storm 入门原理介绍_AboutYUN
转自:http://www.aboutyun.com/thread-7394-1-1.html
了解Storm:http://www.aboutyun.com/thread-9547-1-2.html
问题导读:
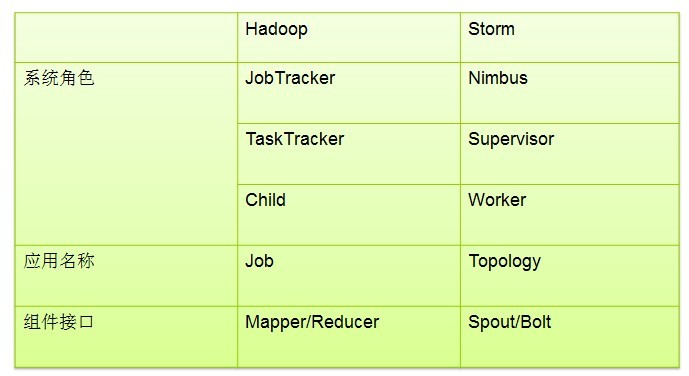
1.hadoop有master与slave,Storm与之对应的节点是什么?
2.Storm控制节点上面运行一个后台程序被称之为什么?
3.Supervisor的作用是什么?
4.Topology与Worker之间的关系是什么?
5.Nimbus和Supervisor之间的所有协调工作有master来完成,还是Zookeeper集群完成?
6.storm稳定的原因是什么?
7.如何运行Topology?
strom jar all-your-code.jar backtype.storm.MyTopology arg1 arg2
8.spout是什么?
9.bolt是什么?
10.Topology由两部分组成?
11.stream grouping有几种?

Storm对于实时计算的的意义相当于Hadoop对于批处理的意义。Hadoop为我们提供了Map和Reduce原语,使我们对数据进行批处理变的非常的简单和优美。同样,Storm也对数据的实时计算提供了简单Spout和Bolt原语。
Storm适用的场景:
1、流数据处理:Storm可以用来用来处理源源不断的消息,并将处理之后的结果保存到持久化介质中。
2、分布式RPC:由于Storm的处理组件都是分布式的,而且处理延迟都极低,所以可以Storm可以做为一个通用的分布式RPC框架来使用。
1、准备工作
2、一个Storm集群的基本组件
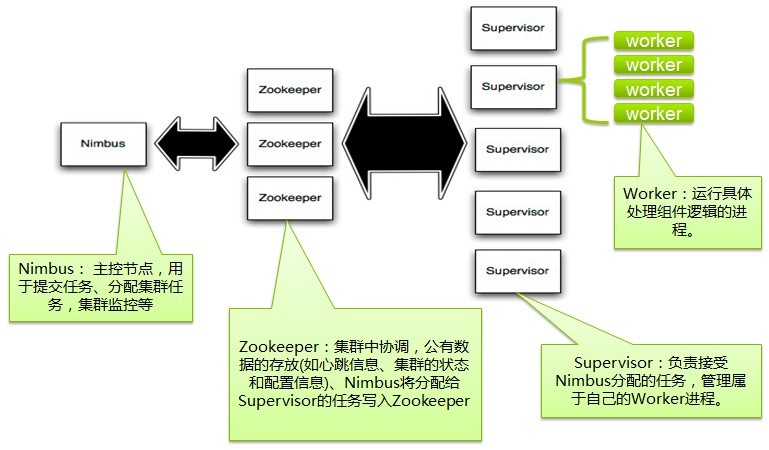
3、Topologies
- strom jar all-your-code.jar backtype.storm.MyTopology arg1 arg2
复制代码
-based语言提交的最简单的方法, 看一下文章: 在生产集群上运行topology去看看怎么启动以及停止topologies。
4、Stream
<ignore_js_op>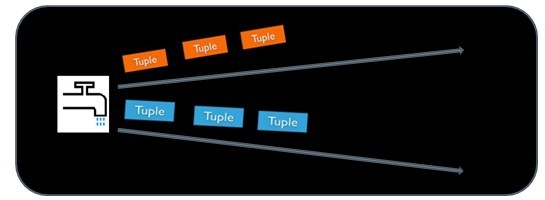
<ignore_js_op>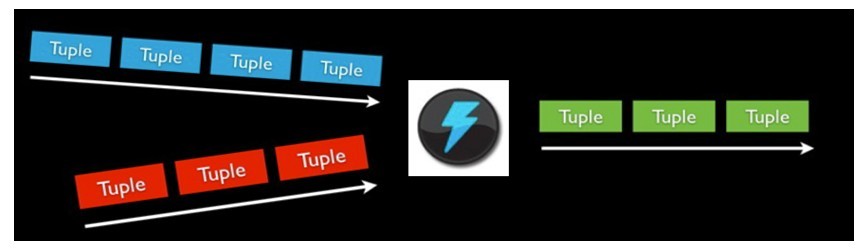
<ignore_js_op>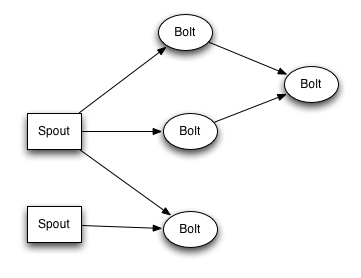
5、数据模型(Data Model)
<ignore_js_op>
<ignore_js_op>
- publicclassDoubleAndTripleBoltimplementsIRichBolt {
- privateOutputCollectorBase _collector;
- @Override
- publicvoidprepare(Map conf, TopologyContext context, OutputCollectorBase collector) {
