CUDA编程学习 (1)——CUDA C介绍
1. 内存分配和数据移动 API 函数
CUDA编程模型是一个异构模型,需要CPU和GPU协同工作。在CUDA中,host 和 devic e 是两个重要的概念,我们用host指代CPU及其内存,而用device指代GPU及其内存。
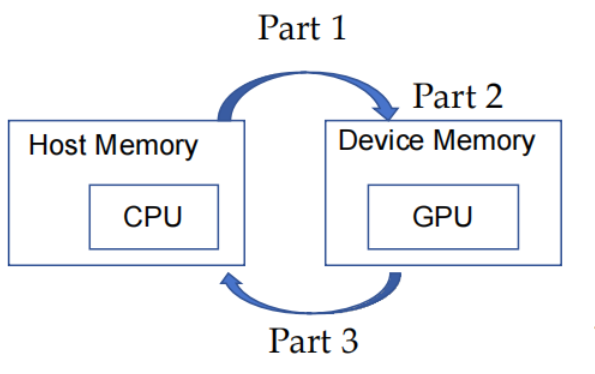
CUDA程序中既包含host程序,又包含device程序,它们分别在CPU和GPU上运行。同时,host与device之间可以进行通信,这样它们之间可以进行数据拷贝。典型的CUDA程序的执行流程如下:
- 分配host内存,并进行数据初始化;
- 分配device内存,并从host将数据拷贝到device上;
- 调用CUDA的核函数在device上完成指定的运算;
- 将device上的运算结果拷贝到host上;
- 释放device和host上分配的内存。
#include <cuda.h>
void vecAdd(float *h_A, float *h_B, float *h_C, int n){
int size = n* sizeof(float);
float *d_A, *d_B, *d_C;
// Part 1
// 为 A,B,C 分配 device 内存
// copy A 和 B 到 device 内存
// Part 2
// 内核启动代码 - 设备执行实际的矢量加法
// Part 3
// 从 device 内存 copy C
}
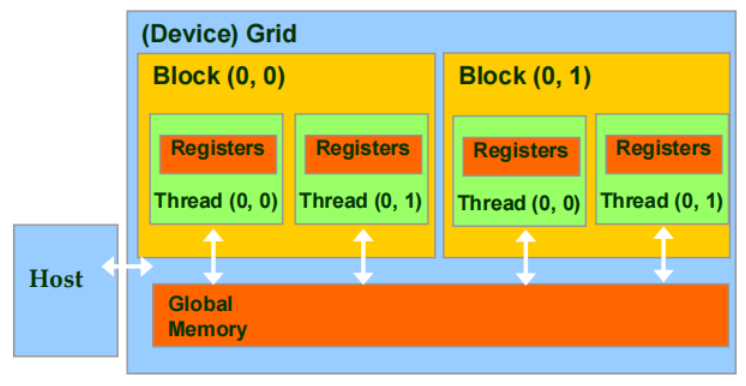
Device 代码可以:
- 写/读 per-thread register
- 写/读 all-shared global memory
Host 代码可以:
- 将数据传输到每个 grid global memory / 从每个 grid global memory 传输数据
1.1 Device Memory 管理 API

cudaMalloc()
在 device global memory 中分配一个对象
两个参数
- 分配对象指针的地址
- 分配对象的大小(以字节为单位)
cudaFree()
- 从 device global memory 中释放对象
- 一个参数
- 释放对象的指针
1.2 Host-Device 数据传输 API
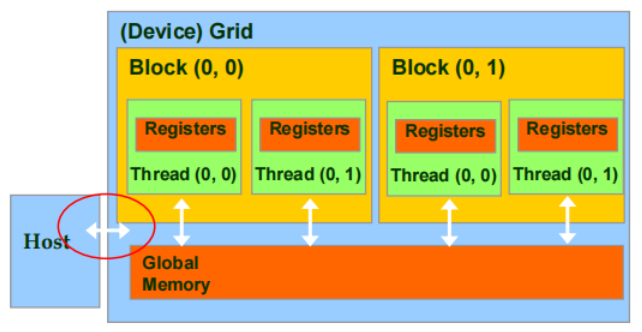
cudaMemCpy()
内存数据传输
4个参数
- 目的地指针
- 源指针
- 复制的字节数
- 传输类型/方向
与 host 同步向 device 传输数据
1.3 矢量加法-显式内存管理

1.4 统一内存(Unified Memory)
