Spark&Hive结合起来
1.spark与Hive结合起来
前提:当你spark的版本是1.6.1的时候,你的Hive版本要1.2.1,用别的版本会有问题
我们在做的时候,Hive的版本很简单,我们只需要解压缩,告诉他Hive的源数据在哪里即可
1.首先我们进入/conf/hive-site.xml文件,进行修改jdbc的配置
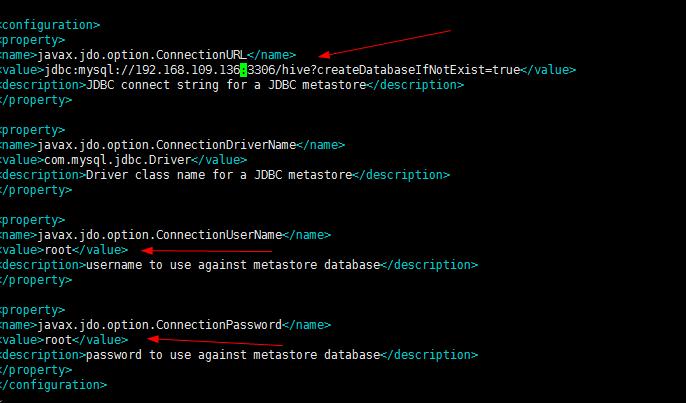
则此时这个IP要改为only的vm1下的那个IP,不能改为自己无线网络的IP
2.进入bin:./bin/hive
执行成功,会自动创建hive这个库
hive中创建person表
切记:在此之前,由于我们的mysql的字符集编码是utf-8,则我们要是用hive,则就要使用latin1
alter databases hive character set latin1
3.建表
create table person(id int,name string,age int) row format delimited fields terminated by ","
4.从hdfs导入数据
load data inpath "hdfs://192.168.109.136:9000/person/person.txt" into table person
此时上面的操作报
Please check that values for params "default.name" and "hive.metastore.warehouse.dir" do
not conf 是由于namenode的不一致
此时修改为weekday01正确
load data inpath "hdfs://weekday01:9000/person/person.txt" into table person
select * from person
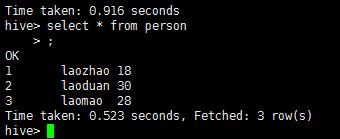
select * from person order by id desc此时这个就会调用集群上的mapReduce
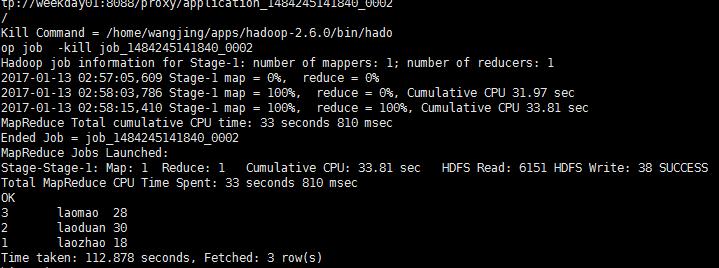
不过这个样子有点慢,我们可以使用spark来进行计算
Spark&Hive结合起来的更多相关文章
- Spark(Hive) SQL中UDF的使用(Python)
相对于使用MapReduce或者Spark Application的方式进行数据分析,使用Hive SQL或Spark SQL能为我们省去不少的代码工作量,而Hive SQL或Spark SQL本身内 ...
- Spark(Hive) SQL数据类型使用详解(Python)
Spark SQL使用时需要有若干“表”的存在,这些“表”可以来自于Hive,也可以来自“临时表”.如果“表”来自于Hive,它的模式(列名.列类型等)在创建时已经确定,一般情况下我们直接通过Spar ...
- [Spark][Hive][Python][SQL]Spark 读取Hive表的小例子
[Spark][Hive][Python][SQL]Spark 读取Hive表的小例子$ cat customers.txt 1 Ali us 2 Bsb ca 3 Carls mx $ hive h ...
- [Spark][Hive]Hive的命令行客户端启动:
[Spark][Hive]Hive的命令行客户端启动: [training@localhost Desktop]$ chkconfig | grep hive hive-metastore 0:off ...