- _collector = collector;
- }
- @Override
- publicvoidexecute(Tuple input) {
- intval = input.getInteger(0);
- _collector.emit(input,newValues(val*2, val*3));
- _collector.ack(input);
- }
- @Override
- publicvoidcleanup() {
- }
- @Override
- publicvoiddeclareOutputFields(OutputFieldsDeclarer declarer) {
- declarer.declare(newFields("double","triple"));
- }
- }
复制代码
- TopologyBuilder builder =newTopologyBuilder();
- builder.setSpout(1,newTestWordSpout(),10);
- builder.setBolt(2,newExclamationBolt(),3)
- .shuffleGrouping(1);
- builder.setBolt(3,newExclamationBolt(),2)
- .shuffleGrouping(2);
复制代码
- builder.setBolt(3,newExclamationBolt(),5)
- .shuffleGrouping(1)
- .shuffleGrouping(2);
复制代码
让我们深入地看一下这个topology里面的spout和bolt是怎么实现的。Spout负责发射新的tuple到这个topology里面来。TestWordSpout从["nathan", "mike", "jackson", "golda", "bertels"]里面随机选择一个单词发射出来。TestWordSpout里面的nextTuple()方法是这样定义的:
- publicvoidnextTuple() {
- Utils.sleep(100);
- finalString[] words =newString[] {"nathan","mike",
- "jackson","golda","bertels"};
- finalRandom rand =newRandom();
- finalString word = words[rand.nextInt(words.length)];
- _collector.emit(newValues(word));
- }
复制代码
- publicstaticclassExclamationBoltimplementsIRichBolt {
- OutputCollector _collector;
- publicvoidprepare(Map conf, TopologyContext context,
- OutputCollector collector) {
- _collector = collector;
- }
- publicvoidexecute(Tuple tuple) {
