利用自编码(Autoencoder)来提取输入数据的特征
自编码(Autoencoder)介绍
Autoencoder是一种无监督的学习算法,将输入信息进行压缩,提取出数据中最具代表性的信息。其目的是在保证重要特征不丢失的情况下,降低输入信息的维度,减小神经网络的处理负担。简单来说就是提取输入信息的特征。类似于主成分分析(Principal Components Analysis,PAC)
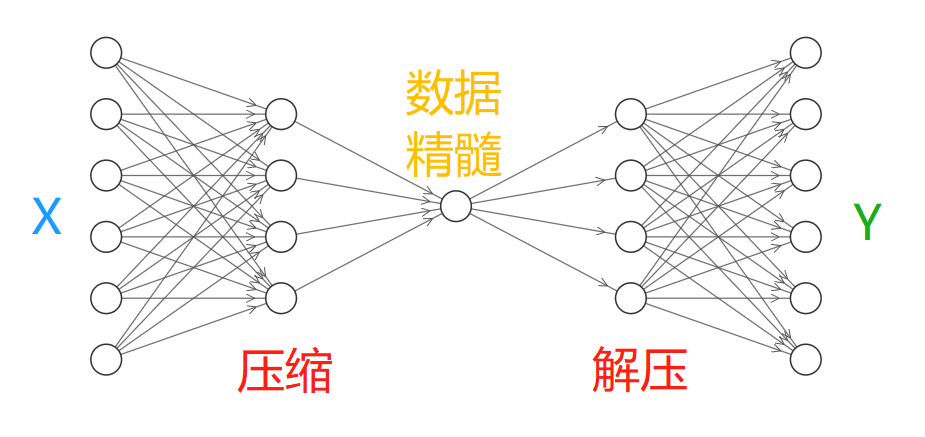
对于输入信息X,通过神经网络对其进行压缩,提取出数据的重要特征,然后将其解压得到数据Y,然后通过对比X与Y求出预测误差进行反向传递,逐步提升自编码的准确性。训练完成的自编码中间部分就是输入数据的精髓,实际使用中通常只会用到自编码的前半部分。
Tensorflow实现
用到的数据集
用到的数据集是Tensorflow模块中的mnist数据集,其中有70000个数字0-9的带标签图片样本,包含了60000个训练样本和10000个测试样本。
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=False) #读取文件
"/tmp/data/"为文件保存的位置,如果没有则会自动下载到该文件夹。"one_hot=False"表示返回一个长度为n的numpy数组.每个元素代表图片上的数字.
参数定义
# Parameter
learning_rate = 0.01 #学习率0.01
training_epochs = 5 # 五组训练
batch_size = 256 #批尺寸大小
display_step = 1 #每隔多少epoch显示打印一次cost
examples_to_show = 10 #显示多少张图片
网络输入inputs
n_input = 784 # mnist中图片的尺寸是28*28总共有784个像素特征
# tf Graph input (only pictures)
X = tf.placeholder("float", [None, n_input]) #定义网络的输入特征
隐藏层的权重weights和偏置biases定义
- 将输入进的784个Features,经过第一个隐藏层压缩到256个Features,然后经过第二个隐藏层压缩至128个。
- 在解压环节将128个Features还原至256,再到784.
