DeepLearning - Forard & Backward Propogation
In the previous post I go through basic 1-layer Neural Network with sigmoid activation function, including
How to get sigmoid function from a binary classification problem?
NN is still an optimization problem, so what's the target to optimize? - cost function
How does model learn?- gradient descent
Work flow of NN? - Backward/Forward propagation
Now let's get deeper to 2-layers Neural Network, from where you can have as many hidden layers as you want. Also let's try to vectorize everything.
1. The architecture of 2-layers shallow NN
Below is the architecture of 2-layers NN, including input layer, one hidden layer and one output layer. The input layer is not counted.
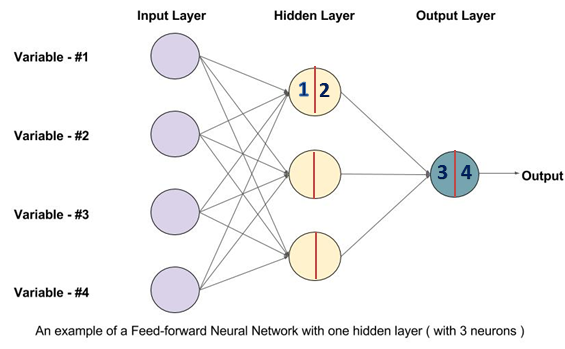
(1) Forward propagation
In each neuron, there are 2 activities going on after take in the input from previous hidden layer:
- a linear transformation of the input
- a non-linear activation function applied after
Then the ouput will pass to the next hidden layer as input.
From input layer to output layer, do above computation layer by layer is forward propagation. It tries to map each input \(x \in R^n\) to $ y$.
For each training sample, the forward propagation is defined as following:
\(x \in R^{n*1}\) denotes the input data. In the picture n = 4.
\((w^{[1]} \in R^{k*n},b^{[1]}\in R^{k*1})\) is the parameter in the first hidden layer. Here k = 3.
\((w^{[2]} \in R^{1*k},b^{[2]}\in R^{1*1})\) is the parameter in the output layer. The output is a binary variable with 1 dimension.
\((z^{[1]} \in R^{k*1},z^{[2]}\in R^{1*1})\) is the intermediate output after linear transformation in the hidden and output layer.
\((a^{[1]} \in R^{k*1},a^{[2]}\in R^{1*1})\) is the output from each layer. To make it more generalize we can use \(a^{[0]} \in R^n\) to denote \(x\)
*Here we use \(g(x)\) as activation function for hidden layer, and sigmoid \(\sigma(x)\) for output layer. we will discuss what are the available activation functions \(g(x)\) out there in the following post. What happens in forward propagation is following:
\([1]\) \(z^{[1]} = {w^{[1]}} a^{[0]} + b^{[1]}\)
\([2]\) \(a^{[1]} = g((z^{[1]} ) )\)
\([3]\) \(z^{[2]} = {w^{[2]}} a^{[1]} + b^{[2]}\)
\([4]\) \(a^{[2]} = \sigma(z^{[2]} )\)
(2) Backward propagation
After forward propagation, for each training sample \(x\) is done ,we will have a prediction \(\hat{y}\). Comparing \(\hat{y}\) with \(y\), we then use the error between prediction and real value to update the parameter via gradient descent.
Backward propagation is passing the gradient descent from output layer back to input layer using chain rule like below. The deduction is in the previous post.
\[ \frac{\partial L(a,y)}{\partial w} =
\frac{\partial L(a,y)}{\partial a} \cdot
\frac{\partial a}{\partial z} \cdot
\frac{\partial z}{\partial w}\]
\([4]\) \(dz^{[2]} = a^{[2]} - y\)
\([3]\) \(dw^{[2]} = dz^{[2]} a^{[1]T}\)
\([3]\) \(db^{[2]} = dz^{[2]}\)
\([2]\) \(dz^{[1]} = da^{[1]} * g^{[1]'}(z[1]) = w^{[2]T} dz^{[2]}* g^{[1]'}(z[1])\)
\([1]\) \(dw^{[1]} = dz^{[1]} a^{[0]T}\)
\([1]\) \(db^{[1]} = dz^{[1]}\)
2. Vectorize and Generalize your NN
Let's derive the vectorize representation of the above forward and backward propagation. The usage of vector is to speed up the computation. We will talk about this again in batch gradient descent.
\(w^{[1]},b^{[1]}, w^{[2]}, b^{[2]}\) stays the same. Generally \(w^{[i]}\) has dimension \((h_{i},h_{i-1})\) and \(b^{[i]}\) has dimension \((h_{i},1)\)
\(Z^{[1]} \in R^{k*m}, Z^{[2]} \in R^{1*m}, A^{[0]} \in R^{n*m}, A^{[1]} \in R^{k*m}, A^{[2]}\in R^{1*m}\) where \(A^{[0]}\)is the input vector, each column is one training sample.
(1) Forward propogation
Follow above logic, vectorize representation is below:
\([1]\) \(Z^{[1]} = {w^{[1]}} A^{[0]} + b^{[1]}\)
\([2]\) \(A^{[1]} = g((Z^{[1]} ) )\)
\([3]\) \(Z^{[2]} = {w^{[2]}} A^{[1]} + b^{[2]}\)
\([4]\) \(A^{[2]} = \sigma(Z^{[2]} )\)
Have you noticed that the dimension above is not a exact matched?
\({w^{[1]}} A^{[0]}\) has dimension \((k,m)\), \(b^{[1]}\) has dimension \((k,1)\).
