[大数据] hadoop伪分布式安装
注意:节点主机的hostname不要带"_"等字符,否则会报错。
一.安装jdk
rpm -i jdk-7u80-linux-x64.rpm
配置java环境变量:
vi + /etc/profile export JAVA_HOME=/usr/java/jdk1..0_80
PATH=$PATH:$JAVA_HOME/bin
使用jps命令验证:
[root@node001 jdk1..0_80]# jps
Jps
二.设置免密登录
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod ~/.ssh/authorized_keys
让本机能够免密登录本机(因为Namenode和Datanode都在一台机器上)。
[root@pseudo_hadoop .ssh]# ssh pseudo_hadoop
Last login: Fri Nov :: from pseudo_hadoop
使用ssh登录本机别名,能够免密登录。
三. 下载hadoop并解压
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz
tar xf hadoop-2.6..tar.gz -C /opt/
四.添加HADOOP环境变量
vi + /etc/profile export HADOOP_HOME=/opt/hadoop-2.6.
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin . /etc/profile
五.修改配置文件流程
首先,为hadoop指定java目录:
[root@pseudo_hadoop hadoop]# ll /opt/hadoop-2.6./etc/hadoop
total
-rw-r--r-- root root Nov : capacity-scheduler.xml
-rw-r--r-- root root Nov : configuration.xsl
-rw-r--r-- root root Nov : container-executor.cfg
-rw-r--r-- root root Nov : core-site.xml
-rw-r--r-- root root Nov : hadoop-env.cmd
-rw-r--r-- root root Nov : hadoop-env.sh
-rw-r--r-- root root Nov : hadoop-metrics2.properties
-rw-r--r-- root root Nov : hadoop-metrics.properties
-rw-r--r-- root root Nov : hadoop-policy.xml
-rw-r--r-- root root Nov : hdfs-site.xml
-rw-r--r-- root root Nov : httpfs-env.sh
-rw-r--r-- root root Nov : httpfs-log4j.properties
-rw-r--r-- root root Nov : httpfs-signature.secret
-rw-r--r-- root root Nov : httpfs-site.xml
-rw-r--r-- root root Nov : kms-acls.xml
-rw-r--r-- root root Nov : kms-env.sh
-rw-r--r-- root root Nov : kms-log4j.properties
-rw-r--r-- root root Nov : kms-site.xml
-rw-r--r-- root root Nov : log4j.properties
-rw-r--r-- root root Nov : mapred-env.cmd
-rw-r--r-- root root Nov : mapred-env.sh
-rw-r--r-- root root Nov : mapred-queues.xml.template
-rw-r--r-- root root Nov : mapred-site.xml.template
-rw-r--r-- root root Nov : slaves
-rw-r--r-- root root Nov : ssl-client.xml.example
-rw-r--r-- root root Nov : ssl-server.xml.example
-rw-r--r-- root root Nov : yarn-env.cmd
-rw-r--r-- root root Nov : yarn-env.sh
-rw-r--r-- root root Nov : yarn-site.xml
修改三个配置文件的JAVA_HOME变量:
vi hadoop-env.sh
vi mapred-env.sh
vi yarn-env.sh export JAVA_HOME=/usr/java/jdk1..0_80
修改core-site.xml配置文件:
该配置文件主要是配置NameNode。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://pseudo_hadoop:9000</value>
</property>
</configuration>
修改hdfs-site.xml配置文件:
该文件主要配置DataNode。
<configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property>
</configuration>
其中dfs.replication配置的是数据块副本数量,这里由于是伪分布式,所以配置为1。
修改slaves文件:
该文件配置DataNode的机器列表。
vi slaves pseudo_hadoop
除了上述配置,我们还缺少Secondary NameNode的配置,可以从以下官方网页查看相关的配置:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
hdfs-default.xml总所罗列的配置项,就是可以用于hdfs-site.xml配置文件中的配置项。
我们可以看到:

参照这一条信息,在hdfs-site.xml中配置Secondary的IP和端口:
vi hdfs-site.xml <configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>pseudo_hadoop:</value>
</property>
</configuration>
参考core-default.xml的配置:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/core-default.xml

上面默认定义了一个tmp路径,在/tmp目录下的文件存在丢失的风险。因为该路径被hdfs-default.xml中引用:

而dfs.namenode.name.dir下会存放fsimage等重要的恢复数据,所以我们要修改hadoop.tmp.dir的值,将其修改到/var目录下:
vi core-site.xml <configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop/pseudo</value>
</property>
</configuration>
六.配置总结
# 分别修改hadoop-env.sh mapred-env.sh yarn-env.sh的JAVA_HOME
vi hadoop-env.sh
vi mapred-env.sh
vi yarn-env.sh export JAVA_HOME=/usr/java/jdk1..0_80
# core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://pseudo_hadoop:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop/pseudo</value>
</property>
</configuration>
# hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>pseudo_hadoop:</value>
</property>
</configuratiot>
# slaves pseudo_hadoop
七.格式化hdfs
hdfs namenode -format
// :: INFO namenode.FSImage: Allocated new BlockPoolId: BP--192.168.1.188-
// :: INFO common.Storage: Storage directory /var/hadoop/pseudo/dfs/name has been successfully formatted.
