全链路追踪 & 性能监控工具 SkyWalking 实战
Skywalking介绍
Skywalking是一个国产的开源框架,2015年有吴晟个人开源,2017年加入Apache孵化器,国人开源的产品,主要开发人员来自于华为,2019年4月17日Apache董事会批准SkyWalking成为顶级项目,支持Java、.Net、NodeJs等探针,数据存储支持Mysql、Elasticsearch等,跟Pinpoint一样采用字节码注入的方式实现代码的无侵入,探针采集数据粒度粗,但性能表现优秀,且对云原生支持,目前增长势头强劲,社区活跃
使用版本
当前使用版本信息为:apache-skywalking-apm-es7-8.7.0
数据存储方式
Skywalking默认使用的是H2,本次实战主要使用的ElasticSearch来存储相对应的链路数据。Skywalking本身还支持mysql、tidb、influxdb、postgresql等数据存储方式
Skywalking的安装以及使用
安装及运行(本次安装主要是在windows)
- 下载对应的二进制软件包
(apache-skywalking-apm-es7-8.7.0.tar),并且解压到指定的文件夹下面 - 涉及到的主要目录为:
bin(存放对应的命令)、config(相关的配置文件)、agent(代理jar包) - 进入bin目录直接执行目录下对应的
startup.bat即可运行Skywalking,默认是运行在8080端口;启动成功后即可在浏览器输入地址即可访问:127.0.0.1:8080。运行界面如图所示: - 首次访问没有上图相关的图示数据,因为还未对项目进行代理做数据采集
