Hadoop实战:reduce端实现Join
项目描述
现在假设有两个数据集:气象站数据库和天气记录数据库,并考虑如何合二为一。一个典型的查询是:输出气象站的历史信息,同时各行记录也包含气象站的元数据信息。
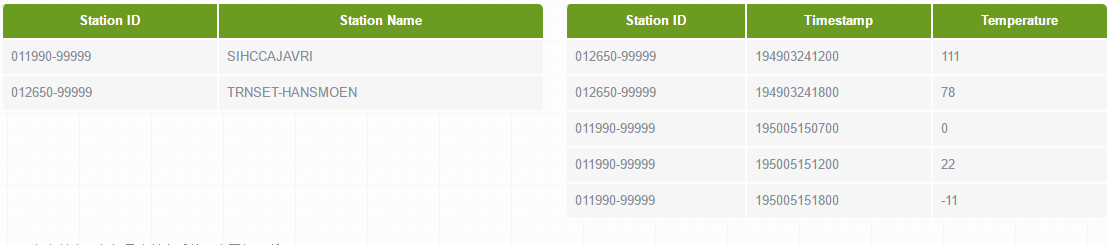
气象站和天气记录合并之后的示意图如下所示。

测试数据
启动Hadoop集群,然后在hdfs中创建join文件夹用于存放测试数据station.txt和records.txt,他们分别代表气象站数据库和天气记录数据库。
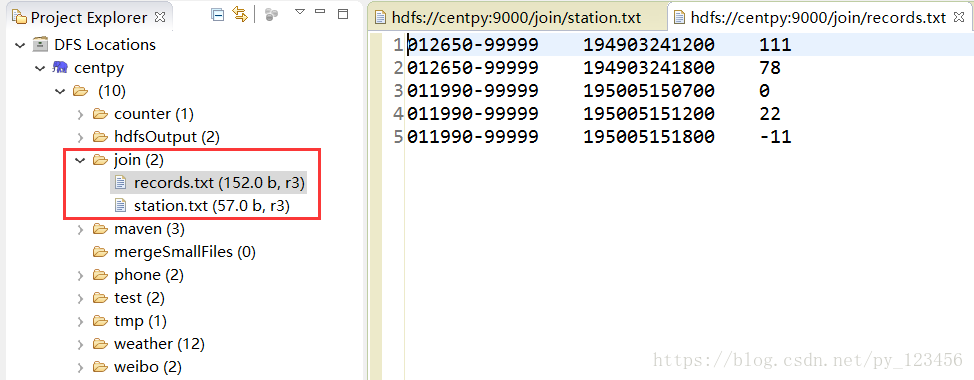
项目代码
JoinStationMapper.java
package com.hadoop.Join; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; /**
* @author Zimo
*
*/
public class JoinStationMapper extends Mapper<LongWritable,Text,TextPair,Text>
{
protected void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException
{
String line = value.toString();
String[] arr = line.split("\\s+");//解析气象站数据
int length = arr.length;
if(length==)
{//满足这种数据格式
//key=气象站id value=气象站名称
System.out.println("station="+arr[]+"");
context.write(new TextPair(arr[],""),new Text(arr[]));
}
}
}
JoinRecordMapper.java
package com.hadoop.Join; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; /**
* @author Zimo
*
*/
public class JoinRecordMapper extends Mapper<LongWritable,Text,TextPair,Text>
{
protected void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException
{
String line = value.toString();
String[] arr = line.split("\\s+",);//解析天气记录数据
int length = arr.length;
if(length==){
//key=气象站id value=天气记录数据
context.write(new TextPair(arr[],""),new Text(arr[]));
}
}
}
TextPair.java
package com.hadoop.Join; import java.io.*;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable; /**
* @author Zimo
*
*/
public class TextPair implements WritableComparable<TextPair>
{
private Text first; //Text 类型的实例变量first
private Text second;//Text 类型的实例变量second public TextPair() //无参构造方法
{
set(new Text(),new Text());
}
public TextPair(String first,String second) // Sting类型参数的构造方法
{
set(new Text(first),new Text(second));
}
public TextPair(Text first,Text second) // Text类型参数的构造方法
{
set(first,second);
}
public void set(Text first,Text second) //set方法
{
this.first=first;
this.second=second;
}
public Text getFirst() //getFirst方法
{
return first;
}
public Text getSecond() //getSecond方法
{
return second;
} //将对象转换为字节流并写入到输出流out中
@Override //------------ 序列化
public void write(DataOutput out) throws IOException //write方法
{
first.write(out);
second.write(out);
} //从输入流in中读取字节流反序列化为对象
@Override //------------反 序列化
public void readFields(DataInput in) throws IOException //readFields方法
{
first.readFields(in);
second.readFields(in);
} @Override
public int hashCode() //在mapreduce中,通过hashCode来选择reduce分区
{
return first.hashCode() *163+second.hashCode();
} @Override
public boolean equals(Object o) //equals方法,这里是两个对象的内容之间比较
{
if (o instanceof TextPair)
{
TextPair tp=(TextPair) o;
return first.equals(tp.first) && second.equals(tp.second);
}
return false;
} @Override
public String toString() //toString方法
{
return first +"\t"+ second;
}
@Override
public int compareTo(TextPair o)
{
// TODO Auto-generated method stub
if(!first.equals(o.first))
{
return first.compareTo(o.first);
}
else if(!second.equals(o.second))
{
return second.compareTo(o.second);
}
return 0;
} }
JoinReducer.java
package com.hadoop.Join; import java.io.IOException; import java.util.Iterator; import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; /**
* @author Zimo
*
*/
