5.机器学习——DBSCAN聚类算法
1.优缺点
优点:
(1)聚类速度快且能够有效处理噪声点和发现任意形状的空间聚类;
(2)与K-MEANS比较起来,不需要输入要划分的聚类个数;
(3)聚类簇的形状没有偏倚;
(4)可以在需要时输入过滤噪声的参数。
缺点:
(1)当数据量增大时,要求较大的内存支持I/O消耗也很大;
(2)当空间聚类的密度不均匀、聚类间距差相差很大时,聚类质量较差,因为这种情况下参数MinPts和Eps选取困难。
(3)算法聚类效果依赖与距离公式选取,实际应用中常用欧式距离,对于高维数据,存在“维数灾难”。
2.原理
DBSCAN参数
Eps——距离阈值,该聚类算法中把距离当做密度表达,距离如何计算也很重要。
MinPts——形成一个核心点所需要最小的直接可达点数,例如改参数设置为5,Eps设置为2,那么一个核心点(包含自己)形成的条件是该核心店距离阈值2以内至少有5个点。
待聚类点分为三类:
- 直接可达点 核心点距离阈值内的点成为直接可达点
- 可达点 属于不同核心点的直接的可达点通过核心点组成的路径(相邻核心点之间在各自距离阈值内)相连,那么这些直接可达点被称为可达点
- 局外点 既不是核心点也不是直接可达点也不是可达点被称为局外点,也可叫做噪声点
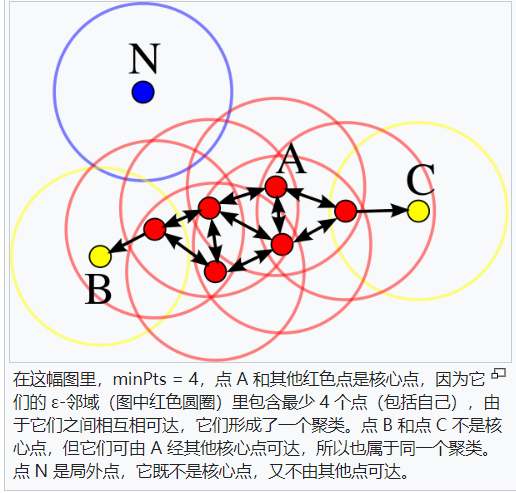
3.聚类
同一组直接可达点与可达点形成一个类簇,局外点形成噪声点
5.机器学习——DBSCAN聚类算法的更多相关文章
- 机器学习入门-DBSCAN聚类算法
DBSCAN 聚类算法又称为密度聚类,是一种不断发张下线而不断扩张的算法,主要的参数是半径r和k值 DBSCAN的几个概念: 核心对象:某个点的密度达到算法设定的阈值则其为核心点,核心点的意思就是一个 ...
- 5.无监督学习-DBSCAN聚类算法及应用
DBSCAN方法及应用 1.DBSCAN密度聚类简介 DBSCAN 算法是一种基于密度的聚类算法: 1.聚类的时候不需要预先指定簇的个数 2.最终的簇的个数不确定DBSCAN算法将数据点分为三类: 1 ...
- Python机器学习——DBSCAN聚类
密度聚类(Density-based Clustering)假设聚类结构能够通过样本分布的紧密程度来确定.DBSCAN是常用的密度聚类算法,它通过一组邻域参数(ϵϵ,MinPtsMinPts)来描述样 ...
- 初探DBSCAN聚类算法
DBSCAN介绍 一种基于密度的聚类算法 他最大的优势是可以发现任意形状的聚类簇,而传统的聚类算法只能使用凸的样本聚集类 两个参数: 邻域半径R和最少点数目minpoints. 当邻域半径R内的点的个 ...
- 【机器学习】聚类算法:层次聚类、K-means聚类
聚类算法实践(一)--层次聚类.K-means聚类 摘要: 所谓聚类,就是将相似的事物聚集在一 起,而将不相似的事物划分到不同的类别的过程,是数据分析之中十分重要的一种手段.比如古典生物学之中,人们通 ...