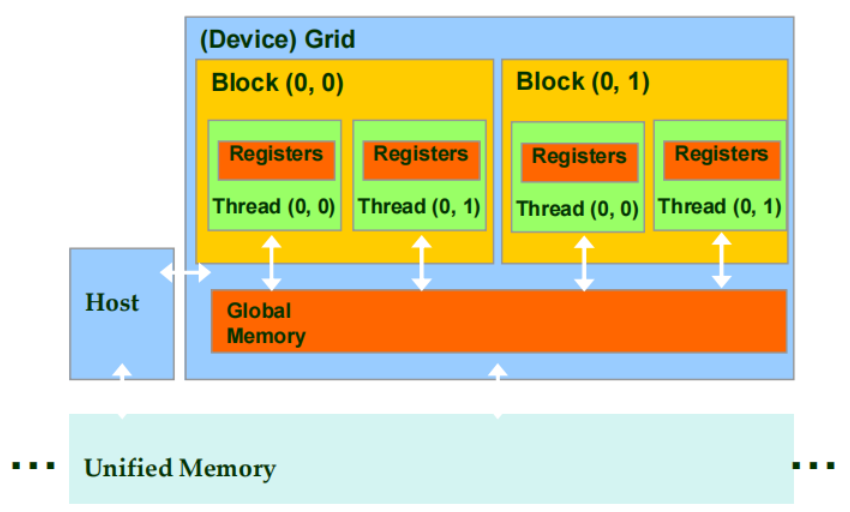
cudaMallocManaged(void** ptr, size_t size)
统一内存是 CPU 和 GPU 共享的相同内存空间。这意味着,CPU 和 GPU 使用相同的地址空间,无需像传统的 CUDA 编程那样手动管理内存传输(如
cudaMemcpy())。- 它维持数据的单一副本,即不再需要独立的主机内存和设备内存副本。
CUDA-managed 数据
- 其中
ptr是指向分配内存的指针,size是所需内存的大小。 - 按需页面迁移:在GPU执行代码时,所需的数据会按需从主机(Host)迁移到设备(Device)。
- 其中
与
cudaMalloc()和cudaFree()兼容可优化
- cudaMemAdvise(): 给CUDA提供建议,提示内存的使用模式(例如,数据主要在哪个处理器上使用)。
- cudaMemPrefetchAsync(): 允许程序员预取数据到设备或主机,减少内存访问延迟。
- cudaMemcpyAsync(): 在异步传输数据时,可以优化性能。
1.5 矢量加法-统一内存

1.6 检查 host 代码中的 API 错误
cudaError_t err = cudaMalloc((void **) &d_A, size);
if(err != cudaSuccess){
printf("%s in %s at line %d\n", cudaGetErrorString(err), __FILE__, __LINE__);
exit(EXIT_FAILURE);
}
2. 线程和内核函数
2.1 Kernel 线程层次结构
首先GPU上很多并行化的轻量级线程,kernel 在 device 上执行时实际上是启动很多线程。
一个 kernel 所启动的所有线程称为一个网格(grid),同一个网格上的线程共享相同的 global memory,grid 是线程结构的第一层次,而网格又可以分为很多 线程块(block),一个线程块里面包含很多线程,这是第二个层次。
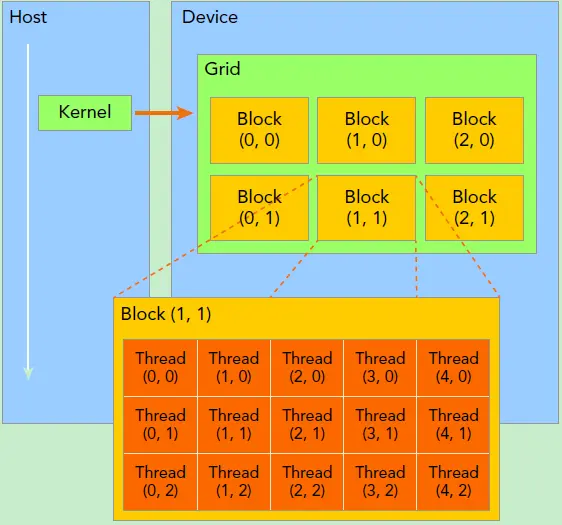
2.2 数据并行 - 向量加法示例
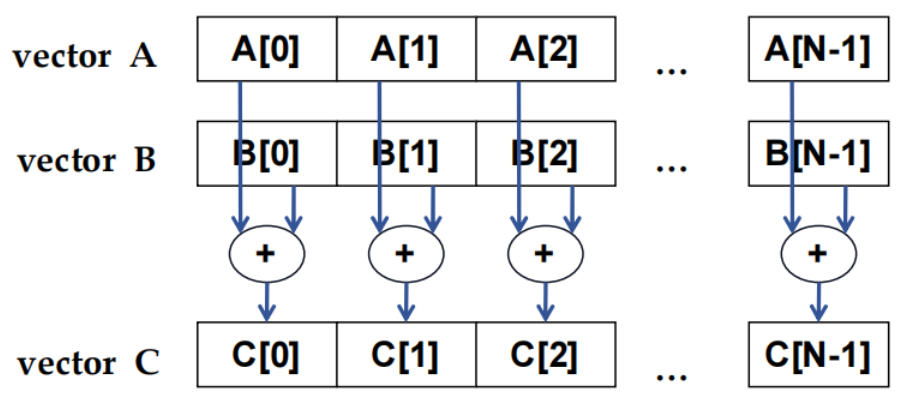
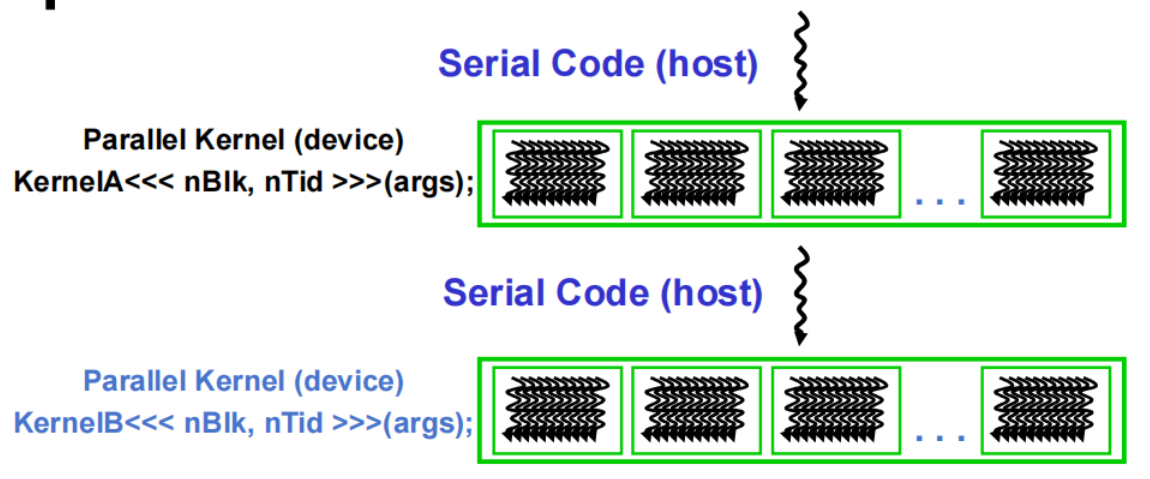
2.3 CUDA 执行模型
- 异构 host(CPU)+ device(GPU)应用 C 程序
- host C 代码中的串行部件
- device SPMD 内核代码中的并行部分
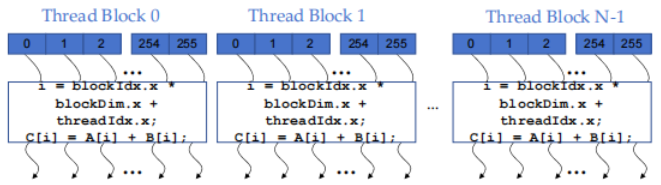
2.4 并行 thread 阵列
