spark集群搭建
文中的所有操作都是在之前的文章scala的安装及使用文章基础上建立的,重复操作已经简写;
配置中使用了master01、slave01、slave02、slave03;
一、虚拟机中操作(启动网卡)
sh /install/initNetwork.sh
ifup eth0
二、基础配置(主机名、IP配置、防火墙及selinux强制访问控制安全系统)
vi /etc/sysconfig/network (配置磁盘中主机名字)
vi /etc/hosts (配置映射,)
hostname 主机名 (修改内存中主机名)
然后,重新链接查看是否成功;
vi /etc/sysconfig/network-scripts/ifcfg-eth0
查看内容是否设置成功:cat /etc/sysconfig/network-scripts/ifcfg-eth0

DEVICE=eth0 (设置需要重启的设备的名字)
TYPE=Ethernet(以太网)
ONBOOT=yes (设置为yes)
NM_CONTROLLED=yes
BOOTPROTO=static (设置为静态)
IPADDR=192.168.238.130 (本机IP地址)
NETMASK=255.255.255.0 (子网掩码)
GATEWAY=192.168.238.2 (网关)(查询本机网关:route -n)
DNS1=192.168.238.2
DNS2=8.8.8.8 (谷歌IP地址)
vi /etc/sysconfig/selinux
修改:SELINUX=disabled
去掉注释查看selinux内容:
grep -Ev '^#|^$' /etc/sysconfig/selinux
永久关闭防火墙:
service iptables stop
chkconfig iptables off
三、配置ssh免密登录(为root用户配置免s密码登录)
只需要master登录到salve各个节点即可,无需反向
[root@master01 ~]# ssh-keygen -t rsa 创建公匙
[root@master01 ~]# ssh-copy-id slave02 拷贝公匙
大数据学习交流群:217770236 让我我们一起学习大数据
四、搭建Spark集群
1、上传安装包到/install/目录
[root@master01 install]# ls
initNetwork.sh mytest.txt scala-2.11.8.tgz spark-2.1.1-bin-hadoop2.7.tgz
2、解压安装包并更名
[root@master01 install]# tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /software/
[root@master01 software]# mv spark-2.1.1-bin-hadoop2.7/ spark-2.1.1
3、配置系统环境
[root@master01 install]# vi /etc/profile
修改如下内容:
JAVA_HOME=/software/jdk1.7.0_79
HADOOP_HOME=/software/hadoop-2.7.3
HBASE_HOME=/software/hbase-1.2.6
SCALA_HOME=/software/scala-2.11.8
SPARK_HOME=/software/spark-2.1.1
PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/lib:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$SCALA_HOME/bin::$SPARK_HOME/bin:
export PATH JAVA_HOME HADOOP_HOME HBASE_HOME SCALA_HOME SPARK_HOME
[root@master01 install]# source /etc/profile
4、切换到hadoop用户并配置spark-env.sh
[root@master01 software]# su -l hadoop
[hadoop@master01 spark-2.1.1]$ cd /software/spark-2.1.1/conf/
[hadoop@master01 conf]$ cp spark-env.sh.template spark-env.sh
[hadoop@master01 conf]$ vi spark-env.sh
添加如下内容:
export JAVA_HOME=/software/jdk1.7.0_79
export SCALA_HOME=/software/scala-2.11.8
export HADOOP_HOME=/software/hadoop-2.7.3
export HADOOP_CONF_DIR=/software/hadoop-2.7.3/etc/hadoop
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=slave01:2181,slave02:2181,slave03:2181 -Dspark.deploy.zookeeper.dir=/spark" #export SPARK_MASTER_IP=master01
#export SPARK_WORKER_MEMORY=1500m
5、如果需要使用浏览器查看日志则需要开启历史日志服务:
[hadoop@master01 conf]$ cp spark-defaults.conf.template spark-defaults.conf
[hadoop@master01 conf]$ vi spark-defaults.conf
添加如下内容:
spark.master spark://master01:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://ns1/sparkLog
spark.yarn.historyServer.address master01:18080
spark.history.fs.logDirectory hdfs://ns1/sparkLog
6、配置Spark集群的Worker节点
[hadoop@master01 conf]$ cp slaves.template slaves
[hadoop@master01 conf]$ vi slaves
修改成如下内容:
slave01
slave02
slave03
7、分发Spark的安装目录到各个Worker节点(即原DataNode节点)
#将所有的节点全部切换到hadoop用户
[root@master01 software]# su -l hadoop
[root@slave01 ~]# su -l hadoop
[root@slave02 ~]# su -l hadoop
[root@slave03 ~]# su -l hadoop
#分发Spark的安装目录到各个Worker节点
[hadoop@master01 software]$ scp -r /software/spark-2.1.1/ slave01:/software/
[hadoop@master01 software]$ scp -r /software/spark-2.1.1/ slave02:/software/
[hadoop@master01 software]$ scp -r /software/spark-2.1.1/ slave03:/software/
#分发环境配置文件到各个Worker节点
[root@master01 ~]# scp -r /etc/profile slave01:/etc/
[root@master01 ~]# scp -r /etc/profile slave02:/etc/
[root@master01 ~]# scp -r /etc/profile slave03:/etc/
立即生效配置文件:
[hadoop@slave01 software]$ source /etc/profile
[hadoop@slave02 software]$ source /etc/profile
[hadoop@slave03 software]$ source /etc/profile
五、启动Spark集群
【1、在slave节点启动zookeeper集群(小弟中选个leader和follower)】
cd /software/zookeeper-3.4.10/bin/ && ./zkServer.sh start && cd - && jps
cd /software/zookeeper-3.4.10/bin/ && ./zkServer.sh status && cd -
【2、master01启动HDFS集群】cd /software/ && start-dfs.sh && jps
【3、在master01节点上启动Spark集群的Master节点】
[hadoop@master01 install]$ cd /software/spark-2.1.1/sbin/ && ./start-master.sh && jps
【4、在master01节点上启动Spark集群的所有Slave节点】
[hadoop@master01 sbin]$ cd /software/spark-2.1.1/sbin/ && ./start-slaves.sh && jps
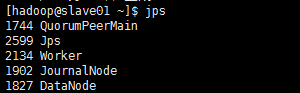
注意:Worker进程是Spark集群的Worker进程
【5、如果需要使用浏览器来查看Spark的日志则需要启动历史日志服务(同样是在master01节点上启动日志服务)】
[hadoop@master01 sbin]$ cd /software/spark-2.1.1/sbin/ && ./start-history-server.sh && jps
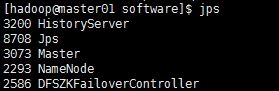
注意:HistoryServer是历史日志服务进程(该进程只会在运行此start-history-server.sh脚本的节点上启动),而Master是Spark集群的Master进程
六、验证Spark集群搭建是否成功
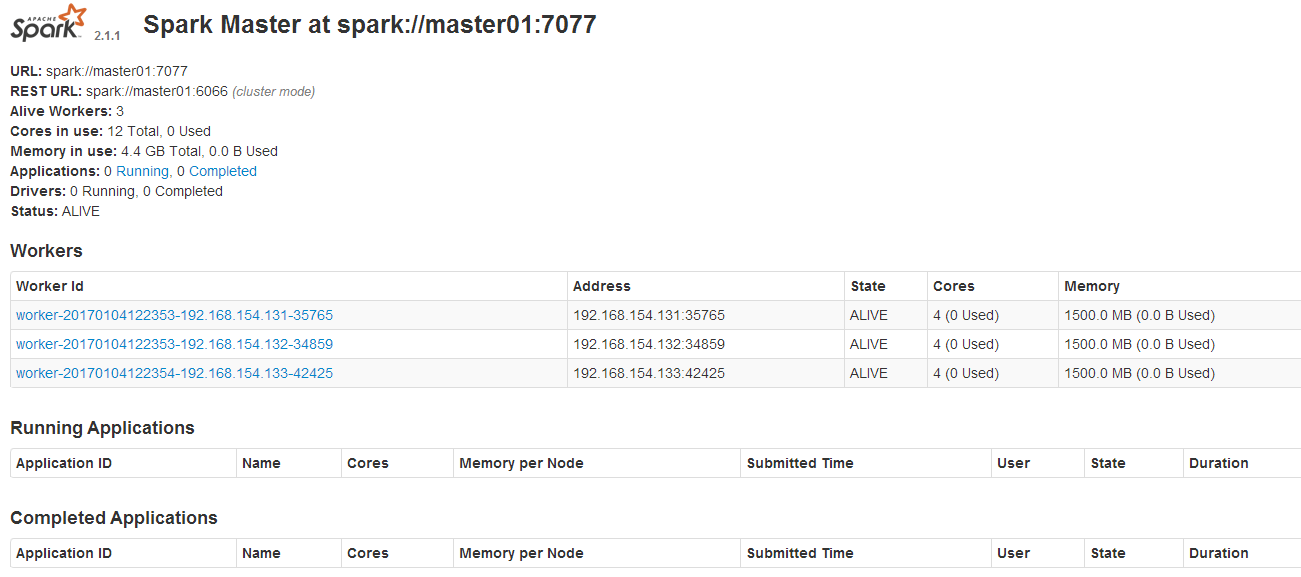
1、使用浏览器确认Spark集群服务是否已经正常启动
http://master01的IP地址:8080/ 2、使用浏览器确认Spark日志服务是否已经正常启动(访问的端口18080来自于上面的日志服务配置)
http://master01的IP地址:18080/

spark集群搭建的更多相关文章
- (四)Spark集群搭建-Java&Python版Spark
Spark集群搭建 视频教程 1.优酷 2.YouTube 安装scala环境 下载地址http://www.scala-lang.org/download/ 上传scala-2.10.5.tgz到m ...