运行SpringBoot项目,并对其进行监控
运行其要进行监控的项目,增加代理参数,代理参数如下:
java -jar -javaagent:H:\apache-skywalking-apm-bin-es7\agent\skywalking-agent.jar -DSW_AGENT_NAME=demo -DSW_AGENT_COLLECTOR_BACKEND_SERVICES=127.0.0.1:11800
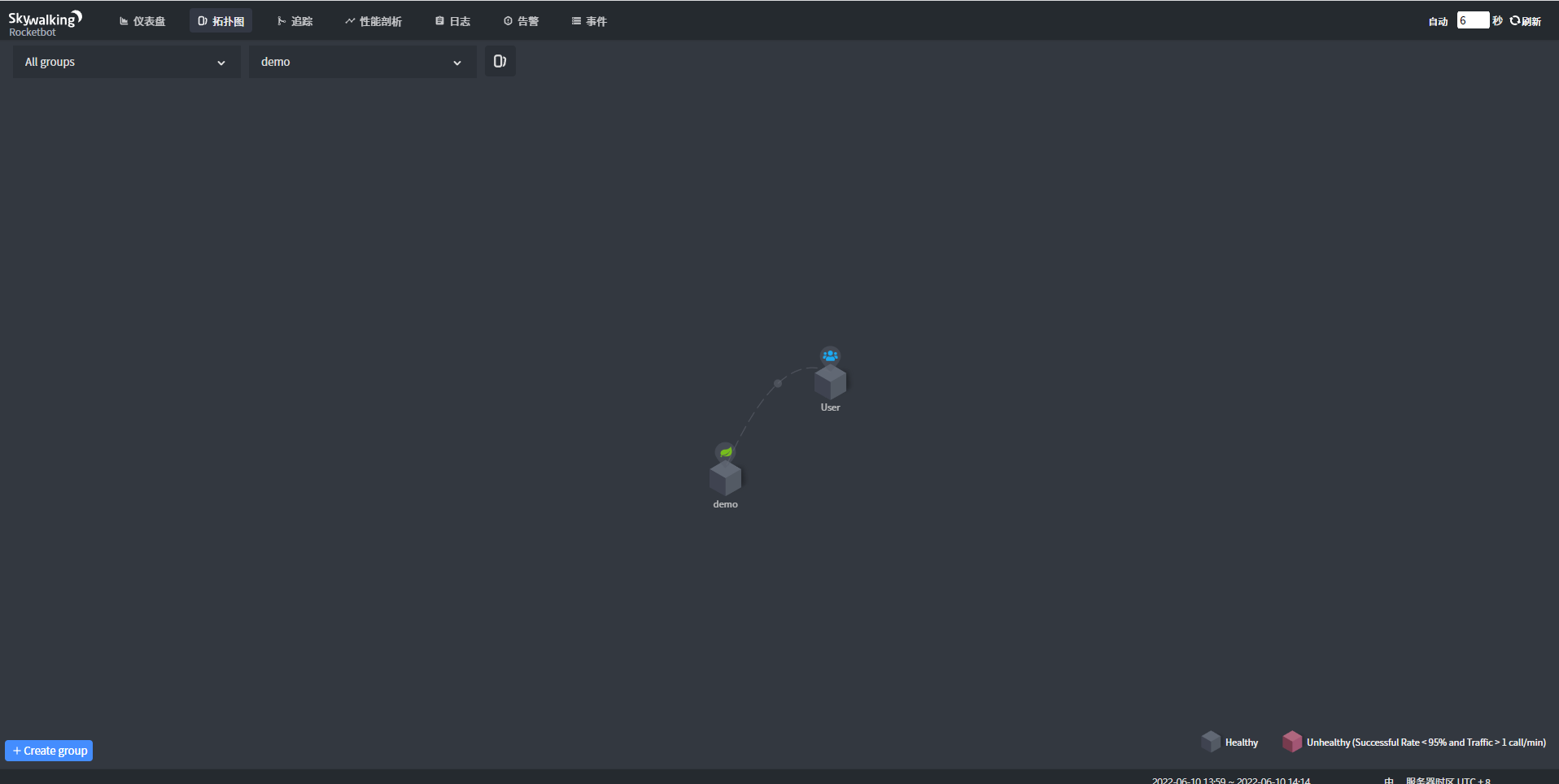
启动完项目后,就可以在SkyWalking看到该项目对应的访问数据以及对应的拓扑图
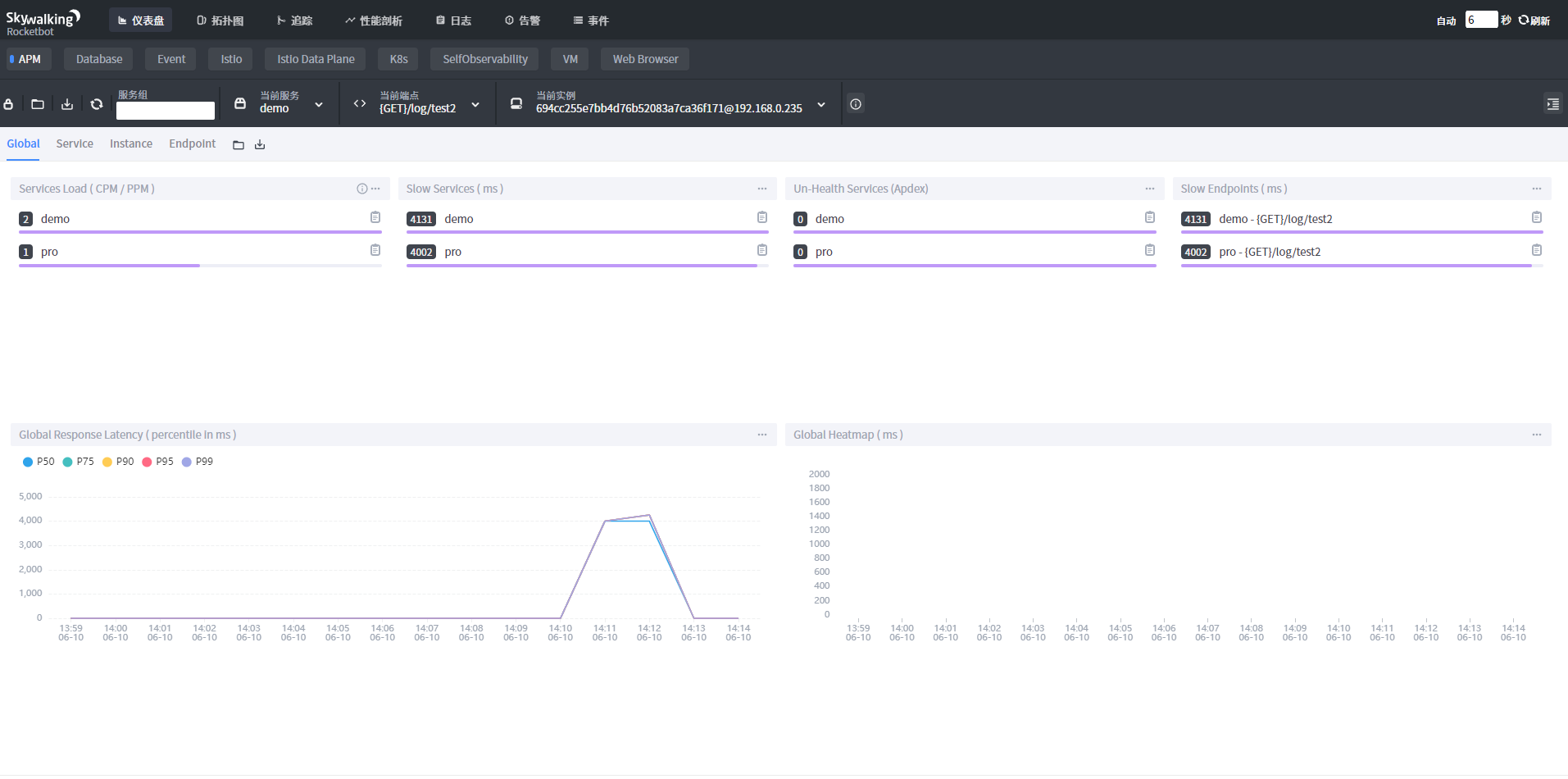
采集数据持久化
Skywalking默认是通过H2对采集数据进行存取的,并且没有做相对应的持久化,相关配置在config文件夹中application.xml文件中的121行:selector: ${SW_STORAGE:H2}。为了方便以及做持久化本实战主要将数据存放在ElasticSearch中修改数据存取方式为
elasticsearch7,只需要将selector修改为对应的elasticsearch7即可:selector: ${SW_STORAGE:elasticsearch7}配置elasticsearch:
nameSpace: ${SW_NAMESPACE:"elasticsearch"} //一定为要和elasticsearch中的cluster_name相对应
clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:localhost:9200}
