十六 web爬虫讲解2—PhantomJS虚拟浏览器+selenium模块操作PhantomJS
PhantomJS虚拟浏览器
phantomjs 是一个基于js的webkit内核无头浏览器 也就是没有显示界面的浏览器,利用这个软件,可以获取到网址js加载的任何信息,也就是可以获取浏览器异步加载的信息
下载网址:http://phantomjs.org/download.html 下载对应系统版本
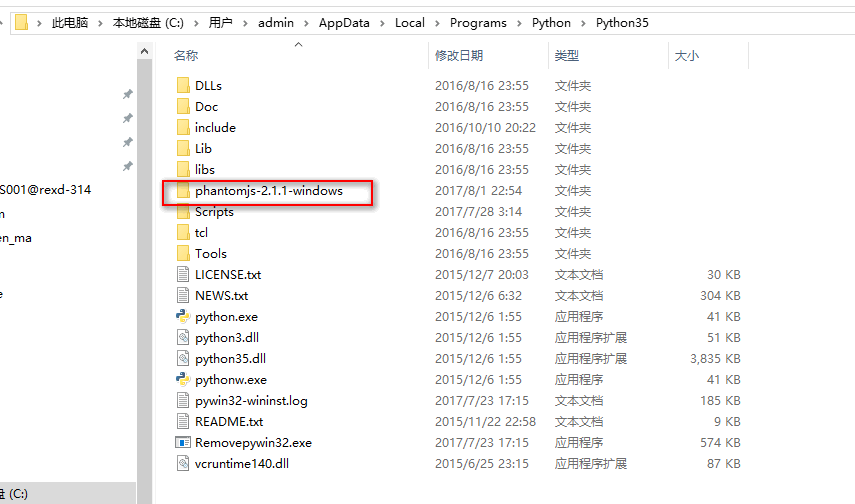
下载后解压PhantomJS文件,将解压文件夹,剪切到python安装文件夹
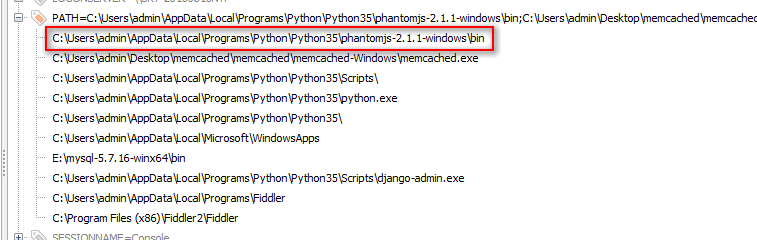
然后将PhantomJS文件夹里的bin文件夹添加系统环境变量
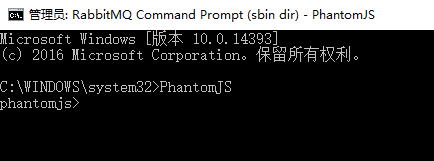
cdm 输入命令:PhantomJS 出现以下信息说明安装成功
selenium模块是一个python操作PhantomJS软件的一个模块
selenium模块PhantomJS软件
webdriver.PhantomJS()实例化PhantomJS浏览器对象
get('url')访问网站
find_element_by_xpath('xpath表达式')通过xpath表达式找对应元素
clear()清空输入框里的内容
send_keys('内容')将内容写入输入框
click()点击事件
get_screenshot_as_file('截图保存路径名称')将网页截图,保存到此目录
page_source获取网页htnl源码
quit()关闭PhantomJS浏览器

#!/usr/bin/env python
# -*- coding:utf8 -*-
from selenium import webdriver #导入selenium模块来操作PhantomJS
import os
import time
import re llqdx = webdriver.PhantomJS() #实例化PhantomJS浏览器对象
llqdx.get("https://www.baidu.com/") #访问网址 # time.sleep(3) #等待3秒
# llqdx.get_screenshot_as_file('H:/py/17/img/123.jpg') #将网页截图保存到此目录 #模拟用户操作
llqdx.find_element_by_xpath('//*[@id="kw"]').clear() #通过xpath表达式找到输入框,clear()清空输入框里的内容
llqdx.find_element_by_xpath('//*[@id="kw"]').send_keys('叫卖录音网') #通过xpath表达式找到输入框,send_keys()将内容写入输入框
llqdx.find_element_by_xpath('//*[@id="su"]').click() #通过xpath表达式找到搜索按钮,click()点击事件 time.sleep(3) #等待3秒
llqdx.get_screenshot_as_file('H:/py/17/img/123.jpg') #将网页截图,保存到此目录 neir = llqdx.page_source #获取网页内容
print(neir)
llqdx.quit() #关闭浏览器 pat = "<title>(.*?)</title>"
title = re.compile(pat).findall(neir) #正则匹配网页标题
print(title)
PhantomJS浏览器伪装,和滚动滚动条加载数据
有些网站是动态加载数据的,需要滚动条滚动加载数据
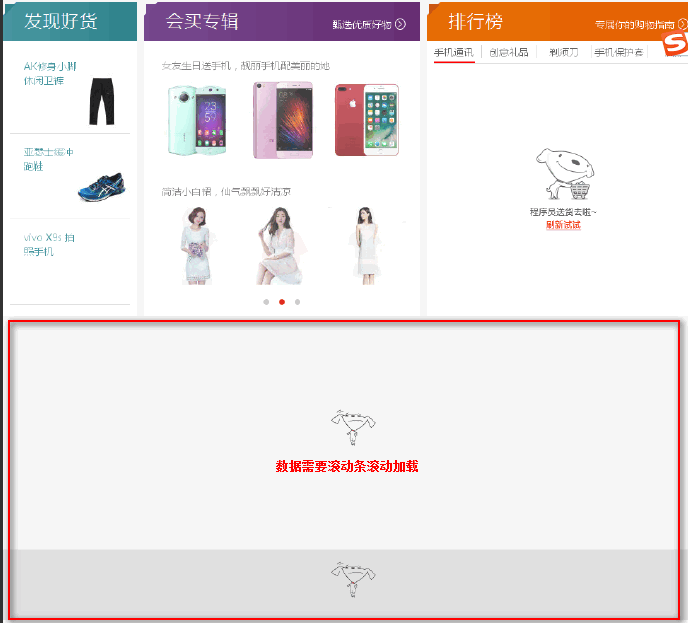
实现代码
DesiredCapabilities 伪装浏览器对象
execute_script()执行js代码
current_url获取当前的url
#!/usr/bin/env python
# -*- coding:utf8 -*-
from selenium import webdriver #导入selenium模块来操作PhantomJS
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities #导入浏览器伪装模块
import os
import time
import re dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap['phantomjs.page.settings.userAgent'] = ('Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0')
print(dcap)
llqdx = webdriver.PhantomJS(desired_capabilities=dcap) #实例化PhantomJS浏览器对象 llqdx.get("https://www.jd.com/") #访问网址 #模拟用户操作
for j in range(20):
js3 = 'window.scrollTo('+str(j*1280)+','+str((j+1)*1280)+')'
llqdx.execute_script(js3) #执行js语言滚动滚动条
time.sleep(1) llqdx.get_screenshot_as_file('H:/py/17/img/123.jpg') #将网页截图,保存到此目录 url = llqdx.current_url
print(url) neir = llqdx.page_source #获取网页内容
print(neir)
llqdx.quit() #关闭浏览器 pat = "<title>(.*?)</title>"