- Spark集群搭建简要
Spark集群搭建 1 Spark编译 1.1 下载源代码 git clone git://github.com/apache/spark.git -b branch-1.6 1.2 修改pom文件 ...
- Spark集群搭建简配+它到底有多快?【单挑纯C/CPP/HADOOP】
最近耳闻Spark风生水起,这两天利用休息时间研究了一下,果然还是给人不少惊喜.可惜,笔者不善JAVA,只有PYTHON和SCALA接口.花了不少时间从零开始认识PYTHON和SCALA,不少时间答了 ...
- Spark集群搭建中的问题
参照<Spark实战高手之路>学习的,书籍电子版在51CTO网站 资料链接 Hadoop下载[链接](http://archive.apache.org/dist/hadoop/core/ ...
- Spark集群搭建_Standalone
2017年3月1日, 星期三 Spark集群搭建_Standalone Driver: node1 Worker: node2 Worker: node3 1.下载安装 下载地址 ...
- Spark集群搭建_YARN
2017年3月1日, 星期三 Spark集群搭建_YARN 前提:参考Spark集群搭建_Standalone 1.修改spark中conf中的spark-env.sh 2.Spark on ...
- Spark 集群搭建
0. 说明 Spark 集群搭建 [集群规划] 服务器主机名 ip 节点配置 s101 192.168.23.101 Master s102 192.168.23.102 Worker s103 19 ...
- hadoop+spark集群搭建入门
忽略元数据末尾 回到原数据开始处 Hadoop+spark集群搭建 说明: 本文档主要讲述hadoop+spark的集群搭建,linux环境是centos,本文档集群搭建使用两个节点作为集群环境:一个 ...
- Spark集群搭建(local、standalone、yarn)
Spark集群搭建 local本地模式 下载安装包解压即可使用,测试(2.2版本)./bin/spark-submit --class org.apache.spark.examples.SparkP ...
随机推荐
- 使用Eclipse的代码追踪功能
在使用Java编写复杂一些的程序时,你会不会常常对一层层的继承关系和一次次方法的调用感到迷惘呢?幸亏我们有了Eclipse这么好的IDE可以帮我们理清头绪--这就要使用Eclipse强大的代码追踪功能 ...
- 我的C#跨平台之旅(六):发布应用
由于此架构从一开始就将.NET Framework 的依赖降低到最低,且不依赖IIS,在ORM层面,完全实现代码优先,即真正做到数据库无关: Windows服务器部署: 在Windows应用服务器上安 ...
- appium+python自动化脚本
用pycharm,首先得把appium导入,操作如下(否则,运行程序后会报错,没有module appium) Settings->Project Interpreter,双击pip,搜索app ...
- C# WebSocket Fleck 调用非托管C++ DLL 实现通信(使用stringbuilder接收)
[DllImport(@"XXX.dll", CallingConvention = CallingConvention.StdCall)]public static exter ...
- 我所理解的HTTP协议
前言 对于HTTP协议,想必大家都不陌生,在工作中经常用到,特别是针对移动端和前端开发人员来说,要获取服务端数据,基本走的网络请求都是基于HTTP协议,特别是RESTFUL + JSON 这种搭配特别 ...
- ZKWeb网页框架2.1正式发布
2.1.0更新的内容有 更新引用类库 NHibernate 5.1.0 Npgsql 3.2.7 MySqlConnector 0.37.0 Dapper 1.50.4 Dommel 1.10.1 Z ...
- 【渗透攻防】深入了解Windows
前言 本篇是基础教程,带大家了解Windows常用用户及用户组,本地提取用户密码,远程利用Hash登录到本地破解Hash.初步掌握Windows基础安全知识. 目录 第一节 初识Windows 第二节 ...
- ALSA概述--高级linux声音驱动基本介绍和应用
基本介绍: ALSA是Advanced Linux Sound Architecture,高级Linux声音架构的简称,它在Linux操作系统上提供了音频和MIDI(Musical Instrumen ...
- 利用node 剥取其他网站的文档数据结构 ---
1.如何利用nodejs获取其他网站的文档结构呢 以下是代码演示------! //首先需要引入一些核心模块 var http = require('http'); var fs = require( ...
- 基于python的OpenCV图像1
目录 1. 读入图片并显示 import cv2 img = cv2.imread("longmao.jpg") cv2.imshow("longmao", i ...