DeepLearning Intro - sigmoid and shallow NN
This is a series of Machine Learning summary note. I will combine the deep learning book with the deeplearning open course . Any feedback is welcomed!
First let's go through some basic NN concept using Bernoulli classification problem as an example.
Activation Function
1.Bernoulli Output
1. Definition
When dealing with Binary classification problem, what activavtion function should we use in the output layer?
Basically given \(x \in R^n\), How to get \(P(y=1|x)\) ?
2. Loss function
Let $\hat{y} = P(y=1|x) $, We would expect following output
\[P(y|x) = \begin{cases}
\hat{y} & \quad when & y= 1\\
1-\hat{y} & \quad when & y= 0\\
\end{cases}
\]
Above can be simplified as
\[P(y|x)= \hat{y}^{y}(1-\hat{y})^{1-y}\]
Therefore, the maximum likelihood of m training samples will be
\[\theta_{ML} = argmax\prod^{m}_{i=1}P(y^i|x^i)\]
As ususal we take the log of above function and get following. Actually for gradient descent log has other advantages, which we will discuss later.
\[log(\theta_{ML}) = argmax\sum^{m}_{i=1} ylog(\hat{y})+(1-y)log(1-\hat{y}) \]
And the cost function for optimization is following
\[J(w,b) = \sum ^{m}_{i=1}L(y^i,\hat{y}^i)= -\sum^{m}_{i=1}ylog(\hat{y})+(1-y)log(1-\hat{y})\]
The cost function is the sum of loss from m training samples, which measures the performance of classification algo.
And yes here it is exactly the negative of log likelihood. While Cost function can be different from negative log likelihood, when we apply regularization. But here let's start with simple version.
So here comes our next problem, how can we get 1-dimension $ log(\hat{y})$, given input \(x\), which is n-dimension vector ?
3. Activtion function - Sigmoid
Let \(h\) denotes the output from the previous hidden layer that goes into the final output layer. And a linear transformation is applied to \(h\) before activation function.
Let \(z = w^Th +b\)
The assumption here is
\[log(\hat{y}) = \begin{cases}
z & \quad when & y= 1\\
0 & \quad when & y= 0\\
\end{cases}
\]
Above can be simplified as
\[log(\hat{y}) = yz\quad \to \quad \hat{y} = exp(yz)\]
This is an unnormalized distribution of \(\hat{y}\). Because \(y\) denotes probability, we need to further normalize it to $ [0,1]$.
\[\hat{y} = \frac{exp(yz)} {\sum^1_{y=0}exp(yz)} \\
=\frac{exp(z)}{1+exp(z)}\\
\quad \quad \quad \quad = \frac{1}{1+exp(-z)} = \sigma(z)
\]
Bingo! Here we go - Sigmoid Function: \(\sigma(z) = \frac{1}{1+exp(-z)}\)
\[p(y|x) = \begin{cases}
\sigma(z) & \quad when & y= 1\\
1-\sigma(z) & \quad when & y= 0\\
\end{cases}
\]
Sigmoid function has many pretty cool features like following:
\[ 1- \sigma(x) = \sigma(-x) \\
\frac{d}{dx} \sigma(x) = \sigma(x)(1-\sigma(x)) \\
\quad \quad = \sigma(x)\sigma(-x)
\]
Using the first feature above, we can further simply the bernoulli output into following:
\[p(y|x) = \sigma((2y-1)z)\]
4. gradient descent and back propagation
Now we have target cost fucntion to optimize. How does the NN learn from training data? The answer is -- Back Propagation.
Actually back propagation is not some fancy method that is designed for Neural Network. When training sample is big, we can use back propagation to train linear regerssion too.
Back Propogation is iteratively using the partial derivative of cost function to update the parameter, in order to reach local optimum.
$ \
Looping \quad m \quad samples :\
w= w - \frac{\partial J(w,b)}{\partial w} \
b= b - \frac{\partial J(w,b)}{\partial b}
$
Bascically, for each training sample \((x,y)\), we compare the \(y\) with \(\hat{y}\) from output layer. Get the difference, and compute which part of difference is from which parameter( by partial derivative). And then update the parameter accordingly.
