java爬虫的selenium基础使用
实用博客 selenium java教程
具体项目运用
项目背景:从西安市人民政府网站上获取到县区新闻,从下图可以看出“区县热点”是需要在页面中进行点击的,这里页面使用的是javascript的函数,无法获取到具体的链接,必须使用selenium进行模拟点击操作。
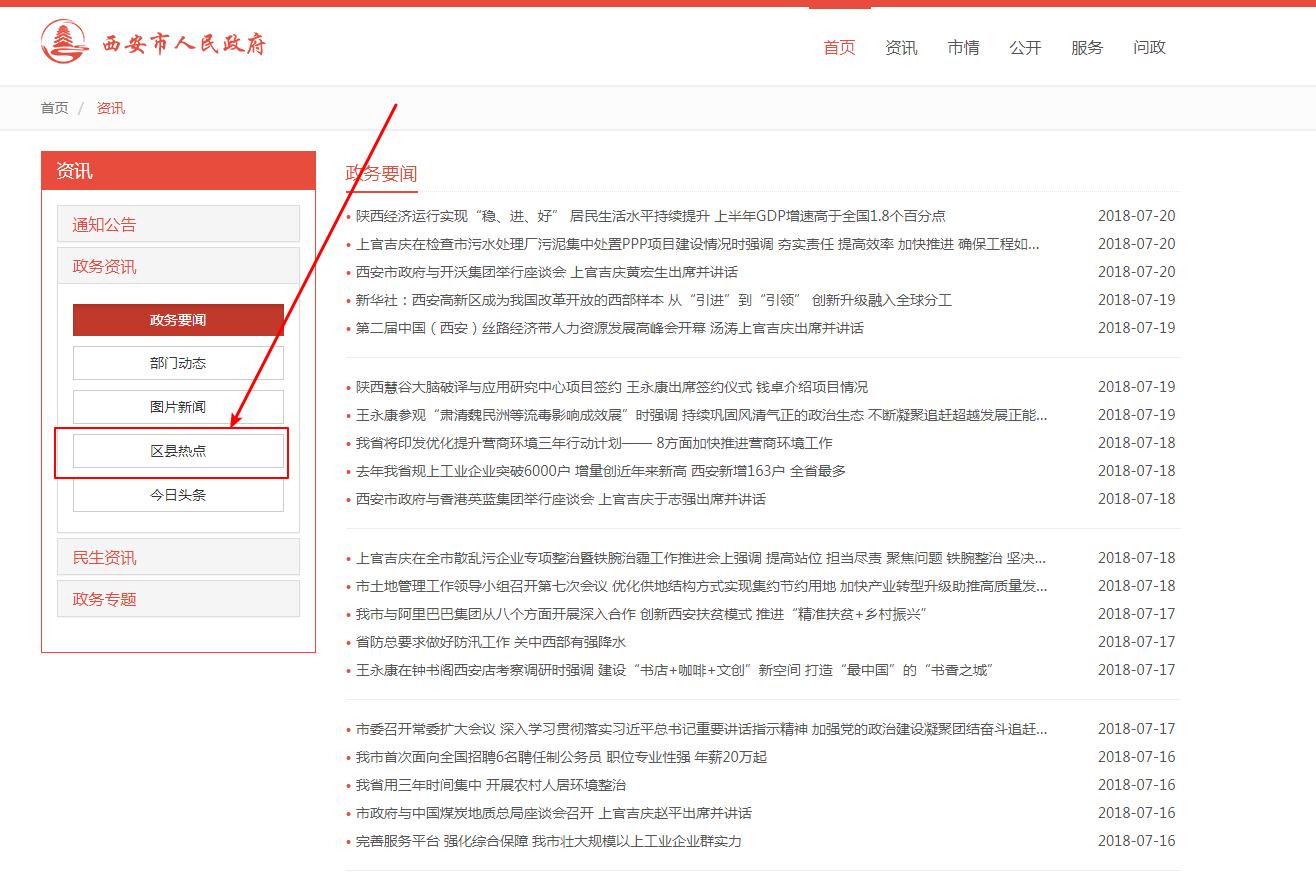
同样,在区县热点中点击下一页也是需要模拟点击的。

代码实现:
首先第一部分是建立好一个WebDriver,用以模拟点击等一系列的操作
private static long waitLoadBaseTime = 2000;
private static int waitLoadRandomTime = 2000;
private static Random random = new Random(System.currentTimeMillis());
public static WebDriver getDriver(String url_web) {
try {
// 等待数据加载的时间
// 为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
// long waitLoadBaseTime = 2000;
// int waitLoadRandomTime = 2000;
// Random random = new Random(System.currentTimeMillis());
// 设置 chrome 的路径,直接放在chrome的安装路径即可
String chrome = "C:\\Program Files (x86)\\Google\\Chrome\\Application\\chromedriver.exe";
System.setProperty("webdriver.chrome.driver", chrome);
ChromeOptions options = new ChromeOptions();
// 通过配置参数禁止data;的出现
options.addArguments(
"--user-data-dir=C:/Users/Administrator/AppData/Local/Google/Chrome/User Data/Default"); // 通过配置参数删除“您使用的是不受支持的命令行标记:--ignore-certificate-errors。稳定性和安全性会有所下降。”提示
options.addArguments("--start-maximized", "allow-running-insecure-content", "--test-type");
options.addArguments("--profile-directory=Default");
// userdata 设置使用chrome的默认参数
options.addArguments("--user-data-dir=C:/Temp/ChromeProfile"); //也可以只用自己配置的chrom 设置地址:如下
// options.addArguments("--user-data-dir=C:/Users/ZHL/AppData/Local/Google/Chrome/User Data"); // 创建一个 Chrome 的浏览器实例
WebDriver driver = new ChromeDriver(options); // 让浏览器访问微博主页