public class JoinReducer extends Reducer< TextPair,Text,Text,Text>
{
protected void reduce(TextPair key, Iterable< Text> values,Context context) throws IOException,InterruptedException
{
Iterator< Text> iter = values.iterator();
Text stationName = new Text(iter.next());//气象站名称
while(iter.hasNext()){
Text record = iter.next();//天气记录的每条数据
Text outValue = new Text(stationName.toString()+"\t"+record.toString());
context.write(key.getFirst(),outValue);
}
}
}
JoinRecordWithStationName.java
package com.hadoop.Join; import java.io.InputStream;
import org.apache.hadoop.util.Tool;
import java.io.OutputStream;
import java.util.Set; import javax.lang.model.SourceVersion; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator; import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.lib.input.MultipleInputs;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.ToolRunner; /**
* @author Zimo
*
*/
public class JoinRecordWithStationName extends Configured implements Tool
{
public static class KeyPartitioner extends Partitioner< TextPair,Text>
{ public int getPartition(TextPair key,Text value,int numPartitions)
{
return (key.getFirst().hashCode()&Integer.MAX_VALUE) % numPartitions;
}
} public static class GroupingComparator extends WritableComparator
{
protected GroupingComparator()
{
super(TextPair.class,true);
}
@Override
public int compare(WritableComparable w1,WritableComparable w2)
{
TextPair ip1=(TextPair) w1;
TextPair ip2=(TextPair) w2;
Text l=ip1.getFirst();
Text r=ip2.getFirst();
return l.compareTo(r); }
}
public int run(String[] args) throws Exception
{
Configuration conf = new Configuration();// 读取配置文件 Path mypath=new Path(args[]);
FileSystem hdfs=mypath.getFileSystem(conf);
if (hdfs.isDirectory(mypath))
{
hdfs.delete(mypath,true);
} Job job = Job.getInstance(conf,"join");// 新建一个任务
job.setJarByClass(JoinRecordWithStationName.class);// 主类 Path recordInputPath = new Path(args[]);//天气记录数据源,这里是牵扯到多路径输入和多路径输出的问题。默认是从args[0]开始
Path stationInputPath = new Path(args[]);//气象站数据源
Path outputPath = new Path(args[]);//输出路径 //若只有一个输入和一个输出,则输入是args[0],输出是args[1]。
//若有两个输入和一个输出,则输入是args[0]和args[1],输出是args[2] MultipleInputs.addInputPath(job,recordInputPath,TextInputFormat.class,JoinRecordMapper.class);//读取天气记录Mapper
MultipleInputs.addInputPath(job,stationInputPath,TextInputFormat.class,JoinStationMapper.class);//读取气象站Mapper
FileOutputFormat.setOutputPath(job,outputPath);
job.setReducerClass(JoinReducer.class);// Reducer
job.setNumReduceTasks(); job.setPartitionerClass(KeyPartitioner.class);//自定义分区
job.setGroupingComparatorClass(GroupingComparator.class);//自定义分组 job.setMapOutputKeyClass(TextPair.class);
job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); return job.waitForCompletion(true)?:;
} public static void main(String[] args) throws Exception
{
String[] args0={"hdfs://centpy:9000/join/records.txt"
,"hdfs://centpy:9000/join/station.txt"
,"hdfs://centpy:9000/join/out"
};
int exitCode=ToolRunner.run( new JoinRecordWithStationName(), args0);
System.exit(exitCode);
}
}
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。
Hadoop实战:reduce端实现Join的更多相关文章
- 第2节 mapreduce深入学习:15、reduce端的join算法的实现
reduce端的join算法: 例子: 商品表数据 product: pidp0001,小米5,1000,2000p0002,锤子T1,1000,3000 订单表数据 order: pid ...