// :: INFO namenode.FSImageFormatProtobuf: Saving image file /var/hadoop/pseudo/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
// :: INFO namenode.FSImageFormatProtobuf: Image file /var/hadoop/pseudo/dfs/name/current/fsimage.ckpt_0000000000000000000 of size bytes saved in seconds.
// :: INFO namenode.NNStorageRetentionManager: Going to retain images with txid >=
// :: INFO util.ExitUtil: Exiting with status
// :: INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at pseudo_hadoop/192.168.1.188
************************************************************/
格式化成功后,我们可以看到/var/hadoop/pseudo下产生了一系列文件:
ll /var/hadoop/pseudo/dfs/name/current
total
-rw-r--r-- root root Nov : fsimage_0000000000000000000
-rw-r--r-- root root Nov : fsimage_0000000000000000000.md5
-rw-r--r-- root root Nov : seen_txid
-rw-r--r-- root root Nov : VERSION
其中fsimage_00000000000000000就是生成的fsimage文件
VERSION中的信息:
[root@node001 current]# cat VERSION
#Sat Nov :: CST
namespaceID=
clusterID=CID-df89713b-55fa-457e-952c-4e024893c770
cTime=
storageType=NAME_NODE
blockpoolID=BP--192.168.1.188-
layoutVersion=-
其中最重要的是clusterID,代表集群的唯一标识。提供给所有集群中角色共用。
注意:每次格式化clusterID都会变化,可能会导致与其他角色的ID不一致,所以一个集群理论上只能格式化一次。
八.启动集群
[root@node001 pseudo]# start-dfs.sh Starting namenodes on [node001]
node001: starting namenode, logging to /opt/hadoop-2.6./logs/hadoop-root-namenode-node001.out
node001: starting datanode, logging to /opt/hadoop-2.6./logs/hadoop-root-datanode-node001.out
Starting secondary namenodes [node001]
node001: starting secondarynamenode, logging to /opt/hadoop-2.6./logs/hadoop-root-secondarynamenode-node001.out
使用jps查看java进程:
[root@node001 pseudo]# jps Jps
SecondaryNameNode
NameNode
DataNode
可以看到NameNode、DataNode以及SecondaryNameNode都已成功启动。
错误记录:之前的安装过程中,将hostname设置为了pseudo_hadoop,由于hostname中存在"_"符号,所以导致启动报错。
[root@node001 pseudo]# start-dfs.sh
Starting namenodes on []
node001: starting namenode, logging to /opt/hadoop-2.6.5/logs/hadoop-root-namenode-node001.out
node001: starting datanode, logging to /opt/hadoop-2.6.5/logs/hadoop-root-datanode-node001.out
方括号中没有出现主机名,并且启动完毕后,jps中没有进程号。
九.查看DataNode信息
cd /var/hadoop/pseudo/dfs/data/current
[root@node001 current]# cat VERSION
#Sat Nov :: CST
storageID=DS-05a76de7--418b--635bc7136160
clusterID=CID-df89713b-55fa-457e-952c-4e024893c770
cTime=
datanodeUuid=759fb844-e51d-481a-9d32-eb60863c7f43
storageType=DATA_NODE
layoutVersion=-
我们可以看到clusterID和前述的NameNode中的clusterID一致,说明他们同属一个集群。
同样我们查看namesecondary节点的信息:
cd /var/hadoop/pseudo/dfs/namesecondary/current
[root@node001 current]# cat VERSION
#Sun Nov :: CST
namespaceID=
clusterID=CID-df89713b-55fa-457e-952c-4e024893c770
cTime=
storageType=NAME_NODE