- _collector.emit(tuple,newValues(tuple.getString(0) +"!!!"));
- _collector.ack(tuple);
- }
- publicvoidcleanup() {
- }
- publicvoiddeclareOutputFields(OutputFieldsDeclarer declarer) {
- declarer.declare(newFields("word"));
- }
- }
复制代码
让我们看看怎么以local mode运行ExclamationToplogy。
- Config conf =newConfig();
- conf.setDebug(true);
- conf.setNumWorkers(2);
- LocalCluster cluster =newLocalCluster();
- cluster.submitTopology("test", conf, builder.createTopology());
- Utils.sleep(10000);
- cluster.killTopology("test");
- cluster.shutdown();
复制代码
- TOPOLOGY_WORKERS(setNumWorkers) 定义你希望集群分配多少个工作进程给你来执行这个topology. topology里面的每个组件会被需要线程来执行。每个组件到底用多少个线程是通过setBolt和setSpout来指定的。这些线程都运行在工作进程里面. 每一个工作进程包含一些节点的一些工作线程。比如, 如果你指定300个线程,60个进程, 那么每个工作进程里面要执行6个线程, 而这6个线程可能属于不同的组件(Spout, Bolt)。你可以通过调整每个组件的并行度以及这些线程所在的进程数量来调整topology的性能。
- TOPOLOGY_DEBUG(setDebug), 当它被设置成true的话, storm会记录下每个组件所发射的每条消息。这在本地环境调试topology很有用, 但是在线上这么做的话会影响性能的。
Worker processes(进程)
Executors (threads)(线程)
Tasks
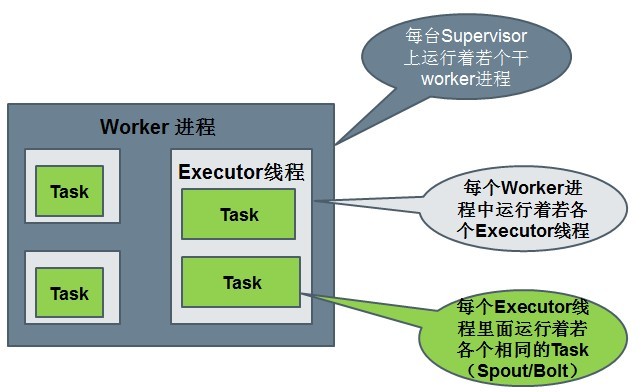
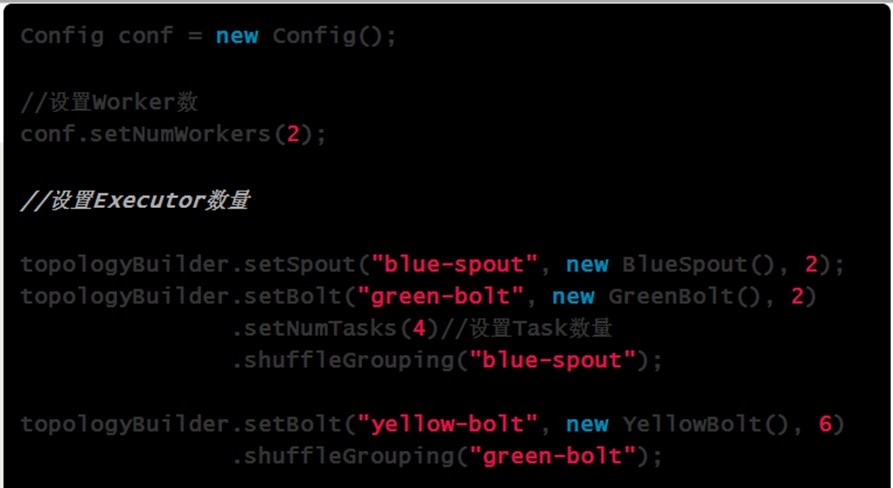
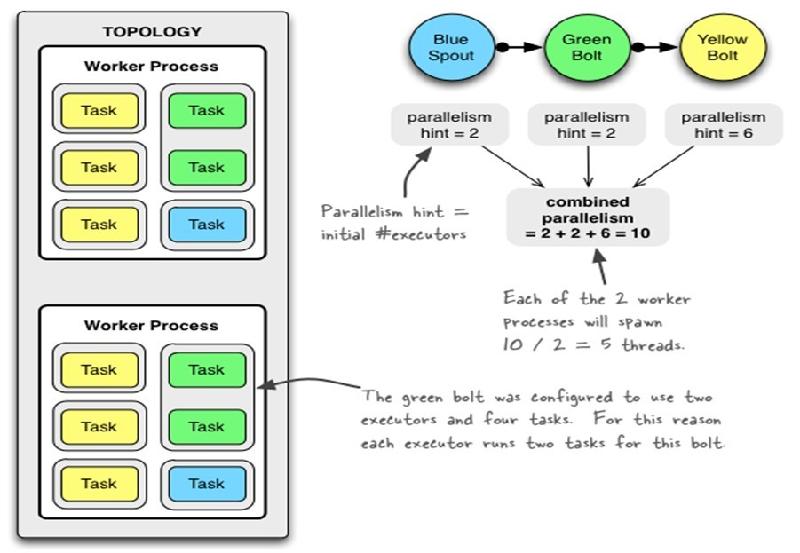

7、流分组策略(Stream grouping)
<ignore_js_op>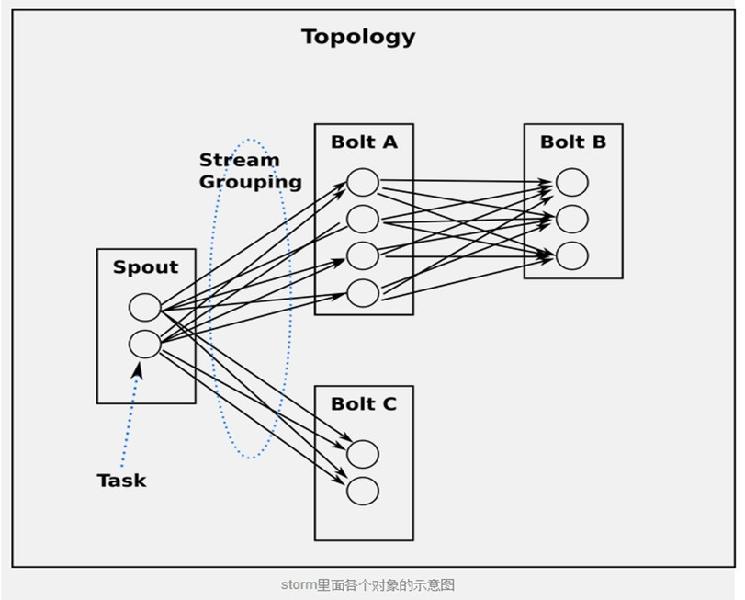
- TopologyBuilder builder =newTopologyBuilder();
- builder.setSpout(1,newRandomSentenceSpout(),5);
- builder.setBolt(2,newSplitSentence(),8)
- .shuffleGrouping(1);
- builder.setBolt(3,newWordCount(),12)