重启SkyWalking之后,后期采集数据就存放在了ElasticSearch中了
注:在使用elasticsearch时需要注意其版本号,负责SkyWalking Collect将启动失败,本实战其对应的版本为7.2.0
加入日志采集
1、引入日志采集相关的jar包:
<dependency>
<groupId>org.apache.skywalking</groupId>
<artifactId>apm-toolkit-trace</artifactId>
<version>8.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.skywalking</groupId>
<artifactId>apm-toolkit-logback-1.x</artifactId>
<version>8.5.0</version>
</dependency>
2、在项目resource目录下新建logback.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod="10 seconds">
<property name="logData" value="./logDatas" />
<property name="appName" value="accessLog" />
<statusListener class="ch.qos.logback.core.status.NopStatusListener" />
<appender name="CONSOLE_OUT" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>%-15(%d{HH:mm:ss.SSS}) %msg%n</pattern>
</layout>
</appender>
<appender name="LOG_DEMO" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${logData}/logDataDemo.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!-- 指定生成日志保存地址 -->
<fileNamePattern>${logData}/%d{yyyy-MM-dd}/${appName}-info.%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<maxFileSize>1MB</maxFileSize>
<maxHistory>30</maxHistory>
</rollingPolicy>
<encoder>
<pattern>
%-15(%d{yyyy-MM-dd HH:mm:ss} [info]) %msg%n
</pattern>
<charset>UTF-8</charset>
</encoder>
</appender>
<appender name="msystem-log" class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.log.GRPCLogClientAppender">