- 机器学习之DBSCAN聚类算法
可以看该博客:https://www.cnblogs.com/aijianiula/p/4339960.html 1.知识点 """ 基本概念: 1.核心对象:某个点的密 ...
- 【机器学习】聚类算法——K均值算法(k-means)
一.聚类 1.基于划分的聚类:k-means.k-medoids(每个类别找一个样本来代表).Clarans 2.基于层次的聚类:(1)自底向上的凝聚方法,比如Agnes (2)自上而下的分裂方法,比 ...
- 【机器学习】聚类算法:ISODATA算法
在之前的K-Means算法中,有两大缺陷: (1)K值是事先选好的固定的值 (2)随机种子选取可能对结果有影响 针对缺陷(2),我们提出了K-Means++算法,它使得随机种子 ...
- Python实现DBSCAN聚类算法(简单样例测试)
发现高密度的核心样品并从中膨胀团簇. Python代码如下: # -*- coding: utf-8 -*- """ Demo of DBSCAN clustering ...
随机推荐
- BBS论坛(二)
2.1.cms后台登录界面完成 (1)templates/cms/cms_login.html <!DOCTYPE html> <html lang="zh-CN" ...
- 【netty】(1)---BIO NIO AIO演变
BIO NIO AIO演变 Netty是一个提供异步事件驱动的网络应用框架,用以快速开发高性能.高可靠的网络服务器和客户端程序.Netty简化了网络程序的开发,是很多框架和公司都在使用的技术. Net ...
- mockjs,json-server一起搭建前端通用的数据模拟框架
无论是在工作,还是在业余时间做前端开发的时候,难免出现后端团队还没完成接口的开发,而前端团队却需要实现对应的功能,不要问为什么,这是肯定存在的.本篇文章就是基于此原因而产出的.希望对有这方面的需求的同 ...
- 【安卓本卓】Android系统源码篇之(一)源码获取、源码目录结构及源码阅读工具简介
前言 古人常说,“熟读唐诗三百首,不会作诗也会吟”,说明了大量阅读诗歌名篇对学习作诗有非常大的帮助.做开发也一样,Android源码是全世界最优秀的Android工程师编写的代码,也是A ...
- 在阿里云 ECS 搭建 nginx https nodejs 环境 (一、 nginx)
首先介绍下相关环境.软件的版本 1.阿里云 ECS . ubuntu-14.04.5 LTS 2.nginx 版本 1.9.2 可能会遇到的问题: 一.在 ssh 服务器上的时候,提示 这个时候需要将 ...
- Kafka基础简介
kafka是一个分布式的,可分区的,可备份的日志提交服务,它使用独特的设计实现了一个消息系统的功能. 由于最近项目升级,需要将spring的事件机制转变为消息机制,针对后期考虑,选择了kafka作为消 ...
- 【转载】asp.net core 2.0的认证和授权
在asp.net core中,微软提供了基于认证(Authentication)和授权(Authorization)的方式,来实现权限管理的,本篇博文,介绍基于固定角色的权限管理和自定义角色权限管理, ...
- GitHub 开源的 MySQL 在线更改 Schema 工具【转】
本文来自:https://segmentfault.com/a/1190000006158503 原文:gh-ost: GitHub's online schema migration tool fo ...
- KVO原理解析
KVO在我们项目开发中,经常被用到,但很少会被人关注,但如果面试一些大公司,针对KVO的面试题可能如下: 知道KVO嘛,底层是怎么实现的? 如何动态的生成一个类? 今天我们围绕上面几个问题,我们先看K ...
- Php导出百万数据的优化
导出数据量很大的情况下,生成excel的内存需求非常庞大,服务器吃不消,这个时候考虑生成csv来解决问题,cvs读写性能比excel高.测试表student 数据(大家可以脚本插入300多万测数据.这 ...