Python开发爬虫之动态网页抓取篇:爬取博客评论数据——通过Selenium模拟浏览器抓取
区别于上篇动态网页抓取,这里介绍另一种方法,即使用浏览器渲染引擎。直接用浏览器在显示网页时解析 HTML、应用 CSS 样式并执行 JavaScript 的语句。
这个方法在爬虫过程中会打开一个浏览器加载该网页,自动操作浏览器浏览各个网页,顺便把数据抓下来。用一句简单而通俗的话说,就是使用浏览器渲染方法将爬取动态网页变成爬取静态网页。
我们可以用 Python 的 Selenium 库模拟浏览器完成抓取。Selenium 是一个用于Web 应用程序测试的工具。Selenium 测试直接运行在浏览器中,浏览器自动按照脚本代码做出单击、输入、打开、验证等操作,就像真正的用户在操作一样。
通过Selenium模拟浏览器抓取。最常用 的是 Firefox,因此下面的讲解也以 Firefox 为例,在运行之前需要安装 Firefox 浏 览器。
以爬取《Python 网络爬虫:从入门到实践》一书作者的个人博客评论为例。网址:http://www.santostang.com/2017/03/02/hello-world/
在运行下列代码时,一定要留意自己网络是否畅通,如果网络不好造成浏览器不能正常打开网页及其评论数据,就可能造成爬取失败。
1)找到评论的HTML代码标签。使用Chrome打开该文章页面,右键点击页面,打开“检查”选项。定位到评论数据。此处定位到的评论数据即是浏览器渲染后的数据位置,如图:
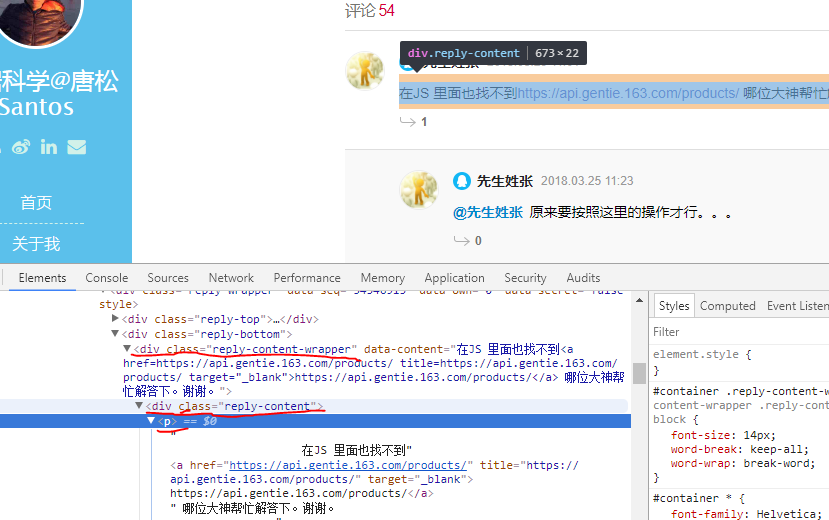
2)尝试获取一条评论数据。在原来打开页面的代码数据上,我们可以使用以下代码,获取第一条评论数据。在下面代码中,driver.find_element_by_css_selector是用CSS选择器查找元素,找到class为’reply-content’的div元素;find_element_by_tag_name则是通过元素的tag去寻找,意思是找到comment中的p元素。最后,再输出p元素中的text文本。
相关代码1:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe') #把上述地址改成你电脑中Firefox程序的地址
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017/03/02/hello-world/")
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))
comment=driver.find_element_by_css_selector('div.reply-content-wrapper') #此处参数字段也可以是'div.reply-content',具体字段视具体网页div包含关系而定
content=comment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
代码解析:
1)caps=webdriver.DesiredCapabilities().FIREFOX

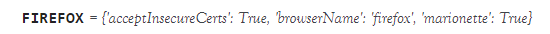
由此可知,将上文代码中的caps["marionette"]=True注释掉,代码依旧可以正常运行。
2)binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe')

3)driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
构建webdriver类。
还可以构建别的类型的webdriver类。

4)driver.get("http://www.santostang.com/2017/03/02/hello-world/")

5)driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))


6)comment=driver.find_element_by_css_selector('div.reply-content-wrapper')

7)content=comment.find_element_by_tag_name('p')

