python爬虫实例——爬取歌单
学习自<<从零开始学python网络爬虫>>
爬取酷狗歌单,保存入csv文件
直接上源代码:(含注释)
import requests #用于请求网页获取网页数据
from bs4 import BeautifulSoup #解析网页数据
import time #time库中的sleep()方法可以让程序暂停
import csv '''
爬虫测试
酷狗top500数据
写入csv文件
'''
fp = open('D://kugou.csv','wt',newline='',encoding='utf-8')#创建csv
writer = csv.writer(fp)
writer.writerow(('rank','singer','song','time'))
#加入请求头
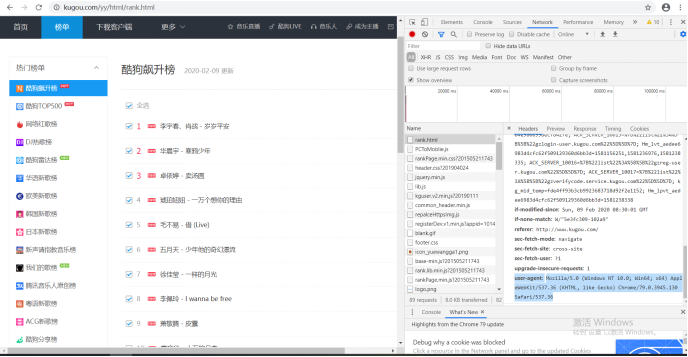
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'
} #定义获取信息的函数
def get_info(url):
wb_data = requests.get(url,headers=headers)#get方法加入请求头
soup = BeautifulSoup(wb_data.text,'html.parser')#对返回结果进行解析
#定位元素位置并通过selector方法获取
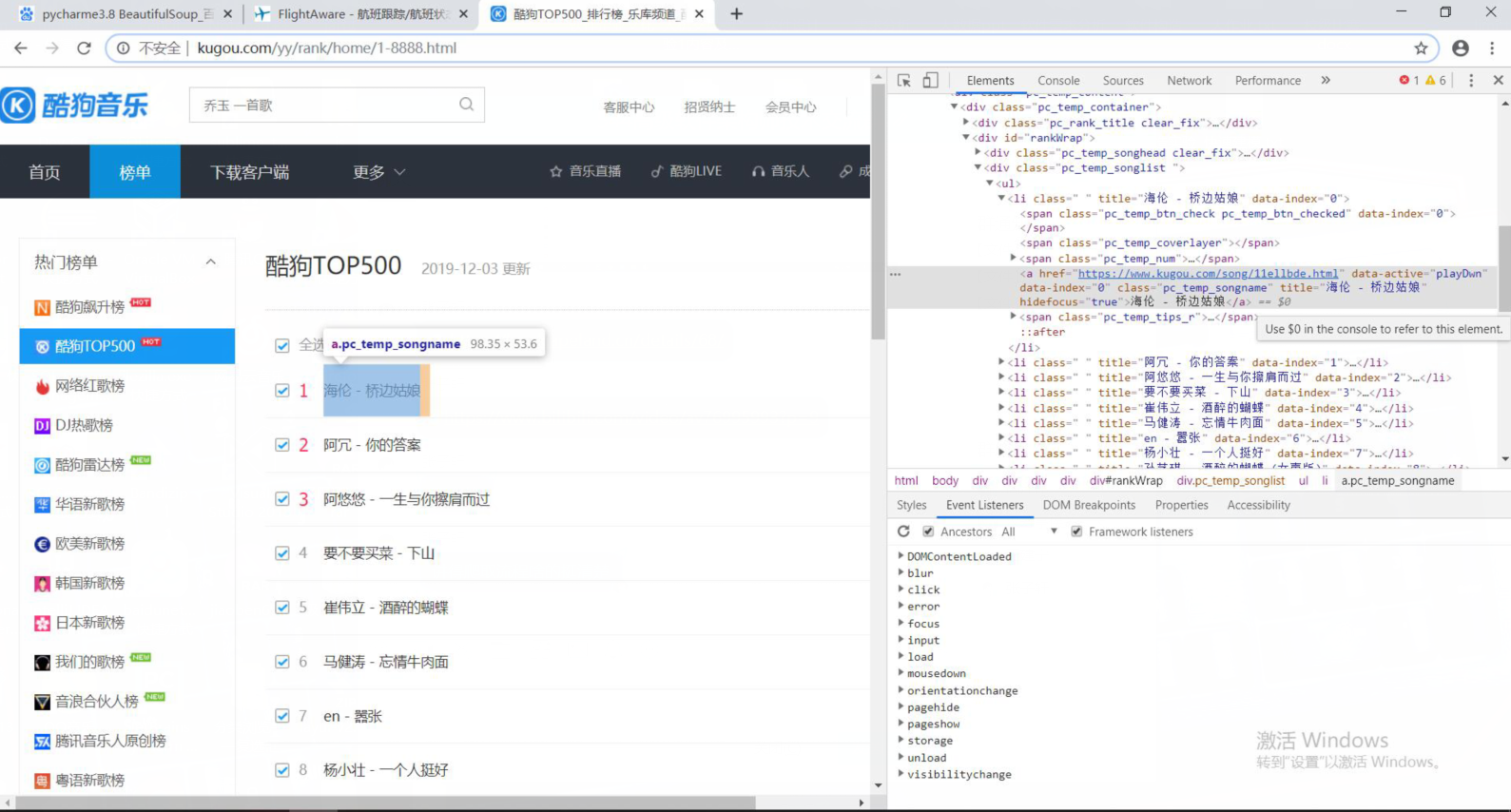
ranks = soup.select('span.pc_temp_num')
titles = soup.select('div.pc_temp_songlist > ul > li > a')
times = soup.select('span.pc_temp_tips_r > span')
for rank,title,time in zip(ranks,titles,times):
data = {
'rank':rank.get_text().strip(),
'singer':title.get_text().split('-')[0],
'song':title.get_text().split('-')[0],#通过split获取歌手和歌曲信息
'time':time.get_text().strip()#get_text()获取文本内容
}
writer.writerow((rank.get_text().strip(),title.get_text().split('-')[0],title.get_text().split('-')[0],time.get_text().strip()))
# 获取爬取信息并按字典格式打印
#print(data) #程序主入口
if __name__ == '__main__':
urls = ['http://www.kugou.com/yy/rank/home/{}-8888.html'.format(str(i)) for i in range(1,4)]#构造多页url
for url in urls:
get_info(url)#循环调用
time.sleep(1)#每循环一次,睡眠1秒,防止网页浏览频率过快导致爬虫失败
爬虫实例
浏览器:Chrome
请求头获取方法:
网站爬取:
python爬虫实例——爬取歌单的更多相关文章
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- Python爬虫之爬取站内所有图片
title date tags layut Python爬虫之爬取站内所有图片 2018-10-07 Python post 目标是 http://www.5442.com/meinv/ 如需在非li ...
