第四章 朴素贝叶斯法(naive_Bayes)
总结
- 朴素贝叶斯法实质上是概率估计。
- 由于加上了输入变量的各个参量条件独立性的强假设,使得条件分布中的参数大大减少。同时准确率也降低。
- 概率论上比较反直觉的一个问题:三门问题:由于主持人已经限定了他打开的那扇门是山羊,即已经有前提条件了,相对应的概率也应该发生改变,具体公式啥的就不推导了。这个问题与朴素贝叶斯方法有关系,即都用到了先验概率。
- 其中有两种方法来计算其概率分布。
- 极大似然法估计:

- 贝叶斯估计:无法保证其中所有的情况都存在,故再求其条件概率的时候加上一个偏置项,使其所有情况的条件概率在所给的有限的训练集上都不为0。

- 极大似然法估计:
- 下面对极大似然法和贝叶斯估计进行推导。(习题内容)习题内容可能要拖一拖了,枯辽
- 下面是代码实现,代码注释还是挺清楚的
# encoding=utf-8 import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import time def binaryzation(array):
#二值化
# 大于50的为1,小于50的为0,二值化后,参数总量从255降到了2
array[array[:, :] <= 50] = 0
array[array[:, :] > 50] = 1
return array def read_data(path):
raw_data = pd.read_csv(path, header=0)
data = raw_data.values imgs = data[:, 1:]
labels = data[:, 0]
imgs = binaryzation(imgs) # 选2/3的数据作为数据集,1/3的数据作为测试集
tra_x, test_x, tra_y, test_y = train_test_split(imgs, labels, test_size=0.33, random_state=2019526)
return tra_x, test_x, tra_y, test_y def naive_Bayes(x, y, class_num=10, feature_len=784, point_len=2, lamba=1):
"""
:param x: 学习的数据集
:param y: 学习的标签
:param class_num: y的类别的数目
:param feature_len: 每个训练数据的特征向量有多少维
:param point_len: 每个训练集数据的特征向量有多少种取值情况
:return: 先验概率和条件概率
"""
# 这里我们使用贝叶斯估计法来做
prior_probability = np.zeros(class_num)
conditional_probability = np.zeros((class_num, feature_len, point_len))
# 先得到每个对应的数目,计算先验概率
for i in range(10):
prior_probability[i] += len(y[y[:] == i]) # 计算条件概率
for i in range(class_num):
# 取出x中label对应数据为i的点
data_ith = x[y == i]
for j in range(feature_len):
for k in range(point_len):
# 在之前的数据中取出第j列为1,或者为0的点
conditional_probability[i, j, k] += len(data_ith[data_ith[:, j] == k]) + lamba
conditional_probability[i, :, :] /= (prior_probability[i] + point_len * lamba) prior_probability += lamba
prior_probability /= (len(y) + class_num * lamba) return prior_probability, conditional_probability def predict(pp, cp, data, class_num=10,feature_len=784):
"""
预测
:param pp: prior_probability
:param cp: conditional_probability
:param data: 输入数据
:return: 预测结果
"""
pre_label = np.zeros(len(data)+1)
for i in range(len(data)):
max_possibility = 0
max_label = 0
for j in range(class_num):
tmp=pp[j]
for k in range(feature_len):
tmp*=cp[j,k,data[i,k]]
if tmp>max_possibility:
max_possibility=tmp
max_label=j
pre_label[i]=max_label
return pre_label if __name__ == '__main__':
time_1=time.time()
tra_x, test_x, tra_y, test_y = read_data('data/Mnist/mnist_train.csv')
time_2=time.time()
prior_probability, conditional_probability = naive_Bayes(tra_x, tra_y, 10, 784, 2, 1)
time_3=time.time()
pre_label = predict(prior_probability, conditional_probability, test_x, 10,784)
cous=0
for i in range(len(test_y)):
if pre_label[i]==test_y[i]:
cous+=1
print(cous/len(pre_label))
time_4=time.time()
print("time of reading data: ",int(time_2-time_1))
print("time of getting model: ",int(time_3-time_2))
print("time of predictting: ",int(time_4-time_3))
这个是他的准确率及所消耗的时间
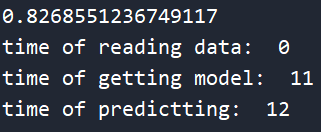
反思:
其实这个准确率低是可以修正的将point_len修改的大点应该就可以提升一点准确率了,因为在我的代码里对每个像素点的划分太过于大了,大于50就为1,小于50就为0,可以分成3段或者更多。
第四章 朴素贝叶斯法(naive_Bayes)的更多相关文章
- 统计学习方法——第四章朴素贝叶斯及c++实现
1.名词解释 贝叶斯定理,自己看书,没啥说的,翻译成人话就是,条件A下的bi出现的概率等于A和bi一起出现的概率除以A出现的概率. 记忆方式就是变后验概率为先验概率,或者说,将条件与结果转换. 先验概 ...