更多代码含义和使用规则请参见官网API和Navigating:http://selenium-python.readthedocs.io/index.html
8)关于driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))中的框架定位及title内容。
可在代码中加入driver.page_source,并且注释掉driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']"))。可在输出内容中找到(若输出杂乱,不好找出相关内容,可将其复制黏贴到文本文件中,使用Notepad++打开,该软件有前后标签对应显示功能):
(此处只截取了相关内容的末尾部分)

若使用了driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']")),而再使用driver.page_source进行相关输出,则发现没有上面的iframe标签,证明我们已经将该框架解析完毕,可以进行相关定位获取元素了。
上面我们只是获取了一条评论,如果要获取所有评论,使用循环获取所有评论。
相关代码2:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe')
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017/03/02/hello-world/")
#page=driver.find_element_by_xpath(".//html")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']")) comments=driver.find_elements_by_css_selector('div.reply-content')
for eachcomment in comments:
content=eachcomment.find_element_by_tag_name('p')
print(content.text)
#driver.page_source
输出:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 原来要按照这里的操作才行。。。
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 这是网易云上面的一个连接地址,那个服务器都关闭了
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
测试
为什么我用代码打开的文章只有两条评论,本来是有46条的,有大神知道怎么回事吗?
菜鸟一只,求学习群
lalala1
我来试一试
我来试一试
应该点JS,然后看里面的Preview或者Response,里面响应的是Ajax的内容,然后如果去爬网站的评论的话,点开js那个请求后点Headers -->在General里面拷贝 RequestURL 就可以了
注意代码2中将代码1中的comment=driver.find_element_by_css_selector('div.reply-content-wrapper') 改成了comments=driver.find_elements_by_css_selector('div.reply-content')
elements加了s