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
- Python爬虫之爬取淘女郎照片示例详解
这篇文章主要介绍了Python爬虫之爬取淘女郎照片示例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 本篇目标 抓取淘宝MM ...
- python爬虫项目-爬取雪球网金融数据(关注、持续更新)
(一)python金融数据爬虫项目 爬取目标:雪球网(起始url:https://xueqiu.com/hq#exchange=CN&firstName=1&secondName=1_ ...
- Python 2.7_爬取CSDN单页面博客文章及url(二)_xpath提取_20170118
上次用的是正则匹配文章title 和文章url,因为最近在看Scrapy框架爬虫 需要了解xpath语法 学习了下拿这个例子练手 1.爬取的单页面还是这个rooturl:http://blog.csd ...
- Python 2.7_爬取CSDN单页面利用正则提取博客文章及url_20170114
年前有点忙,没来的及更博,最近看爬虫正则的部分 巩固下 1.爬取的单页面:http://blog.csdn.net/column/details/why-bug.html 2.过程 解析url获得网站 ...
随机推荐
- [转帖]k8s 如何让你的应用活的更久
k8s 如何让你的应用活的更久 https://www.jianshu.com/p/132319e795ae 众所周知,k8s 可以托管你的服务 / 应用,当出现各种原因导致你的应用挂掉之后,k8s ...
- Mysql插入text类型字段错误记录 com.mysql.jdbc.MysqlDataTruncation: Data truncation: #22001
一次插入操作报如下错误 com.mysql.jdbc.MysqlDataTruncation: Data truncation: #22001 是说字段值长度超过限制. MySQL TEXT数据类型的 ...
- WPF DataGird 类似Excel筛选效果 未成品
这个本是针对MSDN上所写的代码,不过写一半不想写了. 不想浪费代码,是个半成品的半成品. 效果图: 思路: 利用PopUp来做显示层. 显示层中的数据则是绑定到Datagrid的数据. popup中 ...
- 【ELK】elasticsearch中使用脚本报错:scripts of type [inline], operation [update] and lang [groovy] are disabled
查看ID为2的这条数据: 使用更新命令: 使用脚本对年龄+5 curl -XPOST http://192.168.6.16:9200/my_new_index/user/2/_update?pret ...
- SUSE 中文是乱码
http://www.wo81.com/tec/os/suse/2014-04-30/186.html 操作系统:SUSE Linux Enterprise 11 问题:vi 打开文件,中文是乱码 ...
- Asp.Net Core中使用NLog记录日志
2019/10/28, Asp.Net Core 3.0, NLog 4.6.7, NLog.Web.AspNetCore 4.9.0 摘要:NLog在asp.net网站中的使用,NLog日志写入数据 ...
- 华为 鸿蒙系统(HarmonyOS)
HarmonyOS Ⅰ. 鸿蒙系统简介 鸿蒙系统(HarmonyOS),是第一款基于微内核的全场景分布式OS,是华为自主研发的操作系统.2019年8月9日,鸿蒙系统在华为开发者大会<HDC.20 ...
- 网络编程——TCP协议、UDP协议、socket套接字、粘包问题以及解决方法
网络编程--TCP协议.UDP协议.socket套接字.粘包问题以及解决方法 TCP协议(流式协议) 当应用程序想通过TCP协议实现远程通信时,彼此之间必须先建立双向通信通道,基于该双向通道实现数 ...
- APS系统帮助寻找企业最优库存
零库存模式的实施要有深厚的民族文化和企业文化为支点.随着对零库存管理研究的深入,就会发现它不仅仅是一种运营管理技术,更是一种文化.一种哲学. 当这种认同文化体现在企业与企业之间时,就会表现出彼此的认同 ...
- 开机注册联通2G网络
2/3G PLMN LIST 在MM_RATCM_PLMN_LIST_CNF或NWSEL_MM_PLMN_SEARCH_CNF消息中可以查看2,3G搜到的PLMN LIST 内容如下: RAT:Rad ...