- 朴素贝叶斯法(naive Bayes algorithm)
对于给定的训练数据集,朴素贝叶斯法首先基于iid假设学习输入/输出的联合分布:然后基于此模型,对给定的输入x,利用贝叶斯定理求出后验概率最大的输出y. 一.目标 设输入空间是n维向量的集合,输出空间为 ...
- 朴素贝叶斯法(naive Bayes)
<统计学习方法>(第二版)第4章 4 朴素贝叶斯法 生成模型 4.1 学习与分类 基于特征条件独立假设学习输入输出的联合概率分布 基于联合概率分布,利用贝叶斯定理求出后验概率最大的输出 条 ...
- 【机器学习实战笔记(3-2)】朴素贝叶斯法及应用的python实现
文章目录 1.朴素贝叶斯法的Python实现 1.1 准备数据:从文本中构建词向量 1.2 训练算法:从词向量计算概率 1.3 测试算法:根据现实情况修改分类器 1.4 准备数据:文档词袋模型 2.示 ...
- 统计学习方法与Python实现(三)——朴素贝叶斯法
统计学习方法与Python实现(三)——朴素贝叶斯法 iwehdio的博客园:https://www.cnblogs.com/iwehdio/ 1.定义 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设 ...
- 【机器学习实战】第4章 朴素贝叶斯(Naive Bayes)
第4章 基于概率论的分类方法:朴素贝叶斯 朴素贝叶斯 概述 贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类.本章首先介绍贝叶斯分类算法的基础——贝叶斯定理.最后,我们 ...
- 机器学习Sklearn系列:(四)朴素贝叶斯
3--朴素贝叶斯 原理 朴素贝叶斯本质上就是通过贝叶斯公式来对得到类别概率,但区别于通常的贝叶斯公式,朴素贝叶斯有一个默认条件,就是特征之间条件独立. 条件概率公式: \[P(B|A) = \frac ...
- 手写朴素贝叶斯(naive_bayes)分类算法
朴素贝叶斯假设各属性间相互独立,直接从已有样本中计算各种概率,以贝叶斯方程推导出预测样本的分类. 为了处理预测时样本的(类别,属性值)对未在训练样本出现,从而导致概率为0的情况,使用拉普拉斯修正(假设 ...
- 统计学习方法(李航)朴素贝叶斯python实现
朴素贝叶斯法 首先训练朴素贝叶斯模型,对应算法4.1(1),分别计算先验概率及条件概率,分别存在字典priorP和condP中(初始化函数中定义).其中,计算一个向量各元素频率的操作反复出现,定义为c ...
随机推荐
- java基础语法4--封装,继承,多态
学习路线: 未封装==>封装==>继承==>多态==>抽象类 首先还是那句话,万物皆对象,对象有行为和属性. 一:封装 1.封装的概念: 信息隐蔽和对象的属性及操作结合成一个独 ...
- 109.Convert sorted list to BST
/* * 109.Convert sorted list to BST * 2016.12.24 by Mingyang * 这里的问题是对于一个链表我们是不能常量时间访问它的中间元素的. * 这时候 ...
- 解决java.util.concurrent.ExecutionException: org.apache.catalina.LifecycleException
解决: 工程目录.settings\org.eclipse.wst.common.project.facet.core.xml文件中jst.web的version降低到2.5 <?xml ver ...
- js:简单的拖动效果
效果演示:https://jsfiddle.net/dwqs/b5ywws9f/embedded/result/ html: <div class="wrap"> &l ...
- 微信小程序之 Tabbar(底部选项卡)
1.项目目录 2.在app.json里填写:tab个数范围2-5个 app.json { "pages": [ "pages/index/index", &qu ...
- Mapreduce运行过程分析(基于Hadoop2.4)——(三)
4.4 Reduce类 4.4.1 Reduce介绍 整完了Map,接下来就是Reduce了.YarnChild.main()->ReduceTask.run().ReduceTask.run方 ...
- 搭建Maven私服(使用Nexus)
搭建私服能够做什么? 1.假设公司开发组的开发环境所有内网.这时怎样连接到在互联网上的Maven中央仓库呢? 2.假设公司常常开发一些公共的组件.怎样共享给各个开发组.使用拷贝方式吗?假设这样,公共库 ...
- 如何更有效的消灭watchdogs挖矿病毒?华为云DCS Redis为您支招
漏洞概述 近日,互联网出现watchdogs挖矿病毒,攻击者可以利用Redis未授权访问漏洞入侵服务器,通过内外网扫描感染更多机器.被感染的主机出现 crontab 任务异常.系统文件被删除.CPU ...
- boost的内存管理
smart_ptr raii ( Resource Acquisition Is Initialization ) 智能指针系列的都统称为smart_ptr.包含c++98标准的auto_ptr 智能 ...
- How to: Use Submix Voices
How to: Use Submix Voices:https://msdn.microsoft.com/en-us/library/windows/desktop/ee415794(v=vs.85) ...