Ubuntu16.04 下 hadoop的安装与配置(伪分布式环境)
一、准备
1.1创建hadoop用户
$ sudo useradd -m hadoop -s /bin/bash #创建hadoop用户,并使用/bin/bash作为shell
$ sudo passwd hadoop #为hadoop用户设置密码,之后需要连续输入两次密码
$ sudo adduser hadoop sudo #为hadoop用户增加管理员权限
$ su - hadoop #切换当前用户为用户hadoop
$ sudo apt-get update #更新hadoop用户的apt,方便后面的安装
1.2安装SSH,设置SSH无密码登陆
$ sudo apt-get install openssh-server #安装SSH server
$ ssh localhost #登陆SSH,第一次登陆输入yes
$ exit #退出登录的ssh localhost
$ cd ~/.ssh/ #如果没法进入该目录,执行一次ssh localhost
$ ssh-keygen -t rsa
输入完 $ ssh-keygen -t rsa 语句以后,需要连续敲击三次回车,如下图:

其中,第一次回车是让KEY存于默认位置,以方便后续的命令输入。第二次和第三次是确定passphrase,相关性不大。两次回车输入完毕以后,如果出现类似于下图所示的输出,即成功:
之后再输入:
$ cat ./id_rsa.pub >> ./authorized_keys #加入授权
$ ssh localhost #此时已不需密码即可登录localhost,并可见下图。如果失败则可以搜索SSH免密码登录来寻求答案
二、安装jdk1.7
首先在oracle官网下载jdk1.7 http://www.oracle.com/technetwork/java/javase/downloads/index.html 接下来进行安装与环境变量配置,根据个人电脑系统选择对应版本,我选的是jdk-7u80-linux-x64.tar.gz
$ mkdir /usr/lib/jvm #创建jvm文件夹
$ sudo tar zxvf jdk-7u80-linux-x64.tar.gz -C /usr/lib #/ 解压到/usr/lib/jvm目录下
$ cd /usr/lib/jvm #进入该目录
$ mv jdk1.7.0_80 java #重命名为java
$ vi ~/.bashrc #给JDK配置环境变量
注:其中如果权限不够,无法在相关目录下创建jvm文件夹,那么可以使用 $ sudo -i 语句进入root账户来创建文件夹。
另外推荐使用vim来编辑环境变量,即最后一句使用指令
$ vim ~/.bashrc
如果没有vim,可以使用:
$sudo apt-get install vim
来进行下载。
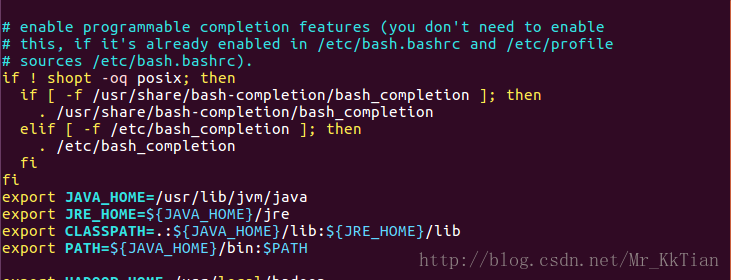
在.bashrc文件添加如下指令:
export JAVA_HOME=/usr/lib/jvm/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
在文件修改完毕以后,输入代码:
$ source ~/.bashrc #使新配置的环境变量生效
$ java -version #检测是否安装成功,查看java版本
如果出现如下图所示的内容,即为安装成功

注:如果各位不想一个一个的敲击,可以复制黏贴,但因为vim不支持系统粘贴板,所以需要先下载相关插件vim-gnome
sudo apt-get install vim-gnome
然后复制相关代码,光标移到指定位置,使用指令 "+p,即可复制,注意 " 也是需要敲击的内容,即一共有 " 、+、p 三个操作符需要敲入
三、安装hadoop-2.6.0
先下载hadoop-2.6.0.tar.gz,链接如下:
http://mirrors.hust.edu.cn/apache/hadoop/common/
下面进行安装:
$ sudo tar -zxvf hadoop-2.6.0.tar.gz -C /usr/local #解压到/usr/local目录下
$ cd /usr/local
$ sudo mv hadoop-2.6.0 hadoop #重命名为hadoop
$ sudo chown -R hadoop ./hadoop #修改文件权限
给hadoop配置环境变量,将下面代码添加到.bashrc文件:
export HADOOP_HOME=/usr/local/hadoop
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

同样,执行source ~./bashrc使设置生效,并查看hadoop是否安装成功

四、伪分布式配置
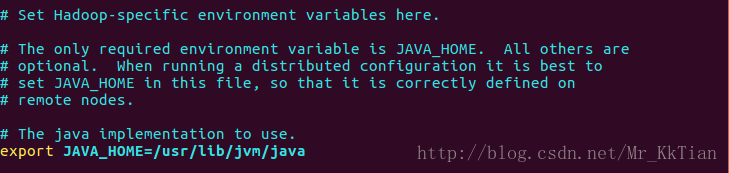
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。首先将jdk1.7的路径添(export JAVA_HOME=/usr/lib/jvm/java )加到hadoop-env.sh文件
接下来修改core-site.xml文件:

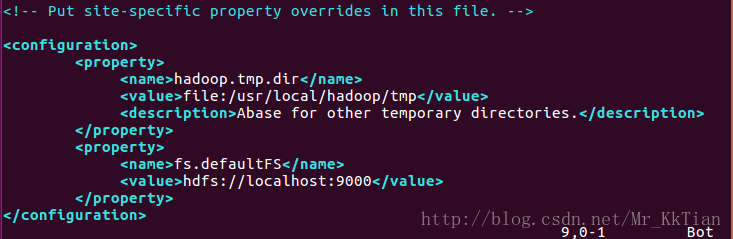
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
接下来修改配置文件 hdfs-site.xml
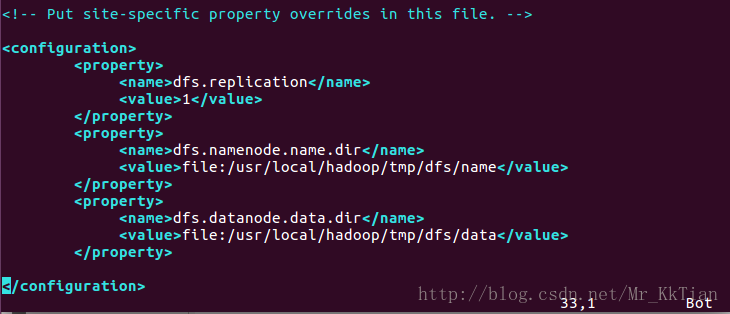
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(可参考官方教程),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
配置完成后,执行 NameNode 的格式化
$ ./bin/hdfs namenode -format
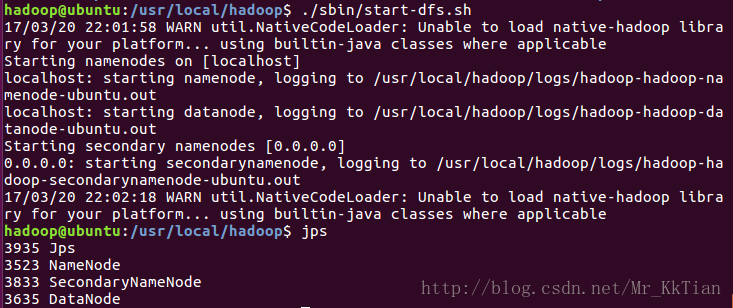
启动namenode和datanode进程,并查看启动结果
$ ./sbin/start-dfs.sh
$ jps
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”
此时也有可能出现要求输入localhost密码的情况 ,如果此时明明输入的是正确的密码却仍无法登入,其原因是由于如果不输入用户名的时候默认的是root用户,但是安全期间ssh服务默认没有开root用户的ssh权限
输入代码:
$vim /etc/ssh/sshd_config
检查PermitRootLogin 后面是否为yes,如果不是,则将该行代码 中PermitRootLogin 后面的内容删除,改为yes,保存。之后输入下列代码重启SSH服务:
$ /etc/init.d/sshd restart
即可正常登入(免密码登录参考第一章)
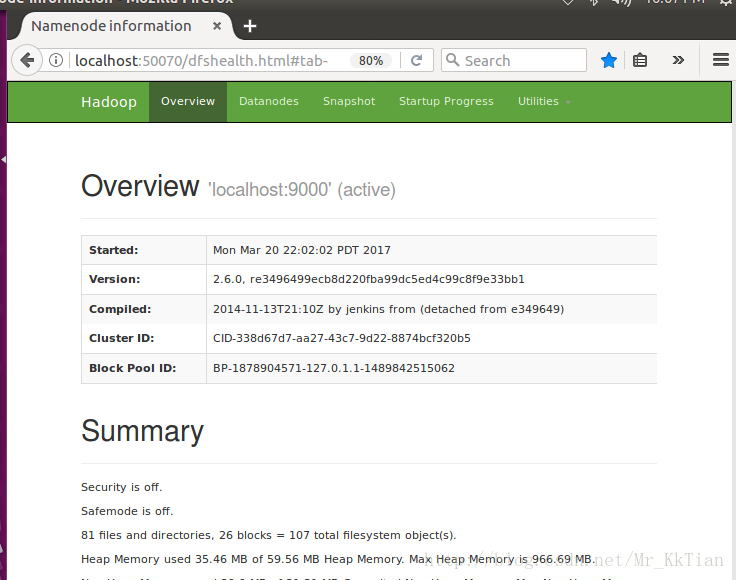
成功启动后,可以访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
至此,hadoop的安装就已经完成啦!enjoy it!
from https://www.cnblogs.com/87hbteo/p/7606012.html
Ubuntu16.04 下 hadoop的安装与配置(伪分布式环境)的更多相关文章
- ubuntu16.04下sublime text3安装和配置
ubuntu16.04下sublime text3安装和配置 2018年04月20日 10:31:08 zhengqijun_ 阅读数:1482 1.安装方法 1)使用ppa安装 sudo add-a ...
- Ubuntu16.04下Kylin的安装与配置
一.系统环境 kylin的安装配置并不像官方文档中描述的那样简单,复杂的原因在于hadoop,hive,hbase,kylin的版本一定要兼容,不然就会出现各种奇怪的错误.以下各软件版本可以成功运行k ...
- Ubuntu16.04下HBase的安装与配置
一.环境 os : Ubuntu 16.04 LTS 64bit jdk : 1.8.0_161 hadoop : mysql : hive : hbase: -hadoop2 安装HBase前,系统 ...
- Ubuntu16.04下Hive的安装与配置
一.系统环境 os : Ubuntu 16.04 LTS 64bit jdk : 1.8.0_161 hadoop : 2.6.4mysql : 5.7.21 hive : 2.1.0 在配置hive ...
- ubuntu16.04下vim的安装与配置
一.安装vim 使用命令 $ sudo apt-get install vim 来安装vim,安装后的vim需要进行一些配置,不然使用起来会有些不方便,比如不会自动缩进. 二.配置vim 使用命令 ...
- Ubuntu16.04下,erlang安装和rabbitmq安装步骤
文章来源: Ubuntu16.04下,erlang安装和rabbitmq安装步骤 准备工作,先下载erlang和rabbitmq的安装包,注意他们的版本,版本不对可能会导致rabbitmq无法启动,这 ...
