postgresql大数据查询加索引和不加索引耗时总结
1、创建测试表
CREATE TABLE big_data
(
id character varying(50) NOT NULL,
name character varying(50),
datetime timestamp with time zone,
CONSTRAINT big_data_pkey PRIMARY KEY (id)
)
WITH (
OIDS=FALSE
);
ALTER TABLE big_data
OWNER TO postgres;
2、创建插入数据函数
CREATE OR REPLACE FUNCTION insert_bigdata()
RETURNS text AS
$BODY$
declare ii integer;
declare jj integer;
begin
ii = 1;
jj = 1;
FOR ii IN 1..10 LOOP
FOR jj IN 1..10000 LOOP
INSERT INTO big_data values(uuid_generate_v4(), 'lisi'||jj, now());
END LOOP;
END LOOP;
RETURN 'success';
end;
$BODY$
LANGUAGE plpgsql VOLATILE
COST 100;
ALTER FUNCTION insert_bigdata()
OWNER TO postgres;
3、插入一千万条数据(修改函数中的循环次数,多执行几次,插入需要的数据)
select insert_bigdata();
4、给name字段不加索引和加索引分别统计执行时间
查询结果10条记录
select * from big_data where name='lisi10';
查询结果100条记录
select * from big_data where name='lisi100';
查询结果1000条记录
select * from big_data where name='lisi1000';
查询结果10000条记录
select * from big_data where name='lisi10000';
查询结果100000条记录
select * from big_data where name='lisi100000';
耗时统计表(单位/毫秒)

耗时统计图
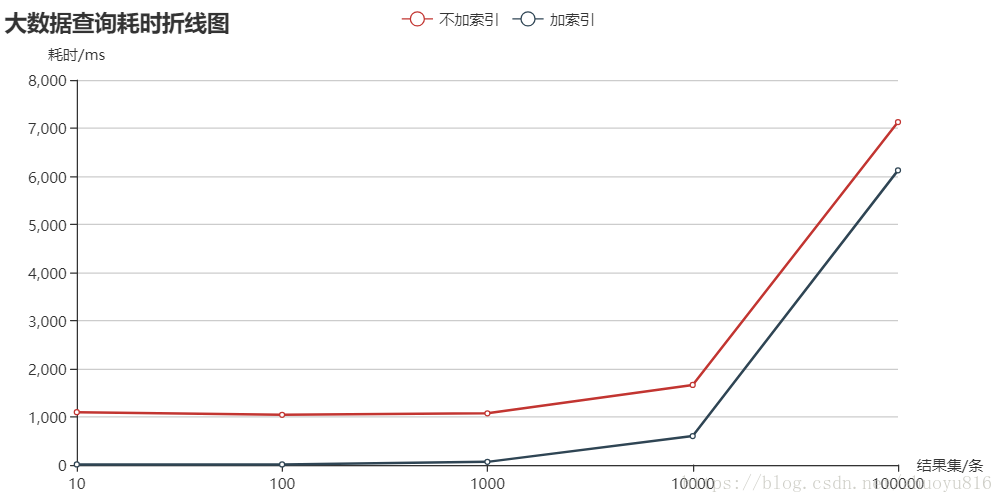
5、结果总结
在查询结果小于1000条记录时,加索引会大幅度提高查询效率。
在查询结果大于1000条记录时,加索引对查询效率的提升逐渐减小,尤其是超过10000条时,使用索引后的查询时间也比较长。
当前结果仅适用于创建的big_data这张数据表(如果数据表中字段比较多,数据量比较大,会在更小的查询结果记录数出现加索引查询效率提升不明显的问题)。
————————————————
版权声明:本文为CSDN博主「朔语」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/shuoyu816/article/details/82793968
postgresql大数据查询加索引和不加索引耗时总结的更多相关文章
- mysql 5.7 innodb count count(*) count(1) 大数据 查询慢 耗时多 优化
原文:mysql 5.7 innodb count count(*) count(1) 大数据 查询慢 耗时多 优化 问题描述 mysql 5.7 innodb 引擎 使用以下几种方法进行统计效率差不 ...