- hadoop的压缩解压缩,reduce端join,map端join
hadoop的压缩解压缩 hadoop对于常见的几种压缩算法对于我们的mapreduce都是内置支持,不需要我们关心.经过map之后,数据会产生输出经过shuffle,这个时候的shuffle过程特别 ...
- Hadoop on Mac with IntelliJ IDEA - 10 陆喜恒. Hadoop实战(第2版)6.4.1(Shuffle和排序)Map端 内容整理
下午对着源码看陆喜恒. Hadoop实战(第2版)6.4.1 (Shuffle和排序)Map端,发现与Hadoop 1.2.1的源码有些出入.下面作个简单的记录,方便起见,引用自书本的语句都用斜体表 ...
- 升级版:深入浅出Hadoop实战开发(云存储、MapReduce、HBase实战微博、Hive应用、Storm应用)
Hadoop是一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力高速运算和存储.Hadoop实现了一个分布式文件系 ...
- Hadoop实战之三~ Hello World
本文介绍的是在Ubuntu下安装用三台PC安装完成Hadoop集群并运行好第一个Hello World的过程,软硬件信息如下: Ubuntu:12.04 LTS Master: 1.5G RAM,奔腾 ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
- Hadoop实战实例
Hadoop实战实例 Hadoop实战实例 Hadoop 是Google MapReduce的一个Java实现.MapReduce是一种简化的分布式编程模式,让程序自动分布 ...
- Haoop MapReduce 的Partition和reduce端的二次排序
先贴一张原理图(摘自hadoop权威指南第三版) 实际中看了半天还是不太理解其中的Partition,和reduce端的二次排序,最终根据实验来结果来验证自己的理解 1eg 数据如下 20140101 ...
- Hadoop经典案例(排序&Join&topk&小文件合并)
①自定义按某列排序,二次排序 writablecomparable中的compareto方法 ②topk a利用treemap,缺点:map中的key不允许重复:https://blog.csdn.n ...
随机推荐
- Python:内置函数makestrans()、translate()
转于:https://blog.csdn.net/u014351782/article/details/46740297 博主:夜-feng 一.makestrans() 格式: str.maketr ...
- 问题:c# newtonsoft.json使用;结果:Newtonsoft.Json 用法
Newtonsoft.Json 用法 Newtonsoft.Json 是.NET 下开源的json格式序列号和反序列化的类库.官方网站: http://json.codeplex.com/ 使用方法 ...
- shell入门-grep过滤-1
正则表达式,就是一个字符串.有一定的规律.我们用指定的字符串匹配一个指定的行.指定的字符串就是正则表达式. 正则表达式有这几个工具:grep egrep sed awk 命令:gerep 说明:过滤出 ...
- ViewPageIndicator--仿网易的使用
仿微信(网易的界面) 第一步: AndroidManifest.xml 的配置 <?xml version="1.0" encoding="utf-8"? ...
- glib-2.40编译安装
1 安装glib库所需要的依赖库: libffi-.tar.gz glib-.tar.xz 安装依赖库libffi: tar xf libffi-.tar.gz cd libffi- ./config ...
- 使用Cors后台设置WebAPI接口跨域访问
昨天根据项目组前端开发工程师反映,在浏览器端无法直接使用ajax访问后台接口获取数据,根据他的反映,我查阅了相关跨域的解决方案: 一:使用jsonP,但是jsonP只能使用GET请求,完全不符合我项目 ...
- Prim算法:最小生成树---贪心算法的实现
算法图解: http://baike.baidu.com/link?url=hGNkWIOLRJ_LDWMJRECxCPKUw7pI3s8AH5kj-944RwgeBSa9hGpTaIz5aWYsl_ ...
- vivado中如何调用chipscope或者impact
vivado中并没有集成chipscope和impact,所以需要安装ISE,安装完ISE后进行以下操作: 1) 选择环境变量中的系统变量,新建以下变量 XILINX ...
- 【mysql 统计分组之后统计录数条数】
SELECT count(*) FROM 表名 WHERE 条件 // 这样查出来的是总记录条 SELECT count(*) FROM 表名 WHERE 条件 GROUP BY id //这样统 ...
- IOHelper(自制常用的输入输出的帮助类)
常用的读写文件,和地址转换(win和linux均支持),操作文件再也不是拼接那么的low了 using System; using System.Diagnostics; using System.I ...