- CUDA kernel 由 threads 组成的一个 grid(array)执行
- grid 中的所有 thread 运行相同的 kernel 代码(单程序多数据)
- 每个 thread 都有索引,用于计算内存地址和做出控制决定

2.4.1 线程块:可扩展的协作
- 将 thread array 划分为多个 block
- block 内的 thread 通过 共享内存(shared memory)、原子操作(atomic operations)和障碍同步(barrier synchronization)进行协作
- 不同 block 中的 thread 不会相互影响
2.4.2 block 索引和 thread 索引

每个 thread 使用索引来决定处理哪些数据
- blockIdx:1D, 2D or 3D (CUDA 4.0)
- threadIdx:1D, 2D or 3D
处理多维数据时简化内存寻址
- 图像处理
- 解决体积上的 PDEs
对于一个 2-dim 的 \(block(D_x,D_y)\),线程 \((x,y)\) 的 ID 值为 \((x+y∗D_x)\) ,如果是 3-dim 的 \(block(D_x,D_y,D_z)\),线程 \((x,y,z)\) 的ID值为 \((x+y∗D_x+z∗D_x∗D_y)\) 。另外线程还有内置变量 gridDim,用于获得网格块各个维度的大小。
3. CUDA 工具包简介
3.1 NVCC Compiler
- 英伟达(NVIDIA)提供 CUDA-C 编译器,简单的编译命令为:
nvcc vectorAdd.cu -o vectorAdd
这将使用默认参数编译 vectorAdd.cu,并输出一个叫 vectorAdd 的可执行文件。
nvcc编译设备代码,然后将代码转发给 host 编译器(如 g++)。可用于编译和链接 host 应用程序
两种源文件:
对于 CUDA 程序,我们通常有:
- .cu 文件:包含 CUDA C/C++ 代码,包括主程序代码和 CUDA kernels,需要
nvcc编译。 - .cpp/.c 文件:只包含主程序代码,不含 CUDA kernels,可以用
gcc/g++编译。
编译 CUDA 程序的一般步骤是:
- 用
nvcc编译 .cu 文件,生成 .o 文件。 - 用
g++编译 .cpp 文件,也生成 .o 文件。 - 再用
g++/nvcc链接所有 .o 文件生成最终可执行文件。
nvcc -c demo.cu -o demo.o
g++ -c main.cpp -o main.o
nvcc demo.o main.o -o demo -lcudart
3.2 调试工具(Debugger)
- NVIDIA 提供的调试工具
