ubuntu之路——day10.2单一数字评估指标与满足和优化的评估指标
单一数字评估指标:
FP:错误地标记为正,即算法预测它是好西瓜,但这个西瓜真实情况是坏西瓜;
FN:错误地标记为负,即算法预测为坏西瓜,(F算法预测的不对)但这个西瓜真实情况是好西瓜(双重否定也是肯定);
TN:正确地标记为负,即算法标记为坏西瓜,(T算法预测的正确)这个西瓜真实情况是坏西瓜。
所以有:



当beta>1时查全率重要,beta<1时查准率重要
以上关于精度、查准率、查全率的论述转自https://blog.csdn.net/qq_27871973/article/details/81065074 总结的很好所以我没有改动。
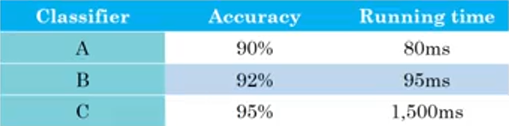
首先Accuracy也可以是上述单一数字评估指标中的任何一种,然后我们又得到了算法的时间性能running time。在这两种条件下如何综合衡量模型的好坏呢?
第一种方法:
线性叠加的思路:cost = Accuracy - 0.5Running time
当然这种线性加权求和的方式显得有些武断
第二种方法:
满足和优化的思路:cost = max(Accuracy) && Running time < 100
这种思路下,认为Accuracy是一种优化指标optimizing metric,同时Running time是一种满足指标satisficing metric,因为只要其满足了条件之后无论多好我们不再关注。
总结一下:当你有N个指标去考量的时候,通常选取其中的1种作为优化指标,剩下的N-1都是满足指标
ubuntu之路——day10.2单一数字评估指标与满足和优化的评估指标的更多相关文章
- ubuntu之路——day10.7 提高模型的表现
总结一下就是在提升偏差的方面(即贝叶斯最优误差和训练误差的差距) 1.尝试更大更深的网络 2.加入优化算法比如前面提过的momentum.RMSprop.Adam等 3.使用别的神经网络架构比如RNN ...
- ubuntu之路——day10.6 如何理解人类表现和超过人类表现
从某种角度来说,已知的人类最佳表现其实可以被当做贝叶斯最优错误,对于医学图像分类可以参见下图中的例子. 那么如何理解超过人类表现,在哪些领域机器已经做到了超越人类呢?
- ubuntu之路——day10.5 可避免偏差
可避免偏差: 总结一下就是当贝叶斯最优误差接近于训练误差的时候,比如下面的例子B,我们不会说我们的训练误差是8%,我们会说我可避免偏差是0.5%.
- ubuntu之路——day10.4 什么是人的表现
结合吴恩达老师前面的讲解,可以得出一个结论: 在机器学习的早期阶段,传统的机器学习算法在没有赶超人类能力的时候,很难比较这些经典算法的好坏.也许在不同的数据场景下,不同的ML算法有着不同的表现. 但是 ...
- ubuntu之路——day10.3 train/dev/test的划分、大小和指标更新
train/dev/test的划分 我们在前面的博文中已经提到了train/dev/test的相关做法.比如不能将dev和test混为一谈.同时要保证数据集的同分布等. 现在在train/dev/t ...
- ubuntu之路——day10.1 ML的整体策略——正交化
orthogonalization 正交化的概念就是指,将你可以调整的参数设置在不同的正交的维度上,调整其中一个参数,不会或几乎不会影响其他维度上的参数变化,这样在机器学习项目中,可以让你更容易更快速 ...
- [DeeplearningAI笔记]ML strategy_1_1正交化/单一数字评估指标
机器学习策略 ML strategy 觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.1 什么是ML策略 机器学习策略简介 情景模拟 假设你正在训练一个分类器,你的系统已经达到了90%准确 ...
- Python之路,Day10 - 异步IO\数据库\队列\缓存
Python之路,Day9 - 异步IO\数据库\队列\缓存 本节内容 Gevent协程 Select\Poll\Epoll异步IO与事件驱动 Python连接Mysql数据库操作 RabbitM ...
- python之路-Day10
操作系统发展史介绍 进程.与线程区别 python GIL全局解释器锁 线程 语法 join 线程锁之Lock\Rlock\信号量 将线程变为守护进程 Event事件 queue队列 生产者消费者模型 ...
随机推荐
- src属性与浏览器渲染
img标签 只要设置了src属性, 就会开始下载,因此可以使用这个特性,配合display:none,默默的下载一些图片,用的时候直接用,快了那么一丢丢~ 注意:不一定要添加到文档后才会开始下载,是只 ...
- with读、写文件
1.with写文件 save_file = "1.txt" str_data = "123a\nbc" with open(save_file, 'a', en ...
- ffmpeg常用命令-学习
文章标题:FFmpeg常用命令合集 文章地址:https://blog.csdn.net/lemon_tree12138/article/details/99719520
- JAVA对象结构
对象的内存布局 在HotSpot虚拟机中,对象在内存中存储的布局可以分为3块区域:对象头(Header),实例数据(Instance Data)和对象填充(Padding). 实例数据:对象真正存储的 ...
- 零基础Python教程-函数及模块的使用
函数 在学习本节内容之前,我们先来一起做道数学题. 已知:半径分别为0.1.0.2.0.3的三个圆,分别求这三个圆的面积. 很多读者可能要笑一下,这不是小学的数学问题吗? S = π * r * r ...
- 用指针形式实现strstr函数
char * mystrstr(char *dest,char * src){ char *p=null; char * temp=src; while(*dest)//只要不为'\0'就行 { p= ...
- vbs读取TXT每一行并赋值到变量a
vbs代码: Dim fso,f,a Set fso = CreateObject("Scripting.FileSystemObject") Set f=fso.OpenText ...
- mysql 杂记 —— 时区问题
查看时区: SHOW VARIABLES LIKE "%time_zone%"; 输出 Variable_name Value system_time_zone CST time_ ...
- SSMS开发利器Sql Prompt
一.前言 一个Sql Server 开发智能提示插件,方便查询表结果,避免了开发人员一个个敲查询语句.执行语句等,一起来看看吧. SQL Prompt 9.5 支持SSMS18 下载地址: 链接:ht ...
- PHP 判断终端是手机还是电脑访问网站代码
用thinkphp做底层框架,判断客户是用pc访问还是手机访问的. <?php $platform = platform();//检测访问平台 //print_r($_SERVER);DIE; ...