- 将前后的784个特征进行对比,反向传递cost来提升自编码的准确度
# hidden layer settings
n_hidden_1 = 256 # 第一层隐藏层的特征数量
n_hidden_2 = 128 # 第二层的数量
weights = {
'encoder_h1':tf.Variable(tf.random_normal([n_input,n_hidden_1])), #[784,256]
'encoder_h2': tf.Variable(tf.random_normal([n_hidden_1,n_hidden_2])), #[256,128]
'decoder_h1': tf.Variable(tf.random_normal([n_hidden_2,n_hidden_1])), #[128,256]
'decoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_input])), #[256,784]
}
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])), #[256]
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])), #[128]
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_1])), #[256]
'decoder_b2': tf.Variable(tf.random_normal([n_input])), #[784]
}
定义压缩Encoder和解压Decoder层
使用的激活函数是sigmoid,压缩之后的值应该在[0,1],在decoder中激活函数一样
# Building the encoder
def encoder(x):
# Encoder Hidden layer with sigmoid activation #1
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
# Decoder Hidden layer with sigmoid activation #2
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
return layer_2
# Building the decoder
def decoder(x):
# Encoder Hidden layer with sigmoid activation #1
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
# Decoder Hidden layer with sigmoid activation #2
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
return layer_2
Encoder和Decoder的输出结果
encoder_op = encoder(X) # 128 Features
decoder_op = decoder(encoder_op) # 784 Features
# Prediction
y_pred = decoder_op # 预测值
y_true = X # 真实值(原始输入)
定义cost和训练
cost = tf.reduce_mean(tf.pow(y_true - y_pred, 2)) #cost为(y_true - y_pred)^2的均值
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost) #利用AdamOptimizer来训练
最后通过Matplotlib的pyplot来显示结果
with tf.Session() as sess:
init=tf.global_variables_initializer()
sess.run(init)
total_batch=int(mnist.train.num_examples/batch_size) #计算训练循环的次数
#train cycle
for epoch in range(training_epochs):
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
_, c = sess.run([optimizer, cost], feed_dict={X: batch_xs})
if epoch % display_step == 0: #输入经过每一个epoch后cost的值
print("Epoch:", '%04d' % (epoch + 1), #输出格式为Epoch:0001 cost=0.123456789
"cost=", "{:.9f}".format(c))
print("Optimization Finished!")
#在测试集上应用encoder和decoder
encode_decode = sess.run(
y_pred, feed_dict={X: mnist.test.images[:examples_to_show]})
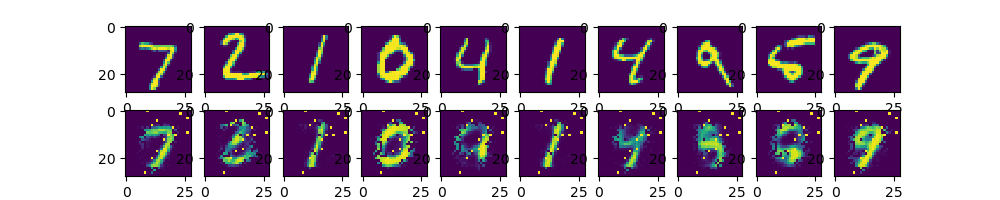
# 显示对比图像
f, a = plt.subplots(2, 10, figsize=(10, 2)) #定义画布
for i in range(examples_to_show):
a[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28)))
a[1][i].imshow(np.reshape(encode_decode[i], (28, 28)))
plt.show()
结果
Epoch: 0001 cost= 0.077869482
Epoch: 0002 cost= 0.070396304
Epoch: 0003 cost= 0.066303633
Epoch: 0004 cost= 0.062276978
Epoch: 0005 cost= 0.055230502
参考
本文内容来自于莫烦python,进行学习整理,非常感谢。
相关代码
利用自编码(Autoencoder)来提取输入数据的特征的更多相关文章
- Tensorf实战第九课(自编码AutoEncoder)
本节我们将了解神经网络进行非监督形式的学习,即autoencoder自编码 假设图片经过神经网络后再输出的过程,我们看作是图片先被压缩然后解压的过程.那么在压缩的时候,原有的图片质量被缩减,解压时用信 ...
- 利用Readability解决网页正文提取问题
分享: 利用Readability解决网页正文提取问题 做数据抓取和分析的各位亲们, 有没有遇到下面的难题呢? - 如何从各式各样的网页中提取正文!? 虽然可以用SS为各种网站写脚本做解析, 但是 ...
- Pytorch中的自编码(autoencoder)
Pytorch中的自编码(autoencoder) 本文资料来源:https://www.bilibili.com/video/av15997678/?p=25 什么是自编码 先压缩原数据.提取出最有 ...
- 利用sfntly的sfnttool.jar提取中文字体
雨忆博客中提到了sfntly(具体介绍可以看:https://code.google.com/p/sfntly/),利用其中sfnttool.jar就可以提取只包含指定字符的字体,如果想在页面中通过@ ...
