # 查看命令得绝对路径 # which scrapy # cd到爬虫得项目目录下 + scrapy命令得绝对路径 + 启动命令 */5 * * * * cd /opt/mafengwo/ ...
随机推荐
- Nagios通过企业微信报警
主要分两部分进行: 注册企业微信,自建应用,获取与发送消息相关的信息: 编写调用微信API脚本(bash),配置Nagios微信报警: 一.企业微信 1.注册企业微信:https://work.wei ...
- 【BZOJ1054】移动玩具(搜索)
[BZOJ1054]移动玩具(搜索) 题面 BZOJ 洛谷 题解 这种小清新搜索题写出来好舒服啊. 要是原来的我来写代码肯定又臭又长吧.. #include<cstdio> #includ ...
- git pull 总要求输入账号和密码解决?
如果你用git从远程pull拉取代码,每次都要输入密码,那么执行下面命令即可 git config --global credential.helper store 这个命令则是在你的本地生成一个账号 ...
- APK反编译之二:工具介绍
前面一节我们说过,修改APK最终是通过修改smali来实现的,所以我们接下来介绍的工具就是如何把APK中的smali文件获取出来,当然同时也需要得到AndroidManifest.xml等文件.直接修 ...
- python之旅:绑定方法与非绑定方法
一 类中定义的函数分成两大类 一:绑定方法(绑定给谁,谁来调用就自动将它本身当作第一个参数传入): 1. 绑定到类的方法:用classmethod装饰器装饰的方法. 为 ...
- 2:spring中的@resource
@Resource 其实是spring里面的注解注入. @Resource(这个注解属于J2EE的),默认安照名称进行装配,名称可以通过name属性进行指定, 如果没有指定name属性,当注解写在字段 ...
- Netflix的zuul使用
1.zuul出现的原因 2.zuul的介绍 3.zuul如何使用 4.zuul的一些注意事项
- HTML常用标签-<head>内常用标签
HTML常用标签-<head>内常用标签 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HTML是什么 1>.超文本标记语言(Hypertext Ma ...
- Linux QT数据库之登录注册
视频链接:https://www.bilibili.com/video/av11673511/ main.cpp #include <QSqlDatabase> #include < ...
- day9 类、对象、包
结构化编程中,程序围绕要解决的问题来设计. 面向对象编程,围绕要解决问题的对象来设计. 万物皆对象,对象因关注而产生!!! 类——抽取具有相同属性和行为的对象. 属性就是对象身上的值数据,行为就是对象 ...