And the derivative of sigmoid function can be calcualted using chaining method:
For each training sample, let \(\hat{y}=a = \sigma(z)\)
\[ \frac{\partial L(a,y)}{\partial w} =
\frac{\partial L(a,y)}{\partial a} \cdot
\frac{\partial a}{\partial z} \cdot
\frac{\partial z}{\partial w}\]
Where
1.$\frac{\partial L(a,y)}{\partial a}
=-\frac{y}{a} + \frac{1-y}{1-a} $
Given loss function is
\(L(a,y) = -(ylog(a) + (1-y)log(1-a))\)
2.\(\frac{\partial a}{\partial z} = \sigma(z)(1-\sigma(z)) = a(1-a)\).
See above for sigmoid features.
3.\(\frac{\partial z}{\partial w} = x\)
Put them together we get :
\[ \frac{\partial L(a,y)}{\partial w} = (a-y)x\]
This is exactly the update we will have from each training sample \((x,y)\) to the parameter \(w\).
5. Entire work flow.
Summarizing everything. A 1-layer binary classification neural network is trained as following:
- Forward propagation: From \(x\), we calculate \(\hat{y}= \sigma(z)\)
- Calculate the cost function \(J(w,b)\)
- Back propagation: update parameter \((w,b)\) using gradient descent.
- keep doing above until the cost function stop improving (improment < certain threshold)
6. what's next?
When NN has more than 1 layer, there will be hidden layers in between. And to get non-linear transformation of x, we also need different types of activation function for hidden layer.
However sigmoid is rarely used as hidden layer activation function for following reasons
- vanishing gradient descent
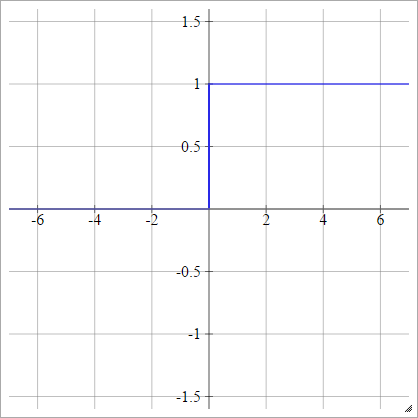
the reason we can't use [left] as activation function is because the gradient is 0 when \(z>1 ,z <0\).
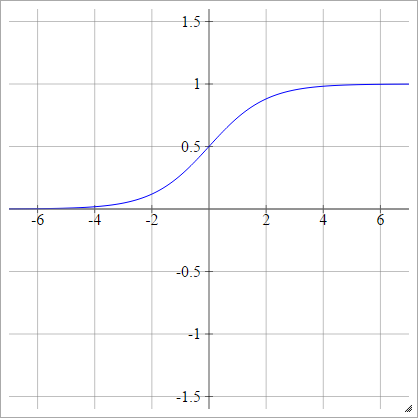
Sigmoid only solves this problem partially. Becuase \(gradient \to 0\), when \(z>1 ,z <0\).
| \(p(y=1\|x)= max\{0,min\{1,z\}\}\) | \(p(y=1\|x)= \sigma(z)\) |
|---|---|
 |
 |
- non-zero centered
To be continued
Reference
- Ian Goodfellow, Yoshua Bengio, Aaron Conrville, "Deep Learning"
- Deeplearning.ai https://www.deeplearning.ai/
DeepLearning Intro - sigmoid and shallow NN的更多相关文章
- Sigmoid function in NN
X = [ones(m, ) X]; temp = X * Theta1'; t = size(temp, ); temp = [ones(t, ) temp]; h = temp * Theta2' ...
- Deeplearning - Overview of Convolution Neural Network
Finally pass all the Deeplearning.ai courses in March! I highly recommend it! If you already know th ...
- DeepLearning - Regularization
I have finished the first course in the DeepLearnin.ai series. The assignment is relatively easy, bu ...