However Python will take care of this for you with Broadcasting. Basically it will replicate the lower dimension to the higher dimension. Here \(b^{[1]}\) will be replicated m times to become \((k,m)\)
(1) Backward propogation
Same as above, backward propogation will be:
\([4]\) \(dZ^{[2]} = A^{[2]} - Y\)
\([3]\) \(dw^{[2]} =\frac{1}{m} dZ^{[2]} A^{[1]T}\)
\([3]\) \(db^{[2]} = \frac{1}{m} \sum{dZ^{[2]}}\)
\([2]\) \(dZ^{[1]} = dA^{[1]} * g^{[1]'}(z[1]) = w^{[2]T} dZ^{[2]}* g^{[1]'}(z[1])\)
\([1]\) \(dw^{[1]} = \frac{1}{m} dZ^{[1]} A^{[0]T}\)
\([1]\) \(db^{[1]} = \frac{1}{m} \sum{dZ^{[1]} }\)
In the next post, I will talk about some other details in NN, like hyper parameter, activation function.
To be continued.
Reference
- Ian Goodfellow, Yoshua Bengio, Aaron Conrville, "Deep Learning"
- Deeplearning.ai https://www.deeplearning.ai/
DeepLearning - Forard & Backward Propogation的更多相关文章
- Deeplearning - Overview of Convolution Neural Network
Finally pass all the Deeplearning.ai courses in March! I highly recommend it! If you already know th ...
- DeepLearning - Regularization
I have finished the first course in the DeepLearnin.ai series. The assignment is relatively easy, bu ...
- Coursera机器学习+deeplearning.ai+斯坦福CS231n
日志 20170410 Coursera机器学习 2017.11.28 update deeplearning 台大的机器学习课程:台湾大学林轩田和李宏毅机器学习课程 Coursera机器学习 Wee ...
- DeepLearning - Overview of Sequence model
I have had a hard time trying to understand recurrent model. Compared to Ng's deep learning course, ...
- back propogation 的线代描述
参考资料: 算法部分: standfor, ufldl : http://ufldl.stanford.edu/wiki/index.php/UFLDL_Tutorial 一文弄懂BP:https: ...
- DeepLearning Intro - sigmoid and shallow NN
This is a series of Machine Learning summary note. I will combine the deep learning book with the de ...
- 用纯Python实现循环神经网络RNN向前传播过程(吴恩达DeepLearning.ai作业)
Google TensorFlow程序员点赞的文章! 前言 目录: - 向量表示以及它的维度 - rnn cell - rnn 向前传播 重点关注: - 如何把数据向量化的,它们的维度是怎么来的 ...
- 吴恩达DeepLearning.ai的Sequence model作业Dinosaurus Island
目录 1 问题设置 1.1 数据集和预处理 1.2 概览整个模型 2. 创建模型模块 2.1 在优化循环中梯度裁剪 2.2 采样 3. 构建语言模型 3.1 梯度下降 3.2 训练模型 4. 结论 ...
- Sql Server 聚集索引扫描 Scan Direction的两种方式------FORWARD 和 BACKWARD
最近发现一个分页查询存储过程中的的一个SQL语句,当聚集索引列的排序方式不同的时候,效率差别达到数十倍,让我感到非常吃惊 由此引发出来分页查询的情况下对大表做Clustered Scan的时候, 不同 ...
随机推荐
- 10.vue router 带参数跳转
vue router 带参数跳转 发送:this.$router.push({path:'/news',query:{id:row.id}}) 接收:var id=this.$route.query. ...
- IOS 文件名获取简洁方式
//这里有一个模拟器沙盒路径(完整路径) NSString* index=@"/Users/junzoo/Library/Application Support/iPhone Simulat ...
- OC中自定义init方法
---恢复内容开始--- 我们知道,在函数中实例化一个对象,大多数会同时进行初始化,如 Person *p =[ [Person alloc]init]; 此时已经进行了初始化,使用init方法,那么 ...
- [翻译]Hystrix wiki–How it Works
注:本文并非是精确的文档翻译,而是根据自己理解的整理,有些内容可能由于理解偏差翻译有误,有些内容由于是显而易见的,并没有翻译,而是略去了.本文更多是学习过程的产出,请尽量参考原官方文档. 流程图 下图 ...
- 高并发下,HashMap会产生哪些问题?
HashMap在高并发环境下会产生的问题 HashMap其实并不是线程安全的,在高并发的情况下,会产生并发引起的问题: 比如: HashMap死循环,造成CPU100%负载 触发fail-fast 下 ...
- Win7装在其他盘 (非C盘)办法
Win7装在其他盘 (非C盘)办法 1]将GHO还原到其他盘(非C盘),如H盘 2]用进U盘系统,里的工具,恢复启动H盘 3]将H盘的Boot文件夹,及其他根目录的所有文件复制到C盘根目录,重启即可开 ...
- 虚拟机搭建hadoop的步骤
1.首先是安装Vmware Workstation,下载地址:https://www.vmware.com/products/workstation-player/workstation-player ...
- Celery的基本使用
Celery 1.什么是Celery Celery是一个简单.灵活且可靠的,处理大量消息的分布式系统,专注于实时处理的异步任务队列,同时也支持任务调度. 用Python写的执行 定时任务和异步任务的框 ...
- rubymine自动转义双引号
如果你使用rubymine在编写JSON字符串的时候,然后要一个一个\去转义双引号的话,就实在太不应该了,又烦又容易出错.在rubymine可以使用Inject language帮我们自动转义双引号 ...
- 破解使用SMB协议的Windows用户密码:acccheck
一.工作原理 Acccheck是一款针对微软的SMB协议的探测工具(字典破解用户名和密码),本身不具有漏洞利用的能力. SMB协议:SMB(Server Message Block)通信协议主要是作为 ...