blockpoolID=BP--192.168.1.188-
layoutVersion=-
同样可以发现clusterID与NameNode和Datanode一致。
十.通过浏览器查看集群
浏览器访问端口50070:
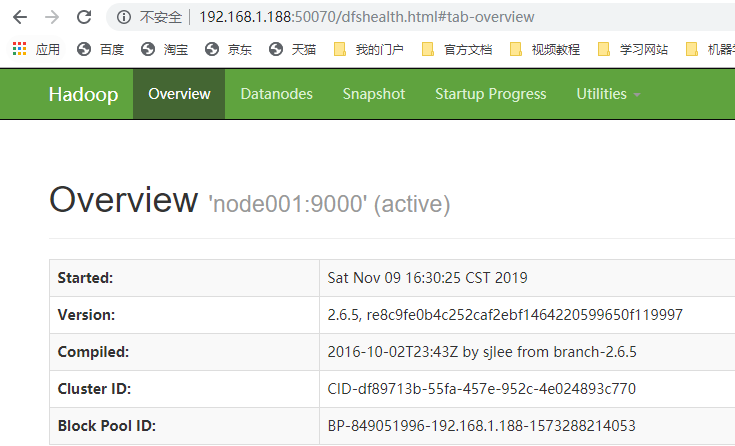
十一.在HDFS中创建目录并上传文件
创建root根目录:
[root@node001 current]# hdfs dfs -mkdir -p /user/root
/user/root就是root用户的根目录,上传文件时不指定目录,则会自动放入此目录。
在浏览器中查看文件系统:

上传一个文件(例如 jdk-7u80-linux-x64.rpm,大小是132MB):
[root@node001 software]# hdfs dfs -put jdk-7u80-linux-x64.rpm /user/root/jdk-7u80.rpm
使用-put上传文件到/user/root下,并将其改名为jdk-7u80.rpm

我们可以在浏览器中查看已经上传的文件。大小是精确的131.69MB,副本数是1(伪分布式),block size默认是120MB(本文件被分成两个block存放),名字为修改后jdk-7u80.rpm。
使用命令行查看:
[root@node001 software]# hdfs dfs -ls /user/root
Found items
-rw-r--r-- root supergroup -- : /user/root/jdk-7u80.rpm
十二.查看HDFS中文件在实际节点上的存储位置
我们在配置Hadoop时配置的数据目录为/var/hadoop/pseudo
载hadoop运行后,在/var/hadoop/pseudo/dfs目录下除了name目录,还会产生data目录和namesecondary目录:
[root@node001 dfs]# ll
total
drwx------ root root Nov : data
drwxr-xr-x root root Nov : name
drwxr-xr-x root root Nov : namesecondary
data目录代表的是DataNode的数据存放位置,所以文件block是存放在该目录下的:
[root@node001 subdir0]# ll /var/hadoop/pseudo/dfs/data/current/BP--192.168.1.188-/current/finalized/subdir0/subdir0
total
-rw-r--r-- root root Nov : blk_1073741825
-rw-r--r-- root root Nov : blk_1073741825_1001.meta
-rw-r--r-- root root Nov : blk_1073741826
-rw-r--r-- root root Nov : blk_1073741826_1002.meta
在这个很深的目录中,我们可以看到jdk文件对应的两个block文件,以及附带的元数据文件。
十三.查看edits文件
在对集群进行操作后,我们查看NameNode所生成的edits文件:
[root@node001 current]# ll /var/hadoop/pseudo/dfs/name/current
total
-rw-r--r-- root root Nov : edits_0000000000000000001-
-rw-r--r-- root root Nov : edits_0000000000000000003-
-rw-r--r-- root root Nov : edits_0000000000000000005-
-rw-r--r-- root root Nov : edits_0000000000000000007-
-rw-r--r-- root root Nov : edits_0000000000000000009-
-rw-r--r-- root root Nov : edits_0000000000000000011-
-rw-r--r-- root root Nov : edits_0000000000000000013-
-rw-r--r-- root root Nov : edits_0000000000000000015-
-rw-r--r-- root root Nov : edits_0000000000000000017-
-rw-r--r-- root root Nov : edits_0000000000000000019-
-rw-r--r-- root root Nov : edits_0000000000000000021-
-rw-r--r-- root root Nov : edits_inprogress_0000000000000000034
-rw-r--r-- root root Nov : fsimage_0000000000000000020
-rw-r--r-- root root Nov : fsimage_0000000000000000020.md5
-rw-r--r-- root root Nov : fsimage_0000000000000000033
-rw-r--r-- root root Nov : fsimage_0000000000000000033.md5
-rw-r--r-- root root Nov : seen_txid
-rw-r--r-- root root Nov : VERSION
我们可以看到生成了很多edits文件,这些文件就是用来记录每一次的操作日志,并在check point将其与fsimage进行合并,提供恢复机制。
[大数据] hadoop伪分布式安装的更多相关文章
- [大数据] hadoop全分布式安装
一.准备工作 在伪分布式的搭建基础上修改配置,搭建全分布式hadoop环境,伪分布式安装参照 hadoop伪分布式安装. 首先准备4台虚拟机,信息如下: 192.168.1.11 namenode1 ...