<!-- 日志输出编码 -->
<encoder>
<!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度%msg:日志消息,%n是换行符-->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n
</pattern>
</encoder>
</appender>
<root level="info">
<appender-ref ref="CONSOLE_OUT" />
</root>
<!--输出到指定日志文件-->
<logger name="outToFile" level="INFO" additivity="false">
<appender-ref ref="LOG_DEMO"/>
<appender-ref ref="msystem-log"/>
</logger>
</configuration>
3、重新启动对应的SpringBoot项目,然后访问对应的路径即可收集到相关的数据
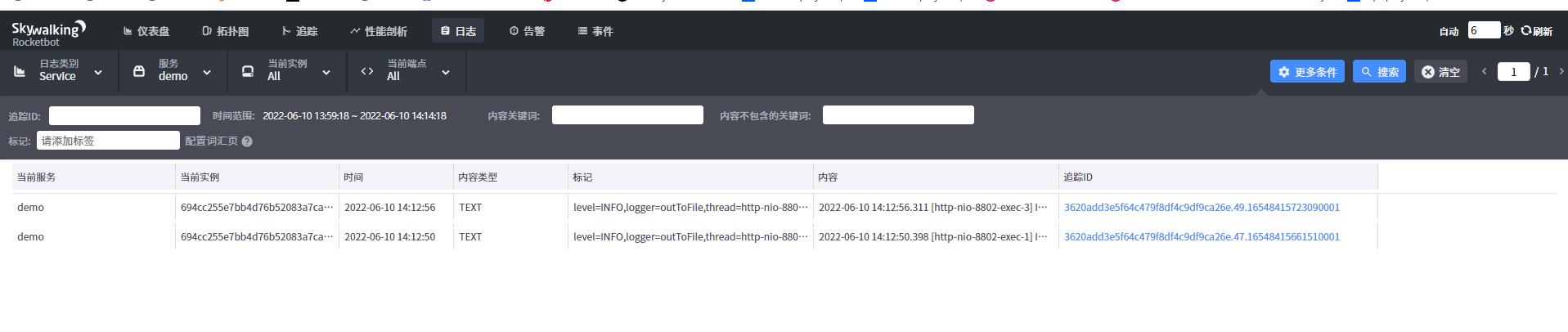
也可以在其追踪数据中查看起对应的日志


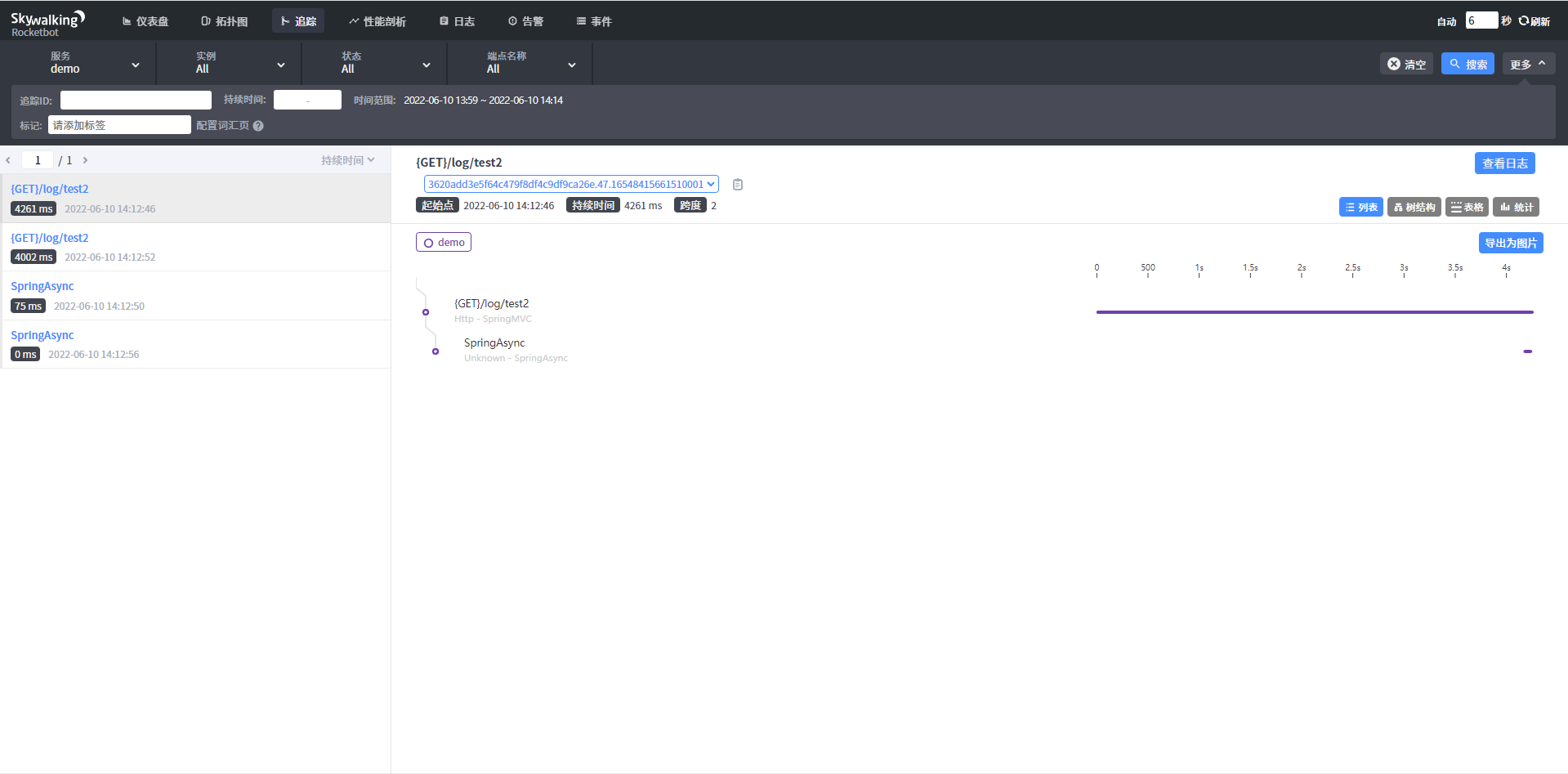
对某个接口/端点增加性能剖析,从而找出系统瓶颈
1、增加对应的端点对应进行性能剖析(故意对log/test2方法中sleep 4秒)
@GetMapping("/test2")
public Result<ArrayList<Map<String, Object>>> test2() throws InterruptedException {