- Nsight:这是一个用于 GPU 编程调试和优化的工具,专门设计用来分析 GPU 代码的性能问题,并进行代码调试。支持对 CUDA 和 OpenGL 等代码进行深入的分析。
- Nsight Systems:一个面向系统级性能分析的工具,可以帮助开发者查找瓶颈,了解程序在 CPU 和 GPU 之间的负载分布。
- CUDA-GDB:这是一个基于 GDB 的调试器,专门用于 CUDA 编程的调试工作,支持查看 GPU 上的内存状态、线程执行情况等。
- CUDA MEMCHECK:用于检测 CUDA 代码中的内存错误,包括非法内存访问、未初始化内存使用等,类似于 CPU 上的 valgrind 工具。
- 第三方调试工具
- ARM Forge:支持跨平台的高性能计算(HPC)调试工具,适用于调试大规模并行程序,包括CUDA应用。
- TotalView:另一个广泛使用的高性能并行调试器,适用于调试复杂的CUDA程序,提供对多核、多线程代码的深入支持。
3.3 性能分析工具(Profilers)
NVIDIA 提供的性能分析工具
- NSIGHT:与调试工具一样,Nsight 还可用于性能分析,帮助开发者分析 GPU 代码的瓶颈、内存使用、指令执行效率等。它支持 CUDA、OpenGL 和 Vulkan 等多种 API。
- NVVP(NVIDIA Visual Profiler):专门为 CUDA 程序设计的图形化性能分析工具,提供可视化的性能瓶颈分析,帮助开发者定位代码中导致性能下降的具体部分。
- NVPROF:是一个命令行性能分析工具,专注于 CUDA 程序的性能数据收集。它可以通过收集时间信息、内存传输、计算效率等指标,提供详细的性能分析结果。
第三方性能分析工具
- TAU:一款适用于并行程序的全面性能分析工具,支持多种硬件架构和 API,帮助用户从全局上评估程序的性能表现。
- VampirTrace:一个可视化的性能分析工具,用于追踪并行程序的执行情况,帮助开发者分析程序的时间线、通信延迟等。
4. Nsight 计算和 Nsight 系统

Phasing Out(逐步淘汰的工具)
- NVPROF
- NVVP(NVIDIA Visual Profiler)
Current(当前主流的工具)
- Nsight Compute
- Nsight Systems
参考文献
[1] CUDA编程入门极简教程 - 知乎 (zhihu.com)
[2] nvcc 编译 .cu 源代码的基本用法_多个文件 nvcc怎么编译-CSDN博客
CUDA编程学习 (1)——CUDA C介绍的更多相关文章
- CUDA编程学习笔记1
CUDA编程模型是一个异构模型,需要CPU和GPU协同工作. host和device host和device是两个重要的概念 host指代CPU及其内存 device指代GPU及其内存 __globa ...