- 2020/4/26 大数据的zookeeper分布式安装
大数据的zookeeper分布式安装 **** 前面的文章已经提到Hadoop的伪分布式安装.现在就在原有的基础上安装zookeeper. 首先启动Hadoop平台 [root@master ~]# ...
- 搭建大数据hadoop完全分布式环境遇到的坑
搭建大数据hadoop完全分布式环境,遇到很多问题,这里记录一部分,以备以后查看. 1.在安装配置完hadoop以后,需要格式化namenode,输入指令:hadoop namenode -forma ...
- hadoop伪分布式安装之Linux环境准备
Hadoop伪分布式安装之Linux环境准备 一.软件版本 VMare Workstation Pro 14 CentOS 7 32/64位 二.实现Linux服务器联网功能 网络适配器双击选择VMn ...
- apache hadoop 伪分布式安装
1. 准备工作 1.1. 软件准备 1.安装VMWare 2.在VMWare上安装CentOS6.5 3.安装XShell5,用来远程登录系统 4.通过rpm -qa | grep ssh 检查cen ...
- 我搭建大数据Hadoop完全分布式环境遇到的坑---hadoop: command not found
搭建大数据hadoop环境,遇到很多问题,这里记录一部分,以备以后查看. [遇到问题].在安装配置完hadoop以后,需要格式化namenode,输入指令:hadoop namenode -forma ...
- Hadoop 伪分布式安装、运行测试例子
1. 配置linux系统环境 centos 6.4 下载地址:http://pan.baidu.com/s/1geoSWuv[VMWare专用CentOS.rar](安装打包好的VM压缩包) 并配置虚 ...
- 【Hadoop学习之二】Hadoop伪分布式安装
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 伪分布式就 ...
- 基于centos6.5 hadoop 伪分布式安装
步骤1:修改IP 地址和主机名: vi /etc/sysconfig/network-scripts/ifcfg-eth0 如果该文件打开为空白文件代表你计算机上的网卡文件不是这个名称“ifcfg-e ...
随机推荐
- Oracle数据块
最小单位的输入\输出 数据块由操作系统中的一个或多个块组成 数据库是表空间的基本单位 DB_BLOCK_SIZE 查看 Oracle 块的大小语句: SQL> show parameter db ...
- python多线程学习(一)
python多线程.多进程 初探 原先刚学Java的时候,多线程也学了几天,后来一直没用到.然后接触python的多线程的时候,貌似看到一句"python多线程很鸡肋",于是乎直接 ...
- 动态树(LCT、Top Tree、ETT)
LCT Upd: 一个细节:假如我们要修改某个节点的数据,那么要先把它makeroot再修改,改完之后pushup. LCT是一种维护森林的数据结构,本质是用Splay维护实链剖分. 实链剖分大概是这 ...
- 用纯 CSS 创作一个在容器中反弹的小球
效果预览 在线演示 按下右侧的"点击预览"按钮可以在当前页面预览,点击链接可以全屏预览. https://codepen.io/comehope/pen/jKVbyE 可交互视频教 ...
- Codeforces 1190C. Tokitsukaze and Duel
传送门 注意到后手可以模仿先手的操作,那么如果一回合之内没法决定胜负则一定 $\text{once again!}$ 考虑如何判断一回合内能否决定胜负 首先如果最左边和最右的 $0$ 或 $1$ 距离 ...
- C++ 二阶构造模式
1.如何判断构造函数的执行结果? 构造函数没有返回值,所以不能通过返回值来判断是构造函数是否构造成功. 如果给构造函数强行加入一个返回值,用来表示是否构造成功.这样确实能够反映出构造的结果,但是不够优 ...
- oracle 安装后参数调整
关闭11g 新特性 开归档 oracle 11g安装完成需修改:1.关闭审计alter system set audit_trail=none scope=spfile sid='*'; 防止ORA- ...
- js获取7天之前的日期或者7天之后的日期
js获取7天之前的日期或者7天之后的日期(网上摘取的,记录自己使用) function fun_date(num) { var date1 = new Date(); //今天时间 var time1 ...
- java网络编程+通讯协议的理解
参考: http://blog.csdn.net/sunyc1990/article/details/50773014 网络编程对于很多的初学者来说,都是很向往的一种编程技能,但是很多的初学者却因为很 ...
- multipart/form-data请求与文件上传的细节
<!DOCTYPE html><html><head lang="en"> <meta charset="UTF-8" ...