- .fieldsGrouping(2,newFields("word"));
复制代码
- 最简单的grouping是shuffle grouping, 它随机发给任何一个task。上面例子里面RandomSentenceSpout和SplitSentence之间用的就是shuffle grouping, shuffle grouping对各个task的tuple分配的比较均匀。
- 一种更有趣的grouping是fields grouping, SplitSentence和WordCount之间使用的就是fields grouping, 这种grouping机制保证相同field值的tuple会去同一个task, 这对于WordCount来说非常关键,如果同一个单词不去同一个task, 那么统计出来的单词次数就不对了。
l ShuffleGrouping:随机选择一个Task来发送。
l FiledGrouping:根据Tuple中Fields来做一致性hash,相同hash值的Tuple被发送到相同的Task。
l AllGrouping:广播发送,将每一个Tuple发送到所有的Task。
l GlobalGrouping:所有的Tuple会被发送到某个Bolt中的id最小的那个Task。
l NoneGrouping:不关心Tuple发送给哪个Task来处理,等价于ShuffleGrouping。
l DirectGrouping:直接将Tuple发送到指定的Task来处理。
8、使用别的语言来定义Bolt
- publicstaticclassSplitSentenceextendsShellBoltimplementsIRichBolt {
- publicSplitSentence() {
- super("python","splitsentence.py");
- }
- publicvoiddeclareOutputFields(OutputFieldsDeclarer declarer) {
- declarer.declare(newFields("word"));
- }
- }
复制代码
SplitSentence继承自ShellBolt并且声明这个Bolt用python来运行,并且参数是: splitsentence.py。下面是splitsentence.py的定义:
- importstorm
- classSplitSentenceBolt(storm.BasicBolt):
- defprocess(self, tup):
- words=tup.values[0].split(" ")
- forwordinwords:
- storm.emit([word])
- SplitSentenceBolt().run()
复制代码
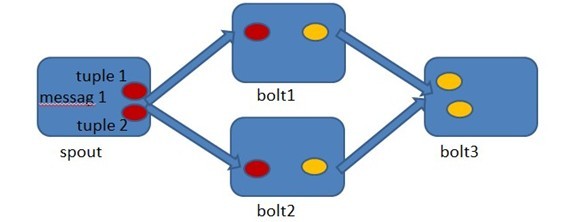
9、可靠的消息处理
storm 入门原理介绍_AboutYUN的更多相关文章
- storm 入门原理介绍
1.hadoop有master与slave,Storm与之对应的节点是什么? 2.Storm控制节点上面运行一个后台程序被称之为什么? 3.Supervisor的作用是什么? 4.Topology与W ...