title = re.compile(pat).findall(neir) #正则匹配网页标题
print(title)
十六 web爬虫讲解2—PhantomJS虚拟浏览器+selenium模块操作PhantomJS的更多相关文章
- 第三百三十七节,web爬虫讲解2—PhantomJS虚拟浏览器+selenium模块操作PhantomJS
第三百三十七节,web爬虫讲解2—PhantomJS虚拟浏览器+selenium模块操作PhantomJS PhantomJS虚拟浏览器 phantomjs 是一个基于js的webkit内核无头浏览器 ...
- 十二 web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
模拟浏览器登录 start_requests()方法,可以返回一个请求给爬虫的起始网站,这个返回的请求相当于start_urls,start_requests()返回的请求会替代start_urls里 ...
- 十四 web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
打码接口文件 # -*- coding: cp936 -*- import sys import os from ctypes import * # 下载接口放目录 http://www.yundam ...
- 六 web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode("utf-8")将字节转化成字符串 ...
- 十五 web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
在urllib中,我们一样可以使用xpath表达式进行信息提取,此时,你需要首先安装lxml模块,然后将网页数据通过lxml下的etree转化为treedata的形式 urllib库中使用xpath表 ...
- 第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础 在urllib中,我们一样可以使用xpath表达式进行信息提取,此时,你需要首先安装lxml模块 ...
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码 打码接口文件 # -*- coding: cp936 -*- import sys import os ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- 第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录 模拟浏览器登录 start_requests()方法,可以返回一个请求给爬虫的起始网站,这个返回的请求相当于star ...
随机推荐
- docker——容器(container)
容器相关命令一览表: docker create docker run docker start/stop/restart docker attach/exec docker rm docker ex ...
- Vmwaretools
先下载Vmwaretools 这一步是设置ubuntu的超级用户root的密码我设置为dong 转换为root用户操作 执行 perl程序 然后就是一路Enter,开始关机重启就行了 来自为知笔记 ...
- PKU 1573 Robot Motion(简单模拟)
原题大意:原题链接 给出一个矩阵(矩阵中的元素均为方向英文字母),和人的初始位置,问是否能根据这些英文字母走出矩阵.(因为有可能形成环而走不出去) 此题虽然属于水题,但是完全独立完成而且直接1A还是很 ...
- Jenkins--持续集成服务器
1.持续集成: 1.1概念 持续集成,Continuous integration ,简称CI. 集成:我们所有项目的代码都是托管在SVN服务器上.每个项目都要有若干个单元测试,并有一个所谓集成测试. ...
- oracle中job定时器任务
对于DBA来说,经常要数据库定时的自动执行一些脚本,或做数据库备份,或做数据的提炼,或做数据库的性能优化,包括重建索引等等的工作.但是,Oracle定时器Job时间的处理上,千变万化,今天我把比较常用 ...
- ThinkPHP5显示数据库字段内容
1.在application文件夹下面的config.php中打开DEBUG. 2.修改tp5/application/index/controller/Index.php内容. <?php n ...
- 20145310 《Java程序设计》第1周学习总结
20145310 <Java程序设计>第1周学习总结 教材学习内容总结 第一周主要学习教材前两章的知识.第一章主要学习了java的历史,版本的迁移以及一些相关的专有名词之间的联系和下载安装 ...
- ubuntu下wget的配置文件在哪里
答:/etc/wgetrc 这个文件里可以指定代理,如: http_proxy = http://myproxy.com:8080
- 如何打开linux内核中dev_dbg的开关
比如要打开某个驱动中的dev_dbg,那么需要在驱动文件.c中这些行"<linux/device.h>"或者"<linux /platfom_devic ...
- com.mysql.jdbc.MysqlDataTruncation:Data Truncation:Data too long for column '字段name' at row 1
1.问题描述: 在mysql插入数据的时候报错:Cause: com.mysql.jdbc.MysqlDataTruncation: Data truncation: Data too long fo ...