- SQL命令语句进行大数据查询如何进行优化
SQL 大数据查询如何进行优化? 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索 2.应尽量避免在 where 子句中对字段进行 null 值 ...
- 海胜专访--MaxCompute 与大数据查询引擎的技术和故事
摘要:在2019大数据技术公开课第一季<技术人生专访>中,阿里巴巴云计算平台高级技术专家苑海胜为大家分享了<MaxCompute 与大数据查询引擎的技术和故事>,主要介绍了Ma ...
- Facebook 正式开源其大数据查询引擎 Presto
Facebook 正式宣布开源 Presto —— 数据查询引擎,可对250PB以上的数据进行快速地交互式分析.该项目始于 2012 年秋季开始开发,目前该项目已经在超过 1000 名 Faceboo ...
- 比hive快10倍的大数据查询利器presto部署
目前最流行的大数据查询引擎非hive莫属,它是基于MR的类SQL查询工具,会把输入的查询SQL解释为MapReduce,能极大的降低使用大数据查询的门槛, 让一般的业务人员也可以直接对大数据进行查询. ...
- 技术分享:如何用Solr搭建大数据查询平台
0×00 开头照例扯淡 自从各种脱裤门事件开始层出不穷,在下就学乖了,各个地方的密码全都改成不一样的,重要帐号的密码定期更换,生怕被人社出祖宗十八代的我,甚至开始用起了假名字,我给自己起一新网名”兴才 ...
- SQL大数据查询分页存储过程
最后一页分页一卡死,整个网站的性能都会非常明显的下降,不知道为啥,微软有这个BUG一直没处理好.希望SQL2012里不要有这个问题就好了. 参考代码如下: -- =================== ...
- 大数据查询——HBase读写设计与实践
导语:本文介绍的项目主要解决 check 和 opinion2 张历史数据表(历史数据是指当业务发生过程中的完整中间流程和结果数据)的在线查询.原实现基于 Oracle 提供存储查询服务,随着数据量的 ...
- mysql 大数据 查询方面的测试
---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适应场景: 适用于数据量较少的情况(元组百/千 ...
随机推荐
- HTML&CSS基础-CSS的语法
HTML&CSS基础-CSS的语法 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.dome.html源代码 <!DOCTYPE html> <html ...
- Linux中快速对字符串进行加密
1)进行base64的加密和解密 [root@VM_0_10_centos opt]# echo hello |base64aGVsbG8K[root@VM_0_10_centos opt]# ech ...
- commons-io之FileUtils、IOUtils
原文:https://blog.csdn.net/justry_deng/article/details/93616705 commons-io简单说明:Common IO 是一个工具库,用来帮助开发 ...
- SOA=SOME/IP?你低估了这件事 | 第二弹
哈喽,大家好,第二弹的时间到~上文书说到v-SOA可以通过SOC.SORS和SOS来分解落地,第一弹中已经聊了SOC的实现,这部分也是国内各大OEM正在经历的阶段,第二弹,我们继续聊 ...
- 题解 洛谷P1281 【书的复制】
蒟蒻的\(DP\)很菜,\(SO\)我准备上一套二分的玄学操作 一.简单的二分答案 二分主要是用来解决一些最值问题,它可以有效的优化暴力,使复杂度减少到\(O(logn)\). 我先给大家介绍一下二分 ...
- ajax同步与异步的区别
jquery中ajax方法有个属性async用于控制同步和异步,默认是true,即ajax请求默认是异步请求,有时项目中会用到AJAX同步.这个同步的意思是当JS代码加载到当前AJAX的时候会把页面里 ...
- URI与URN与URL详解
当没有URI时 什么是URI和URN和URL URI详解 Uniform Resource Identifier 统一资源标识符 URI的组成 案例: https://tools.ietf.org/h ...
- Coins in a Line
Description There are n coins in a line. Two players take turns to take one or two coins from right ...
- [React] Write a Custom React Effect Hook
Similar to writing a custom State Hook, we’ll write our own Effect Hook called useStarWarsQuote, whi ...
- Go奇技淫巧
判断io读取是否结束,尽量用if n==0这种方式,因为可以判断很多种情况 package main import ( "fmt" "io" "net ...