final ArrayList<Map<String, Object>> maps = new ArrayList<>();
Thread.sleep(4000);
maps.add(new HashMap<String,Object>() {{
put("name","张三");
put("age",12);
}});
maps.add(new HashMap<String,Object>() {{
put("name","李四");
put("age",32);
}});
return Result.success(maps);
}

2、访问起对应的地址(http://127.0.0.1:8802/demo/log/test2?name=1&age=12&sex=1),在收集期间,尽量多访问几次,访问次数少有可能无法采集到
3、查看相应的分析报告,从而找出具体瓶颈
点击分析就会出现如下图所示信息
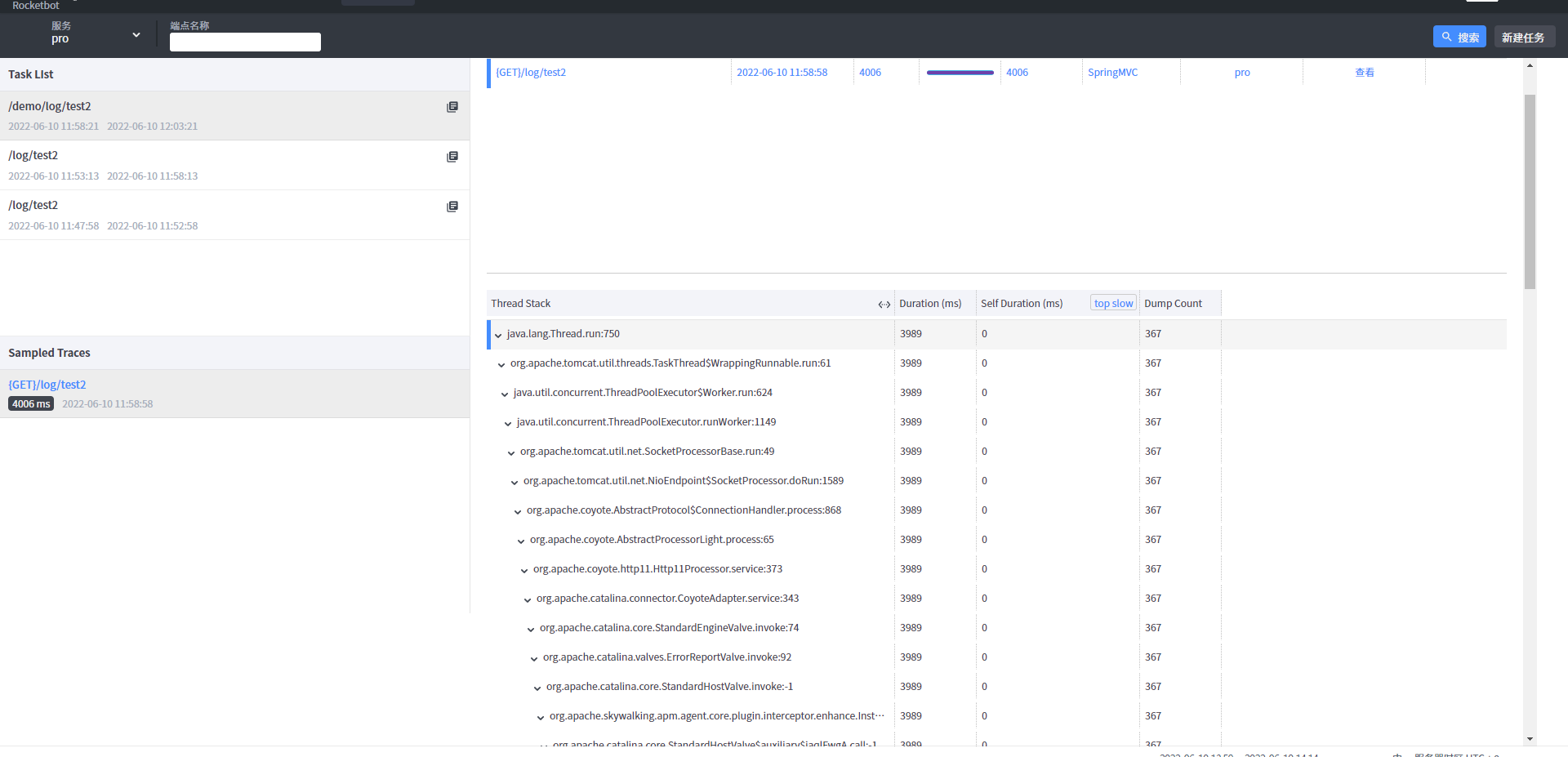
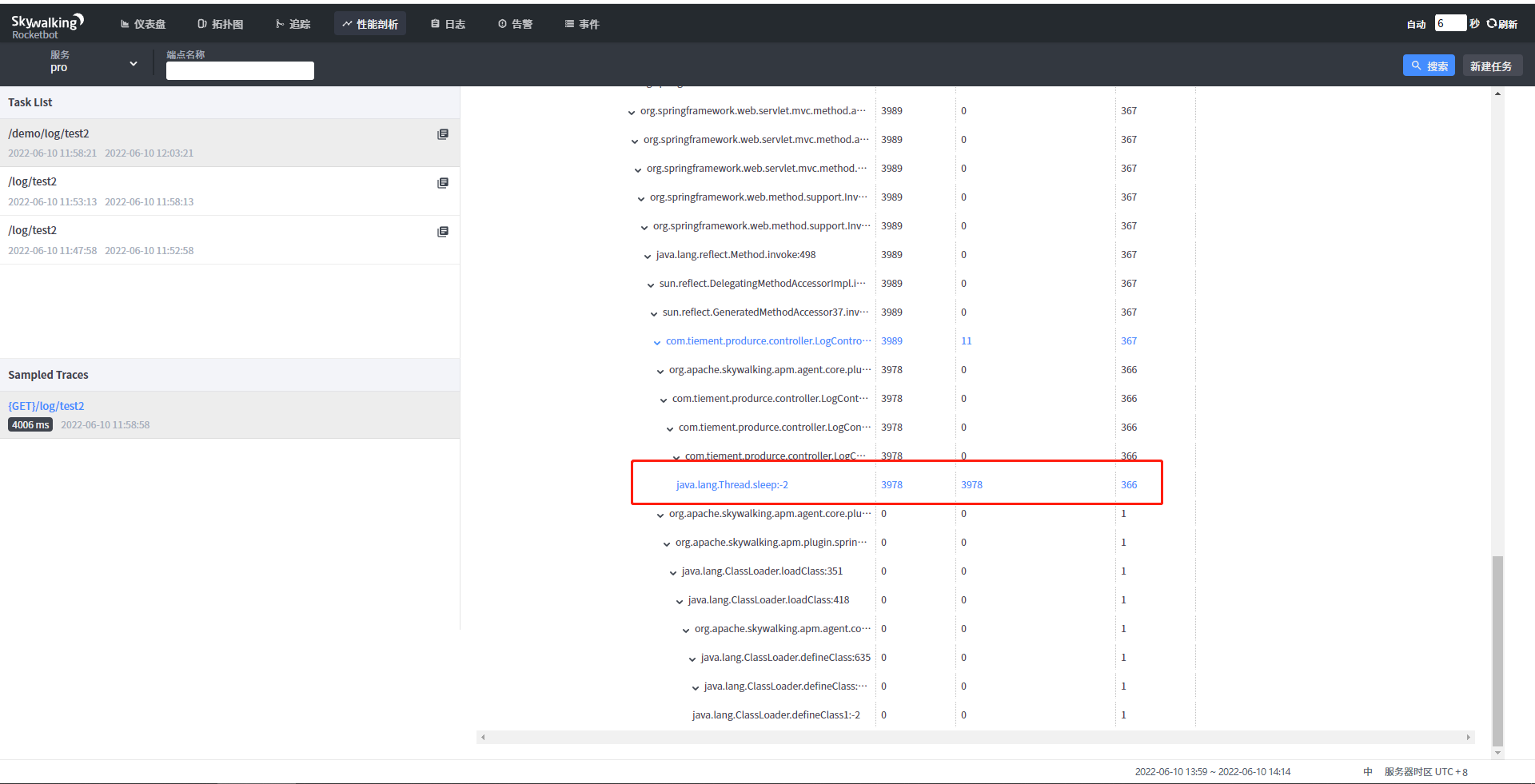
通过分析可以看出耗时的主要控制器和方法,以及对应的行号
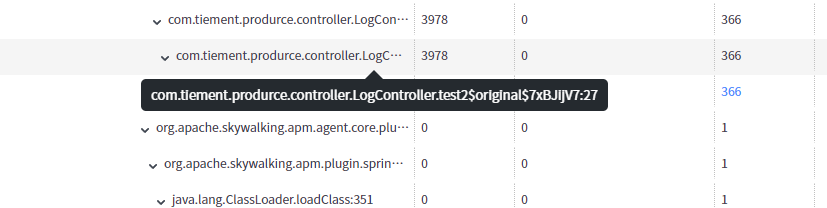

全链路栗子
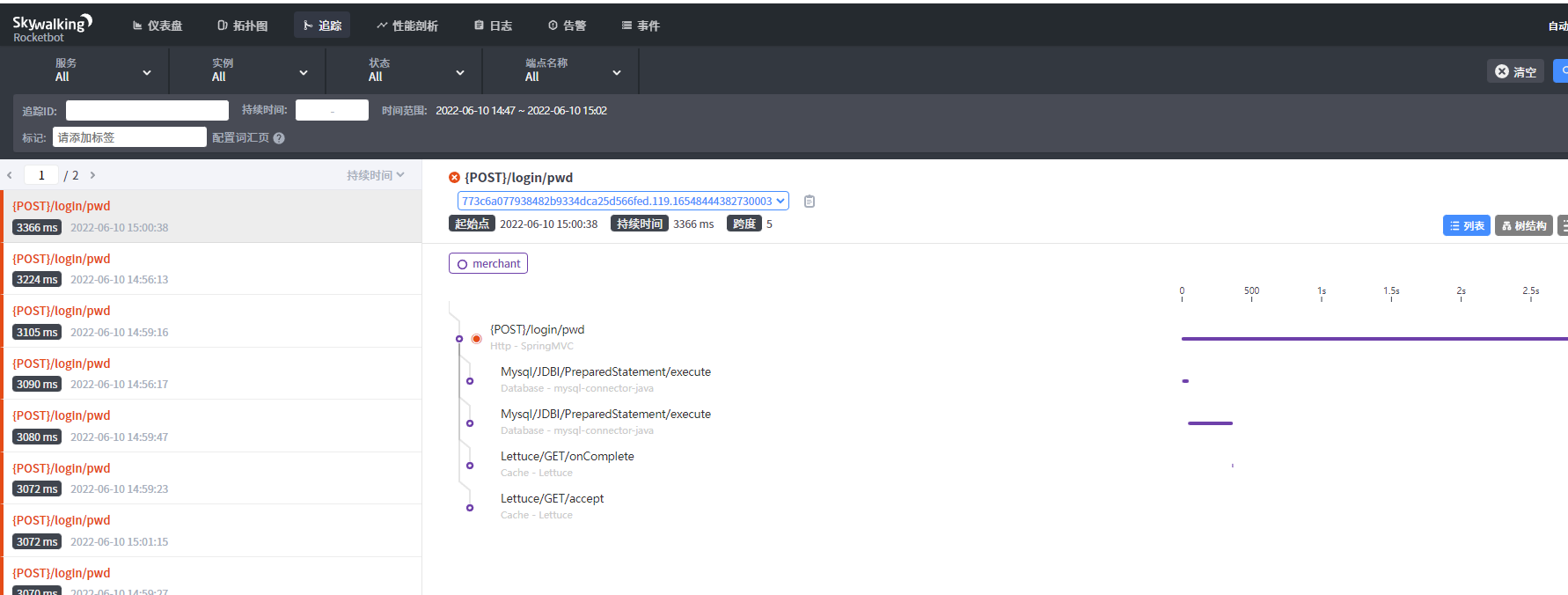
1、上述实例中并未涉及到对应的数据库和redis以及其他的服务交互,所以在拓扑图中看到的数据是非常单一的
2、如果在应用中有数据库、redis以及其他服务的调用在起拓扑图中会清晰的看到具体的调用关系,实例如下图:
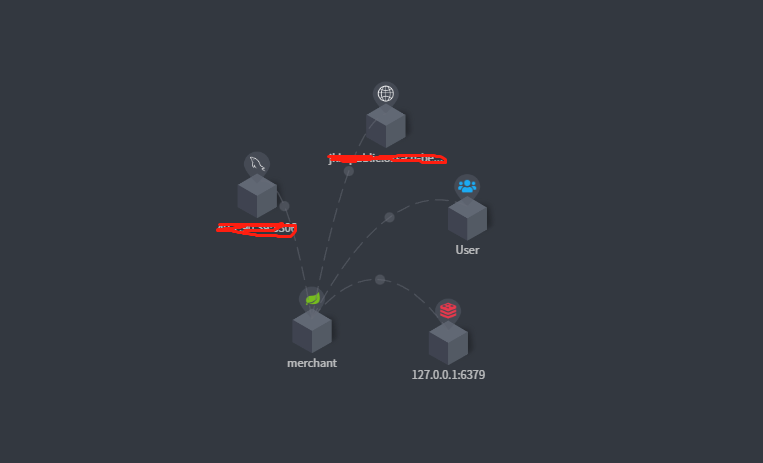
3、当其中一个服务不可用时,其拓扑图会标识某个业务为不健康的(红色),下图是因为手动关闭了redis的服务

4、接口请求异常会在相对应的追踪页面看到红色标注的信息,通过点击查看日志可以看到报错信息

全链路追踪 & 性能监控工具 SkyWalking 实战的更多相关文章
- skywalking与pinpoint全链路追踪方案对比
由于公司目前有200多微服务,微服务之间的调用关系错综复杂,调用关系人工维护基本不可能实现,需要调研一套全链路追踪方案,初步调研之后选取了skywalking和pinpoint进行对比; 选取skyw ...
- 【AWS】使用X-Ray做AWS云上全链路追踪监控系统
功能 AWS X-Ray 是一项服务,收集应用程序所请求的相关数据,并提供用于查看.筛选和获取数据洞察力的工具,以确定问题和发现优化的机会. 对于任何被跟踪的对您应用程序的请求,不仅可以查看请求和响应 ...
- go微服务框架kratos学习笔记九(kratos 全链路追踪 zipkin)
目录 go微服务框架kratos学习笔记九(kratos 全链路追踪 zipkin) zipkin使用demo 数据持久化 go微服务框架kratos学习笔记九(kratos 全链路追踪 zipkin ...
- Node.js 应用全链路追踪技术——[全链路信息获取]
全链路追踪技术的两个核心要素分别是 全链路信息获取 和 全链路信息存储展示. Node.js 应用也不例外,这里将分成两篇文章进行介绍:第一篇介绍 Node.js 应用全链路信息获取, 第二篇介绍 N ...