- (转发)storm 入门原理介绍
1.hadoop有master与slave,Storm与之对应的节点是什么? 2.Storm控制节点上面运行一个后台程序被称之为什么?3.Supervisor的作用是什么?4.Topology与Wor ...
- storm入门原理介绍
转自:http://www.cnblogs.com/wuxiang/p/5629138.html 1.hadoop有master与slave,Storm与之对应的节点是什么?2.Storm控制节点上面 ...
- storm原理介绍
目录 storm原理介绍 一.原理介绍 二.配置 三.并行度 (一)storm拓扑的并行度可以从以下4个维度进行设置: (二)并行度的设置方法 (三)示例 四.分组 五.可靠性 (一)spout (二 ...
- 《Storm入门》中文版
本文翻译自<Getting Started With Storm>译者:吴京润 编辑:郭蕾 方腾飞 本书的译文仅限于学习和研究之用,没有原作者和译者的授权不能用于商业用途. 译者序 ...
- Kylin系列之二:原理介绍
Kylin系列之二:原理介绍 2018年4月15日 15:52 因何而生 Kylin和hive的区别 1. hive主要是离线分析平台,适用于已经有成熟的报表体系,每天只要定时运行即可. 2. Kyl ...
- Apache Storm内部原理分析
转自:http://shiyanjun.cn/archives/1472.html 本文算是个人对Storm应用和学习的一个总结,由于不太懂Clojure语言,所以无法更多地从源码分析,但是参考了官网 ...
- kafka集群原理介绍
目录 kafka集群原理介绍 (一)基础理论 二.配置文件 三.错误处理 kafka集群原理介绍 @(博客文章)[kafka|大数据] 本系统文章共三篇,分别为 1.kafka集群原理介绍了以下几个方 ...
- storm入门demo
一.storm入门demo的介绍 storm的入门helloworld有2种方式,一种是本地的,另一种是远程. 本地实现: 本地写好demo之后,不用搭建storm集群,下载storm的相关jar包即 ...
随机推荐
- KRBTabControl
This article explains how to make a custom Windows Tab Control in C#. Download demo project - 82.4 K ...
- sqlite developer注册码
sqlite developer注册码网上没有找到,只有通过注册表,删除继续使用,删除注册表中 HKEY_CURRENT_USER\SharpPlus\SqliteDev.
- LINQ体验(6)——LINQ to SQL语句之Join和Order By
Join操作 适用场景:在我们表关系中有一对一关系,一对多关系.多对多关系等.对各个表之间的关系,就用这些实现对多个表的操作. 说明:在Join操作中.分别为Join(Join查询), SelectM ...
- .Net Framework 之 框架图
.Net Framework框架图,如下图: 它表明了这么一种编写软件的方式或者说表明了.Net平台下开发软件的思想和规范. .Net Framework框架实际只包含两部分: 1.公共语言运行时( ...
- Python Hashtable的理解
一个对象当其生命周期内的hash值不发生改变,而且可以跟其他对象进行比较时,这个对象就是Hashtable的.两者Hashtable的对象只有具有相同的hash值时才能判断为相同的对象. ...
- WebDriver API——第3部分Action Chains
The ActionChains implementation, class selenium.webdriver.common.action_chains.ActionChains(driver) ...
- HBase - 计数器 - 计数器的介绍以及使用 | 那伊抹微笑
博文作者:那伊抹微笑 csdn 博客地址:http://blog.csdn.net/u012185296 itdog8 地址链接 : http://www.itdog8.com/thread-215- ...
- js实现页面跳转的两种方式
CreateTime--2017年8月24日08:13:52Author:Marydon js实现页面跳转的两种方式 方式一: window.location.href = url 说明:我们常用 ...
- python生成.exe
python生成.exe 1.在Anaconda Prompt终端输入pip install pyinstaller 2.输入python -m pip install pypiwin32 pytho ...
- Android权限说明 system权限 root权限
原文链接:http://blog.csdn.net/rockwupj/article/details/8618655 Android权限说明 Android系统是运行在Linux内核上的,Androi ...