- Spark记录-源码编译spark2.2.0(结合Hive on Spark/Hive on MR2/Spark on Yarn)
#spark2.2.0源码编译 #组件:mvn-3.3.9 jdk-1.8 #wget http://mirror.bit.edu.cn/apache/spark/spark-2.2.0/spark- ...
- Spark(Hive) SQL中UDF的使用(Python)【转】
相对于使用MapReduce或者Spark Application的方式进行数据分析,使用Hive SQL或Spark SQL能为我们省去不少的代码工作量,而Hive SQL或Spark SQL本身内 ...
- spark hive结合杂记(hive-site.xml)
1.下载spark源码,在spark源码目录下面有个make-distribution.sh文件,修改里面的参数,使编译后能支持hive,修改后执行该文件.(要预先安装好maven才能编译). 2.将 ...
- Spark&Hive:如何使用scala开发spark访问hive作业,如何使用yarn resourcemanager。
背景: 接到任务,需要在一个一天数据量在460亿条记录的hive表中,筛选出某些host为特定的值时才解析该条记录的http_content中的经纬度: 解析规则譬如: 需要解析host: api.m ...
- spark hive 结合处理 把多行变成多列
原数据格式 : gid id score a1 1 90 a1 2 80 a1 3 79 a1 ...
- Hadoop+HBase+Spark+Hive环境搭建
杨赟快跑 简书作者 2018-09-24 10:24 打开App 摘要:大数据门槛较高,仅仅环境的搭建可能就要耗费我们大量的精力,本文总结了作者是如何搭建大数据环境的(单机版和集群版),希望能帮助学弟 ...
随机推荐
- 【起航计划 019】2015 起航计划 Android APIDemo的魔鬼步伐 18 App->Device Admin 设备管理器 DeviceAdminReceiver DevicePolicyManager PreferenceActivity的使用
Device Admin示例介绍了类DeviceAdminReceiver,DevicePolicyManager和ActivityManager. 使用DevicePolicyManager这个类, ...
- 【起航计划 017】2015 起航计划 Android APIDemo的魔鬼步伐 16 App->Alarm->Alarm Controller Alarm事件 PendingIntent Schedule AlarmManager
Alarm Controller演示如何在Android应用中使用Alarm事件,其功能和java.util.Timer ,TimerTask类似.但Alarm可以即使当前应用退出后也可以做到Sche ...
- Linq to Sql 左连接 , 取右表可能为 null的 int类型字段
linq to sql , linq to entity 遇到一个问题, 主表, 从表 一对一 关系, 主表有记录, 从表 可能没有记录. 现在要查询 主表+从表 的某几个字段. 从表字段 有的是 ...
- SonarQube代码质量管理平台介绍与搭建
前 言 1.SonarQube的介绍 SonarQube是一个管理代码质量的开放平台. 可以从七个维度检测代码质量(为什么要用SonarQube): (1) 复杂度分布(complexity):代码复 ...
- SharePoint 2010 网络上的开发经验和资源
sharepoint 集成 Exchange 基于OWA方式获取Exchange中未读邮件 http://www.cnblogs.com/jinho/archive/2011/09/17/21798 ...
- PyYAML使用
install yum -y install PyYAML document http://www.showyounger.com/show/101586.html http://pyyaml.org ...
- php:定义时间跳转到指定页面
我们想要定义延迟时间,再跳转到指定页面,只要用header()即可,语法: header("Refresh:延迟时间;url=要跳转的页面"); 例子: 注意注意:我们在heade ...
- Simotion应用案例,使用Simotion web server调试,使用Project Generator创建项目,Simosim模拟运行运行项目
Simotion web server simotion项目设计和调试过程中,web server功能越来越常用.例如Project generator生成的FBAxis, winder, print ...
- robotframework实战三--自定义关键字
在rf的实战1中,我的登录获取验证码就使用了自定义关键字,具体怎么做的,如下 1.新建文件夹 新建一个文件夹,我的MyLibrary,并且存放在site-packages下 2.编写代码 在pytho ...
- mysql [Err] 1055 - Expression #1 of ORDER BY clause is not in GROUP BY clause and contains nonaggregated column 'information_schema.PROFILING.SEQ' which is not functionally dependent on columns in GRO
[Err] 1055 - Expression #1 of ORDER BY clause is not in GROUP BY clause and contains nonaggregated c ...