- CUDA编程学习相关
1. CUDA编程之快速入门:https://www.cnblogs.com/skyfsm/p/9673960.html 2. CUDA编程入门极简教程:https://blog.csdn.net/x ...
- CUDA编程学习(一)
/****c code****/ #include<stdio.h> int main() { printf("Hello world!\n); ; } /****CUDA co ...
- cuda编程学习6——点积dot
__shared__ float cache[threadPerBlock];//声明共享内存缓冲区,__shared__ __syncthreads();//对线程块中的线程进行同步,只有都完成前面 ...
- cuda编程学习5——波纹ripple
/共有DIM×DIM个像素,每个像素对应一个线程dim3 blocks(DIM/16,DIM/16);//2维dim3 threads(16,16);//2维kernel<<<blo ...
- cuda编程学习4——Julia
书上的例子编译会有错误,修改一下行即可. __device__ cuComplex(float a,float b):r(a),i(b){} /* ========================== ...
- cuda编程学习3——VectorSum
这个程序是把两个向量相加 add<<<N,1>>>(dev_a,dev_b,dev_c);//<N,1>,第一个参数N代表block的数量,第二个参数1 ...
- cuda编程学习2——add
cudaMalloc()分配的指针有使用限制,设备指针的使用限制总结如下: 1.可以将其传递给在设备上执行的函数 2.可以在设备代码中使用其进行内存的读写操作 3.可以将其传递给在主机上执行的函数 4 ...
- cuda编程学习1——hello world!
将c程序最简单的hello world用cuda编写在GPU上执行,以下为代码: #include<iostream>using namespace std;__global__ void ...
- CUDA编程学习笔记2
第二章 cuda代码写在.cu/.cuh里面 cuda 7.0 / 9.0开始,NVCC就支持c++11 / 14里面绝大部分的语言特性了. Dim3 __host__ __device__ dim3 ...
随机推荐
- cloud compare二次插件化功能开发详细步骤(一)
点云处理,有一个出名的处理软件,cloud compare,简称 cc,将自己实现的功能以插件形式集成到 CC 里,方便使用 前提 环境:cc 2.13,qt 5.15,cmake 3.18,vs20 ...
- NYX靶机笔记
NYX靶机笔记 概述 VulnHub里的简单靶机 靶机地址:https://download.vulnhub.com/nyx/nyxvm.zip 1.nmap扫描 1)主机发现 # -sn 只做pin ...
- Windows C 盘瘦身
修改 Window 服务器虚拟内存位置 | 博客园 怎么更改电脑默认储存位置呢?| CSDN Win11 磁盘清理怎么没有了?Win11 磁盘清理在哪打开?| 搜狐网 快速清理 Windows 大文件 ...
- 浅触go中的单元测试
对于一个写好的功能模块,我们还需要对其进行单元测试,确保该模块不会出现其他bug,或者输出不是期望结果 对于一个go程序,主要设计以下命令: 执行测试 go test -v / go test 执行某 ...
- csdn 下载券恶心之处
今天在csdn碰到一个恶心事,啥事呢?下载券.详细的说,就是人家码友把下载积分都设置成0了,让大家自行下载.结果,却不行,非得搞个下载券,得去做任务,给它的广告爹爹们点点任务才能获取下载券的code. ...
- Unity中利用遗传算法训练MLP
Unity中利用遗传算法训练MLP 梯度下降法训练神经网络通常需要我们给定训练的输入-输出数据,而用遗传算法会便捷很多,它不需要我们给定好数据,只需要随机化多个权重进行N次"繁衍进化&quo ...
- SQL Server 备份方案
参考 SQL Server三种常见备份 SQL Server备份策略 以前写的笔记 目的 在发生意外 (人为删除, 磁盘坏掉) 之后, 让数据可还原到指定时间点上. Backup 的种类 备份分 3 ...
- PTA甲级—树
1.树的遍历 1004 Counting Leaves (30分) 基本的数据结构--树,复习了链式前向星,bfs遍历判断即可 #include <cstdio> #include < ...
- Java序列化、反序列化、反序列化漏洞
目录 1 序列化和反序列化 1.1 概念 1.2 序列化可以做什么? 3 实现方式 3.1 Java 原生方式 3.2 第三方方式 4 反序列化漏洞 1 序列化和反序列化 1.1 概念 Java 中序 ...
- [The Trellor] Chapter 1
翻译软件真的翻不好,读英文小说要相信你的脑子. There's only one thing to do in Berlen - that is listening the sound of wind ...