- 利用ArcGIS水文分析工具提取河网
转自原文 利用ArcGIS水文分析工具提取河网(转) DEM包含有多种信息,ArcToolBox提供了利用DEM提取河网的方法,但是操作比较烦琐(帮助可参看Hydrologic analysis sa ...
- 等效介质理论模型---利用S参数反演法提取超材料结构的等效参数
等效介质理论模型---利用S参数反演法提取超材料结构的等效参数 S参数反演法,即利用等效模型的传输矩阵和S参数求解超材料结构的等效折射率n和等效阻抗Z的过程.本文对等效介质理论模型进行了详细介绍,并提 ...
- opencv java api提取图片sift特征
opencv在2.4.4版本以后添加了对java的最新支持,可以利用java api了.下面就是我利用opencv的java api 提取图片的sift特征. import org.opencv.co ...
- 机器学习入门-随机森林温度预测的案例 1.datetime.datetime.datetime(将字符串转为为日期格式) 2.pd.get_dummies(将文本标签转换为one-hot编码) 3.rf.feature_importances_(研究样本特征的重要性) 4.fig.autofmt_xdate(rotation=60) 对标签进行翻转
在这个案例中: 1. datetime.datetime.strptime(data, '%Y-%m-%d') # 由字符串格式转换为日期格式 2. pd.get_dummies(features) ...
- NLP用CNN分类Mnist,提取出来的特征训练SVM及Keras的使用(demo)
用CNN分类Mnist http://www.bubuko.com/infodetail-777299.html /DeepLearning Tutorials/keras_usage 提取出来的特征 ...
随机推荐
- Libev源码分析07:Linux下的eventfd简介
#include <sys/eventfd.h> int eventfd(unsigned int initval, int flags); eventfd创建一个eventfd对象,该对 ...
- @codeforces - 414E@ Mashmokh's Designed Problem
目录 @description@ @solution@ @accepted code@ @details@ @description@ 给定一棵 n 个点的树,每个点的儿子是有序的. 现给定 m 次操 ...
- protobuf_1
我使用的是最新版本的protobuf(protobuf-2.6.1),编程工具使用VS2010.简单介绍下google protobuf: google protobuf 主要用于通讯,是google ...
- Scrapy五大核心组件简介
五大核心组件 scrapy框架主要由五大组件组成,他们分别是调度器(Scheduler),下载器(Downloader),爬虫(Spider),和实体管道(Item Pipeline),Scrapy引 ...
- HTML静态网页--JavaScript-Window.document对象
1.Window.document对象 一.找到元素: docunment.getElementById("id"):根据id找,最多找一个: var a =docunmen ...
- Python--day69--ORM多对多查询
ManyToManyField class RelatedManager "关联管理器"是在一对多或者多对多的关联上下文中使用的管理器. 它存在于下面两种情况: 外键关系的反向查询 ...
- 纯JS前端分页方法(JS分页)
1.JS分页函数:开发过程中,分页功能一般是后台提供接口,前端只要传page(当前页码)和pageSize(每页最大显示条数)及对应的其他查询条件,就可以返回所需分页显示的数据. 但是有时也需要前端本 ...
- 模板——Treap实现名次树
Treap 是一种通过赋予结点随机权值的一种满足堆性质的二叉搜索树,它很好的解决了二叉搜索树顺序插入组成链式的局限性. 名次树是指在treap的每个结点中添加附加域size,表示以它为根的子树的总结点 ...
- 浅谈集合框架二 List、Set常用方法
最近刚学完集合框架,想把自己的一些学习笔记与想法整理一下,所以本篇博客或许会有一些内容写的不严谨或者不正确,还请大神指出.初学者对于本篇博客只建议作为参考,欢迎留言共同学习. 之前有介绍集合框架的体系 ...
- java IO的概述和File方法
IO流用来处理设备之间的数据传输 Java对数据的操作是通过流的方式 Java用于操作流的对象都在IO包中 File类在整个IO包中与文件本身有关的操作类,所有的与文件本身 ...