driver.get(url_web); // 等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime)); return driver; } catch (Exception e) {
e.printStackTrace();
return null;
} }
然后就是具体的操作
public static void main(String[] args) throws Exception {
WebDriver dr = getDriver("http://www.xa.gov.cn/ptl/def/def/index_1121_6899_ci_trid_4305611-levNo_1-sortNo_0.html");
Actions action = new Actions(dr);
action.moveToElement(dr.findElement(By.id("div-c2-3"))).click().build().perform(); // 模拟点击
// 点击后要等待网页加载一段时间,然后才是最新的网页源码
Thread.sleep(18000);
System.out.println(dr.findElement(By.className("color-green")).getText());
List<WebElement> newsUrl = dr.findElements(By.cssSelector("li[class='col-md-10 padding-0']"));
System.out.println("newsUrl" + newsUrl.size());
for(WebElement e: newsUrl) {
String title = e.findElement(By.tagName("a")).getText();
String url = e.findElement(By.tagName("a")).getAttribute("href");
System.out.println("title:" + title);
System.out.println("url:" + url);
}
System.out.println(dr.findElement(By.className("color-green")).getText());
System.out.println(dr.findElement(By.id("div-c2-3")).getAttribute("onclick"));
}
java爬虫的selenium基础使用的更多相关文章
- 【Python爬虫】selenium基础用法
selenium 基础用法 阅读目录 初识selenium 基本使用 查找元素 元素互交操作 执行JavaScript 获取元素信息 等待 前进后退 Cookies 选项卡管理 异常处理 初识sele ...
- java爬虫之入门基础
相比于C#,java爬虫,python爬虫更为方便简要,首先呢,python的urllib2包提供了较为完整的访问网页文档的API,再者呢对于摘下来的文章,python的beautifulsoap提供 ...
- 学习用java基于webMagic+selenium+phantomjs实现爬虫Demo爬取淘宝搜索页面
由于业务需要,老大要我研究一下爬虫. 团队的技术栈以java为主,并且我的主语言是Java,研究时间不到一周.基于以上原因固放弃python,选择java为语言来进行开发.等之后有时间再尝试pytho ...