- Ubuntu 14.04 下 android studio 安装 和 配置【转】
本文转载自:http://blog.csdn.net/xueshanfeihu0/article/details/52979717 Ubuntu 14.04 下 android studio 安装 和 ...
- Ubuntu16.04下Hadoop的本地安装与配置
一.系统环境 os : Ubuntu 16.04 LTS 64bit jdk : 1.8.0_161 hadoop : 2.6.4 部署时使用的用户名为hadoop,下文中需要使用用户名的地方请更改为 ...
- 大数据:Hadoop(JDK安装、HDFS伪分布式环境搭建、HDFS 的shell操作)
所有的内容都来源与 Hadoop 官方文档 一.Hadoop 伪分布式安装步骤 1)JDK安装 解压:tar -zxvf jdk-7u79-linux-x64.tar.gz -C ~/app 添加到系 ...
随机推荐
- vs 调试 iis中的网站
打开网站,在vs中附加进程,选择w3wp.exe,如果不能下断点,设置一下pdb文件位置
- Netty中的HttpObjectAggregator
Http的Get,POST Get请求包括两个部分: request line(包括method,request uri,protocol version)) header 基本样式: GET /?n ...
- 小tips:JS操作数组的slice()与splice()方法
slice(start, end) slice()方法返回从参数指定位置开始到当前数组末尾的所有项.如果有两个参数,该方法返回起始和结束位置之间的项,但不包括结束位置的项. var colors = ...
- vuejs-指令详解
v-if v-if指令可以完全根据表达式的值在DOM中生成或移除一个元素.如果v-if表达式赋值为false,那么对应的元素就会从DOM中移除:否则,对应元素的一个克隆将被重新插入DOM中,代码如下: ...
- C#基础(202)--类定义,字段与属性,自动属性,方法及常见错误
c#类的定义规范 字段与属性的比较: 字段: 字段主要是为类的内部做数据交换交互使用,字段一般是private 字段可以赋值,也可以取值 当字段需要为外部数据提供数据的时候,请将字段封装为属性,而不是 ...
- Human Motion Analysis with Wearable Inertial Sensors——阅读1
Human Motion Analysis with Wearable Inertial Sensors——阅读 博主认为对于做室内定位和导航的人这是一篇很很棒的文章,不是他的技术很牛,而是这是一篇医 ...
- 归并排序(MergeSort)和快速排序(QuickSort)的一些总结问题
归并排序(MergeSort)和快速排序(QuickSort)都是用了分治算法思想. 所谓分治算法,顾名思义,就是分而治之,就是将原问题分割成同等结构的子问题,之后将子问题逐一解决后,原问题也就得到了 ...
- ViewPager实现滑动翻页效果
实现ViewPager的滑动翻页效果可以使用ViewPager的setPageTransformer方法,如下: import android.content.Context; import andr ...
- Java虚拟机(五)Java的四种引用级别
1.前言 HotSpot采取了可达性分析算法用来判断对象是否被能被GC,无论是引用计算法还是可达性分析算法都是判断对象是否存在引用来判断对象是否存活.如果reference类型的数据中存储的数值代表的 ...
- <自动化测试方案书>方案书目录排版
自动化测试方案书 一.介绍 QQ交流群:585499566 这篇是一个系列,用来给需要做自动化测试方案的人做个参考,文章的内容是我收集网上和自己工作经验所得,希望能够给你们有所帮助 背景:因为工作需要 ...