以上获取的全部评论数据均属于正常进入该网页,等该网页渲染完获取的全部评论,并未进行点击“查看更多”来加载目前还未渲染的评论。
下面介绍一种能够爬取到所有评论,包括点击完“查看更多”加载的目前还未渲染的评论。
相关代码:
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
import time caps=webdriver.DesiredCapabilities().FIREFOX
caps["marionette"]=True
binary=FirefoxBinary(r'E:\软件安装目录\装机必备软件\Mozilla Firefox\firefox.exe')
driver=webdriver.Firefox(firefox_binary=binary,capabilities=caps)
driver.get("http://www.santostang.com/2017/03/02/hello-world/")
driver.switch_to.frame(driver.find_element_by_css_selector("iframe[title='livere']")) time.sleep(60)
for i in range(0,10):
try:
load_more=driver.find_element_by_css_selector('div.more-wrapper')
load_more.click()
except:
pass
time.sleep(5)
comments=driver.find_elements_by_css_selector('div.reply-content') for eachcomment in comments:
content=eachcomment.find_element_by_tag_name('p')
print(content.text)
代码解析:
1)time.sleep(60)
延时60秒执行以下代码。
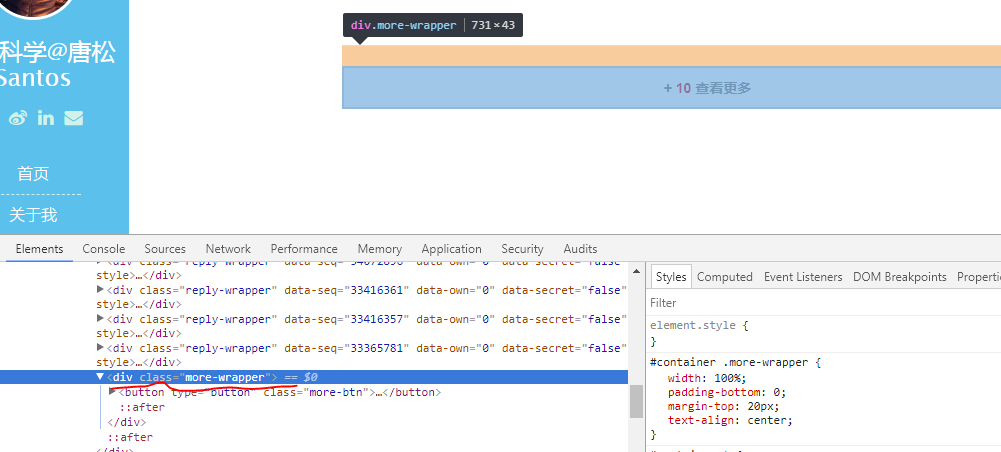
2)load_more=driver.find_element_by_css_selector('div.more-wrapper')中的参数字符串
打开目标网页,等目标网页整体渲染完之后,右键评论区的“查看更多”。
3)load_more.click()
模拟点击“查看更多”按钮,进行完整显示所有评论。
4)之所以在代码中两次使用延时函数,是因为不同网络状况和不同机器环境下可能在打开网页以及点击“查看更多”按钮后不能马上显示评论,所以代码需要等一等,等到页面完全渲染后,再进行评论区数据的收集工作。
因此各延时函数的延时时间长短可视具体情况灵活设置。
输出结果:
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 原来要按照这里的操作才行。。。
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
@先生姓张 这是网易云上面的一个连接地址,那个服务器都关闭了
在JS 里面也找不到https://api.gentie.163.com/products/ 哪位大神帮忙解答下。谢谢。
测试
为什么我用代码打开的文章只有两条评论,本来是有46条的,有大神知道怎么回事吗?
菜鸟一只,求学习群
lalala1
我来试一试
我来试一试
应该点JS,然后看里面的Preview或者Response,里面响应的是Ajax的内容,然后如果去爬网站的评论的话,点开js那个请求后点Headers -->在General里面拷贝 RequestURL 就可以了
现在死在了4.2节上,页面评论是有的,但是XHR里没有东西啊,这是什么情况?有解决的大神吗?
@骨犬 JS
为何静态网页抓取不了? 奇怪了,我按照书上的方法来操作,XHR也是空的啊
@易君召 我的也是空的
你解决问题了吗
@思い亦深 看JS不是XHR
XHR没有显示任何东西啊。奇怪。
找到原因了
caps["marionette"] = True
作者可以解释一下这句话是干什么的吗
@A cat named GitHub 改成 caps["marionette"] = False 可以运行。 目前还没吃透代码,先用着试试
我用的是 pycham IDE,按照作者的写法写的,怎么不行
@A cat named GitHub 找到原因了
caps["marionette"] = True
作者可以解释一下这句话是干什么的吗
对火狐版本有要求吗
@花晨 我的也是提示火狐版本不匹配,你解决了吗
@A cat named GitHub 重装了geckodriver
改成caps["marionette"] = "Windows"
总之就好了
4.3.1 打开Hello World,代码用的作者的,火狐地址我也设置了,为啥运行没反应
from selenium import webdriver
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary caps = webdriver.DesiredCapabilities().FIREFOX
caps["marionette"] = False
binary = FirefoxBinary(r'C:\Program Files\Mozilla Firefox\firefox.exe')
#把上述地址改成你电脑中Firefox程序的地址
driver = webdriver.Firefox(firefox_binary=binary, capabilities=caps)
driver.get("http://www.santostang.com/2017/03/02/hello-world/")
我是番茄
为什么刷新没有XHR数据,评论明明加载出来了
为什么刷新没有XHR数据,评论明明加载出来了
@萌萌哒的小叽叽丶 书里错误很多,留个qq吧
为什么刷新没有XHR数据,评论明明加载出来了
第21条测试评论
第20条测试评论
第19条测试评论
第18条测试评论
第17条测试评论
第16条测试评论
第15条测试评论
第14条测试评论
第13条测试评论
第12条测试评论
第11条测试评论
第10条测试评论
第9条测试评论
第8条测试评论
第7条测试评论
第6条测试评论
第5条测试评论
第4条测试评论
第3条测试评论
第二条测试评论
第一条测试评论
参考书目:唐松,来自《Python 网络爬虫:从入门到实践》