- webmagic的设计机制及原理-如何开发一个Java爬虫
之前就有网友在博客里留言,觉得webmagic的实现比较有意思,想要借此研究一下爬虫.最近终于集中精力,花了三天时间,终于写完了这篇文章.之前垂直爬虫写了一年多,webmagic框架写了一个多月,这方 ...
- JAVA爬虫 WebCollector
JAVA爬虫 WebCollector 爬虫简介: WebCollector是一个无须配置.便于二次开发的JAVA爬虫框架(内核),它提供精简的的API,只需少量代码即可实现一个功能强大的爬虫. 爬虫 ...
- webmagic的设计机制及原理-如何开发一个Java爬虫 转
此文章是webmagic 0.1.0版的设计手册,后续版本的入门及用户手册请看这里:https://github.com/code4craft/webmagic/blob/master/user-ma ...
- Python+Selenium基础入门及实践
Python+Selenium基础入门及实践 32018.08.29 11:21:52字数 3220阅读 23422 一.Selenium+Python环境搭建及配置 1.1 selenium 介绍 ...
- JAVA爬虫实践(实践三:爬虫框架webMagic和csdnBlog爬虫)
WebMagic WebMagic是一个简单灵活的Java爬虫框架.基于WebMagic,你可以快速开发出一个高效.易维护的爬虫. 采用HttpClient可以实现定向的爬虫,也可以自己编写算法逻辑来 ...
- [Python爬虫]使用Selenium操作浏览器订购火车票
这个专题主要说的是Python在爬虫方面的应用,包括爬取和处理部分 [Python爬虫]使用Python爬取动态网页-腾讯动漫(Selenium) [Python爬虫]使用Python爬取静态网页-斗 ...
随机推荐
- DOM基础知识(Node对象、Element对象)
5.Node对象 u 遍历节点 u 父节点 .parentNode - 获取父节点—> 元素节点或文档节点 .parentElement - 获取父元素节点—> 元素节点 u 子节 ...
- 有关windows dpi适配(c#)
/// <summary>当前Dpi</summary> public static Int32 Dpi { get; set; } /// <summary>修正 ...
- Airtest ——poco
1. Pymysql(No module named ‘cryptography’) pip install cryptography pip install paramiko 把 cryptogr ...
- P3387 【模板】缩点 && P3388 【模板】割点(割顶)
Tarjan算法 应用: 有向图的强连通分量 无向图割点和桥 双连通分量 接下来主要谈论前面两者的应用(主要是第三种还没学会) 算法简要介绍 我们需要先理解一下知识:搜索树 有向图的搜索树的4种边,如 ...
- python_for循环
#for循环'''for i in range(0,10,2):age_oldboy = 56for i in range(3): guess_age = int(input("guess ...
- nodejs安装与概述
第一部分:安装与测试 1 官方下载地址 https://nodejs.org/en/ 2 测试是否安装成功? window下打开CMD窗口 输入:node -v => 显示安装的nodej ...
- php $_SERVER['PHP_SELF']安全漏洞
REQUEST_URI 返回的是包括后面数据串的地址,如 index.php?str=1234 PHP_SELF 是 index.php ------------------------------- ...
- ASP.NET-Microsoft.Management.Infrastructure错误
错误如图所示,将MVC发布到IIS上就会出现这个错误,我用到了NPOI这个EXCEL插件,不知道是不是这个造成的,但是实在找不到解决方案,就直接将BIN目录下的这个Microsoft.Manageme ...
- C#-GC基础(待补充)
Finalize方法与Dispose方法区别 1. Finalize只释放非托管资源: 2. Dispose释放托管和非托管资源: // D 是神的天敌3. 重复调用Finalize和Dispose是 ...
- POI 导入excel数据自己主动封装成model对象--代码分析
上完代码后,对代码进行基本的分析: 1.主要使用反射api将数数据注入javabean对象 2.代码中的日志信息级别为debug级别 3.获取ExcelImport对象后须要调用init()方法初始化 ...