- DeepLearning - Forard & Backward Propogation
In the previous post I go through basic 1-layer Neural Network with sigmoid activation function, inc ...
- Pytorch_第六篇_深度学习 (DeepLearning) 基础 [2]---神经网络常用的损失函数
深度学习 (DeepLearning) 基础 [2]---神经网络常用的损失函数 Introduce 在上一篇"深度学习 (DeepLearning) 基础 [1]---监督学习和无监督学习 ...
- 0802_转载-nn模块中的网络层介绍
0802_转载-nn 模块中的网络层介绍 目录 一.写在前面 二.卷积运算与卷积层 2.1 1d 2d 3d 卷积示意 2.2 nn.Conv2d 2.3 转置卷积 三.池化层 四.线性层 五.激活函 ...
- Neural Networks and Deep Learning
Neural Networks and Deep Learning This is the first course of the deep learning specialization at Co ...
- 关于BP算法在DNN中本质问题的几点随笔 [原创 by 白明] 微信号matthew-bai
随着deep learning的火爆,神经网络(NN)被大家广泛研究使用.但是大部分RD对BP在NN中本质不甚清楚,对于为什这么使用以及国外大牛们是什么原因会想到用dropout/sigmoid ...
- Pytorch实现UNet例子学习
参考:https://github.com/milesial/Pytorch-UNet 实现的是二值汽车图像语义分割,包括 dense CRF 后处理. 使用python3,我的环境是python3. ...
随机推荐
- XML解析方式
两种解析方式概述 dom解析 (1)是W3C组织推荐的处理XML的一种解析方式. (2)将整个XML文档使用类似树的结构保存在内存中,在对其进行操作. (3)可以方便的对XML进行增删改查的操作 (4 ...
- 在CentOS7上安装MySQL5.7-YUM源方式
获取RPM包 # wget https://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm 列出RPM包里都有哪些文件 # ...
- 获取屏幕翻转:var resizeEvt = 'orientationchange' in window ? 'orientationchange' : 'resize'
var resizeEvt = 'orientationchange' in window ? 'orientationchange' : 'resize',这段是为了获取移动端屏幕是否翻转(手机重力 ...
- 自动曝光修复算法 附完整C代码
众所周知, 图像方面的3A算法有: AF自动对焦(Automatic Focus)自动对焦即调节摄像头焦距自动得到清晰的图像的过程 AE自动曝光(Automatic Exposure)自动曝光的是为了 ...
- VirtualBox复制的虚拟机无法获取IP解决办法
自从建立了这个账号后写了一篇,好几年没来了,今天来看看,顺便分享一下. 昨天晚上想玩玩zookeeper集群,在vb里复制了一台主机,可怎么也无法获取IP,经研究,终于还是解决了. 1.复制主机时勾选 ...
- vue服务端渲染缓存应用
vue缓存分为页面缓存.组建缓存.接口缓存,这里我主要说到了页面缓存和组建缓存 页面缓存: 在server.js中设置 const LRU = require('lru-cache') const m ...
- kafka zk常用命令
1 创建topic: kafka-topics.sh --create --zookeeper 3.3.3.3:2181 --replication-factor 1 --partitions 3 ...
- N对数的排列问题 HDU - 2554
N对数的排列问题 HDU - 2554 有N对双胞胎,他们的年龄分别是1,2,3,……,N岁,他们手拉手排成一队到野外去玩,要经过一根独木桥,为了安全起见,要求年龄大的和年龄小的排在一起,好让年龄大的 ...
- c语言程序设计:用strcpy比较数组(银行卡密码程序设计),strcpy(复制数组内容)和getchar()(敲键盘字符,统计不想要的字符的个数)
统计从键盘输入一行字符的个数: 1 //用了getchar() 语句 2 //这里的\n表示回车 #include <stdio.h> #include <stdlib.h> ...
- php7+apache2.4+mysql 环境配置(window环境)
最近,小主从事PHP开发.特将最近如何搭建php7的过程记录在此!希望有需要,可以借鉴!( 电脑必须win7 sp1以上, .netframework4 ) Windows7安装php7,Win7+p ...