参考书目作者关于本部分的介绍:http://www.santostang.com/2017/09/25/4-3-%E9%80%9A%E8%BF%87-selenium-%E6%A8%A1%E6%8B%9F%E6%B5%8F%E8%A7%88%E5%99%A8%E6%8A%93%E5%8F%96/
Python开发爬虫之动态网页抓取篇:爬取博客评论数据——通过Selenium模拟浏览器抓取的更多相关文章
- Selenium模拟浏览器抓取淘宝美食信息
前言: 无意中在网上发现了静觅大神(崔老师),又无意中发现自己硬盘里有静觅大神录制的视频,于是乎看了其中一个,可以说是非常牛逼了,让我这个用urllib,requests用了那么久的小白,体会到sel ...
- 使用selenium模拟浏览器抓取淘宝信息
通过Selenium模拟浏览器抓取淘宝商品美食信息,并存储到MongoDB数据库中. from selenium import webdriver from selenium.common.excep ...
- Python开发爬虫之静态网页抓取篇:爬取“豆瓣电影 Top 250”电影数据
所谓静态页面是指纯粹的HTML格式的页面,这样的页面在浏览器中展示的内容都在HTML源码中. 目标:爬取豆瓣电影TOP250的所有电影名称,网址为:https://movie.douban.com/t ...
- Python爬虫学习==>第十二章:使用 Selenium 模拟浏览器抓取淘宝商品美食信息
学习目的: selenium目前版本已经到了3代目,你想加薪,就跟面试官扯这个,你赢了,工资就到位了,加上一个脚本的应用,结局你懂的 正式步骤 需求背景:抓取淘宝美食 Step1:流程分析 搜索关键字 ...
- 16-使用Selenium模拟浏览器抓取淘宝商品美食信息
淘宝由于含有很多请求参数和加密参数,如果直接分析ajax会非常繁琐,selenium自动化测试工具可以驱动浏览器自动完成一些操作,如模拟点击.输入.下拉等,这样我们只需要关心操作而不需要关心后台发生了 ...
- 3.使用Selenium模拟浏览器抓取淘宝商品美食信息
# 使用selenium+phantomJS模拟浏览器爬取淘宝商品信息 # 思路: # 第一步:利用selenium驱动浏览器,搜索商品信息,得到商品列表 # 第二步:分析商品页数,驱动浏览器翻页,并 ...
- 爬虫实战--使用Selenium模拟浏览器抓取淘宝商品美食信息
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.common.exce ...
- 使用Selenium模拟浏览器抓取淘宝商品美食信息
代码: import re from selenium import webdriver from selenium.webdriver.common.by import By from seleni ...
- Path通过Selenium模拟浏览器抓取,Windows 64解决selenium.common.exceptions.WebDriverException: Message: 'geckodriver' executable needs to be in PATH.方法
1.下载geckodriver.exe: 下载地址:https://github.com/mozilla/geckodriver/releases请根据系统版本选择下载:(如Windows 64位系统 ...
随机推荐
- [Swift]LeetCode405. 数字转换为十六进制数 | Convert a Number to Hexadecimal
Given an integer, write an algorithm to convert it to hexadecimal. For negative integer, two’s compl ...
- [Swift]LeetCode482. 密钥格式化 | License Key Formatting
You are given a license key represented as a string S which consists only alphanumeric character and ...
- [Swift]LeetCode779. 第K个语法符号 | K-th Symbol in Grammar
On the first row, we write a 0. Now in every subsequent row, we look at the previous row and replace ...
- linux入门--Linux系统的优缺点
1) 大量的可用软件及免费软件 Linux 系统上有着大量的可用软件,且绝大多数是免费的,比如声名赫赫的 Apache.Samba.PHP.MySQL 等,构建成本低廉,是 Linux 被众多企业青睐 ...
- [SDOI2018] 旧试题
推狮子的部分 \[ \sum_{i=1}^A\sum_{j=1}^B\sum_{k=1}^C\sigma(ijk) =\sum_{i=1}^A\sum_{j=1}^B\sum_{k=1}^C\sum_ ...
- Python——day14 三目运算、推导式、递归、匿名、内置函数
一.三目(元)运算符 定义:就是 if...else...语法糖前提:简化if...else...结构,且两个分支有且只有一条语句注:三元运算符的结果不一定要与条件直接性关系 cmd = input ...
- C++版 - 剑指offer面试题14: 调整数组顺序使奇数位于偶数前面
题目: 调整数组顺序使奇数位于偶数前面 热度指数:11843 时间限制:1秒 空间限制:32768K 本题知识点: 数组 题目描述 输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有的奇 ...
- PHP中的反射
PHP中的反射 PHP5 具有完整的反射 API,添加了对类.接口.函数.方法和扩展进行反向工程的能力. 此外,反射 API 提供了方法来取出函数.类和方法中的文档注释. 请注意部分内部 API 丢失 ...
- iOS逆向开发(7):微信伪装他人
上一节小程介绍了微信在进入"附近的人"时修改位置信息的办法,这一次,小程来修改"自己"的信息,伪装成别人. 但是,这里的伪装只是"本地的伪装" ...
- 【Java资源免费分享,网盘自己拿】
JavaSE: Java马士兵:链接:https://pan.baidu.com/s/1jJRvxGi密码:v3xb Java毕向东:链接:https://pan.baidu.com/s/1ggzHk ...