- 全链路追踪traceId,ThreadLocal与ExecutorService
关于全链路追踪traceId遇到线程池的问题,做过架构的估计都遇到过,现在以写个demo,总体思想就是获取父线程traceId,给子线程,子线程用完移除掉. mac上的chrome时不时崩溃,写了一大 ...
- 基于SLF4J的MDC机制和Dubbo的Filter机制,实现分布式系统的日志全链路追踪
原文链接:基于SLF4J的MDC机制和Dubbo的Filter机制,实现分布式系统的日志全链路追踪 一.日志系统 1.日志框架 在每个系统应用中,我们都会使用日志系统,主要是为了记录必要的信息和方便排 ...
- Node.js 应用全链路追踪技术——全链路信息存储
作者:vivo 互联网前端团队- Yang Kun 本文是上篇文章<Node.js 应用全链路追踪技术--全链路信息获取>的后续.阅读完,再来看本文,效果会更佳哦. 本文主要介绍在Node ...
- 全链路追踪技术选型:pinpoint vs skywalking
目前分布式链路追踪系统基本都是根据谷歌的<Dapper大规模分布式系统的跟踪系统>这篇论文发展而来,主流的有zipkin,pinpoint,skywalking,cat,jaeger等. ...
- java各种链路工具性能监控工具
Zipkin , Instana 和 Jaeger cat链路追踪系统 用于监控spring 的运行情况,比如内存,线程,池等宏观数据 spring boot admin java反编译 jar xv ...
- Spring Cloud全链路追踪实现(Sleuth+Zipkin+RabbitMQ+ES+Kibana)
简介 在微服务架构下存在多个服务之间的相互调用,当某个请求变慢或不可用时,我们如何快速定位服务故障点呢?链路追踪的实现就是为了解决这一问题,本文采用Sleuth+Zipkin+RabbitMQ+ES+ ...
随机推荐
- Deformable DETR:商汤提出可变型 DETR,提点又加速 | ICLR 2021 Oral
DETR能够消除物体检测中许多手工设计组件的需求,同时展示良好的性能.但由于注意力模块在处理图像特征图方面的限制,DETR存在收敛速度慢和特征分辨率有限的问题.为了缓解这些问题,论文提出了Deform ...
- manim边学边做--圆形类
在manim的丰富图形库中,圆形类是一个基础且强大的模块.无论是简单的圆形绘制,还是复杂的圆形变换,它都能以简洁的代码实现. manim中圆形类的相关模块主要有3个: Circle:标准的圆形 Ann ...
- 为什么要加 REQUIRE8 and PRESERVE8? 栈的8字节对齐
REQUIRE8 and PRESERVE8 The REQUIRE8 and PRESERVE8 directives specify that the current file require ...
- 可以调用Null的实例方法吗?
前几天有个网友问我一个问题:调用实例方法的时候为什么目标对象不能为Null.看似一个简单的问题,还真不是一句话就能说清楚的.而且这个结论也不对,当我们调用定义在某个类型的实例时,目标对象其实可以为Nu ...
- SLAB:华为开源,通过线性注意力和PRepBN提升Transformer效率 | ICML 2024
论文提出了包括渐进重参数化批归一化和简化线性注意力在内的新策略,以获取高效的Transformer架构.在训练过程中逐步将LayerNorm替换为重参数化批归一化,以实现无损准确率,同时在推理阶段利用 ...
- 关于Protobuf在使用中的一些注意点
Protobuf是谷歌旗下的一款二进制序列化协议 协议的编写 在项目中新建一个xxx.proto文件 文件的格式 第一行写protobuf的版本 syntax = "proto3" ...
- Modbus ASCII 获取数据
根据银河高低温试验箱协议读取数据 1.协议内容 8.1:通讯协议介绍 8.1.5 通讯设置 本通讯协议使用异步串行通讯方式,1 个起始位.8 个数据位.2 个停止 位.无奇偶校验数据通讯格式,其中数据 ...
- springjdbc处理nvarchar
当我们使用spring-jdbc来做持久化时(注意不是spring-data-jbc),有时候一些特殊字符存入数据库时会用到nvarchar.nvarchar2这种类型(比如存放化学式,如CO₂等), ...
- in notin exists not exists 性能优化算法总结
in notin exists not exists 性能优化算法总结 1.1. in 和 exists 区别 1.2. not in 能不能走索引 1.3. not in 和 join 的关系 1. ...
- Goby 漏洞发布|泛微 e-cology v10 appThirdLogin 权限绕过漏洞【漏洞复现】
漏洞名称:泛微 e-cology v10 appThirdLogin 权限绕过漏洞 English Name:Weaver e-cology v10 appThirdLogin Permission ...