[机器学习] ——KNN K-最邻近算法
KNN分类算法,是理论上比较成熟的方法,也是最简单的机器学习算法之一。
该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
一个对于KNN算法解释最清楚的图如下所示:
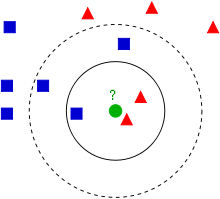
蓝方块和红三角均是已有分类数据,当前的任务是将绿色圆块进行分类判断,判断是属于蓝方块或者红三角。
当然这里的分类还跟K值是有关的:
如果K=3(实线圈),红三角占比2/3,则判断为红三角;
如果K=5(虚线圈),蓝方块占比3/5,则判断为蓝方块。
由此可以看出knn算法实际上根本就不用进行训练,而是直接进行计算的,训练时间为0,计算时间为训练集规模n。
knn算法的基本要素大致有3个:
1、K 值的选择
2、距离的度量
3、分类决策规则
使用方式:(转载)
- K 值会对算法的结果产生重大影响。K值较小意味着只有与输入实例较近的训练实例才会对预测结果起作用,容易发生过拟合;如果 K 值较大,优点是可以减少学习的估计误差,缺点是学习的近似误差增大,这时与输入实例较远的训练实例也会对预测起作用,是预测发生错误。在实际应用中,K 值一般选择一个较小的数值,通常采用交叉验证的方法来选择最有的 K 值。随着训练实例数目趋向于无穷和 K=1 时,误差率不会超过贝叶斯误差率的2倍,如果K也趋向于无穷,则误差率趋向于贝叶斯误差率。
- 算法中的分类决策规则往往是多数表决,即由输入实例的 K 个最临近的训练实例中的多数类决定输入实例的类别
- 距离度量一般采用 Lp 距离,当p=2时,即为欧氏距离,在度量之前,应该将每个属性的值规范化,这样有助于防止具有较大初始值域的属性比具有较小初始值域的属性的权重过大。
knn算法在分类时主要的不足是,当样本不平衡时,如果一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的 K 个邻居中大容量类的样本占多数。
算法伪代码:
搜索k近邻的算法:kNN(A[n],k) #输入:A[n]为N个训练样本在空间中的坐标,k为近邻数
#输出:x所属的类别 取A[1]~A[k]作为x的初始近邻,计算与测试样本x间的欧式距离d(x,A[i]),i=1,2,.....,k;
按d(x,A[i])升序排序;
取最远样本距离D = max{d(x,a[j]) | j=1,2,...,k}; for(i=k+1;i<=n;i++)#继续计算剩下的n-k个数据的欧氏距离
计算a[i]与x间的距离d(x,A[i]);
if(d(x,A[i]))<D
then 用A[i]代替最远样本#将后面计算的数据直接进行插入即可 最后的K个数据是有大小顺序的,再进行K个样本的统计即可
计算前k个样本A[i]),i=1,2,..,k所属类别的概率;
具有最大概率的类别即为样本x的类
python 函数:
#knn-k-最临近算法
#inX为待分类向量,dataSet为训练数据集
#labels为训练集对应分类,k最邻近算法
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]#获得dataSet的行数 diffMat = np.tile(inX, (dataSetSize,1)) - dataSet#对应的差值
sqDiffMat = diffMat**2 #差的平方
sqDistances = sqDiffMat.sum(axis=1) #差的平方的和
distances = sqDistances**0.5 #差的平方的和的平方根
#计算待分类向量与每一个训练数据集的欧氏距离 sortedDistIndicies = distances.argsort() #排序后,统计前面K个数据的分类情况 classCount={}#字典
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]#labels得是字典才可以如此
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)#再次排序 return sortedClassCount[0][0]#第一个就是最多的类别
最后针对于K值的选取,做最后的总结:
[机器学习] ——KNN K-最邻近算法的更多相关文章
- k最邻近算法——使用kNN进行手写识别
上篇文章中提到了使用pillow对手写文字进行预处理,本文介绍如何使用kNN算法对文字进行识别. 基本概念 k最邻近算法(k-Nearest Neighbor, KNN),是机器学习分类算法中最简单的 ...
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- 第四十六篇 入门机器学习——kNN - k近邻算法(k-Nearest Neighbors)
No.1. k-近邻算法的特点 No.2. 准备工作,导入类库,准备测试数据 No.3. 构建训练集 No.4. 简单查看一下训练数据集大概是什么样子,借助散点图 No.5. kNN算法的目的是,假如 ...
- k最邻近算法——加权kNN
加权kNN 上篇文章中提到为每个点的距离增加一个权重,使得距离近的点可以得到更大的权重,在此描述如何加权. 反函数 该方法最简单的形式是返回距离的倒数,比如距离d,权重1/d.有时候,完全一样或非常接 ...
- 2-KNN(K最邻近算法)
KNN基本思想: 1.事先存在已经分类好的样本数据(如分别在A类.B类.C类等) 2.计算待分类的数据(叫做新数据)与所有样本数据的距离 3.选择K个与新数据距离最近的的样本,并统计这K个样本所属的分 ...
- 001 KNN分类 最邻近算法
1.文件5.0,3.5,1.6,0.6,apple5.1,3.8,1.9,0.4,apple4.8,3.0,1.4,0.3,apple5.1,3.8,1.6,0.2,apple4.6,3.2,1.4, ...
- K最邻近算法(下)
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import make_blobs from skle ...
- <机器学习实战>读书笔记--k邻近算法KNN
k邻近算法的伪代码: 对未知类别属性的数据集中的每个点一次执行以下操作: (1)计算已知类别数据集中的点与当前点之间的距离: (2)按照距离递增次序排列 (3)选取与当前点距离最小的k个点 (4)确定 ...
- 机器学习算法及代码实现–K邻近算法
机器学习算法及代码实现–K邻近算法 1.K邻近算法 将标注好类别的训练样本映射到X(选取的特征数)维的坐标系之中,同样将测试样本映射到X维的坐标系之中,选取距离该测试样本欧氏距离(两点间距离公式)最近 ...
随机推荐
- yii2 composer安装
安装Yii2 1.安装composer 在命令行输入 curl-sS https://getcomposer.org/installer | php mv composer.phar /usr/loc ...
- kettle参数、变量详细讲解[转]
kettle 3.2 以前的版本里只有 variable 和 argument,kettle 3.2 中,又引入了 parameter 概念:variable 即environment variabl ...
- [译]reset, checkout和revert
git reset, git checkout, git revert能让你撤销你本地仓储的一些修改, 前两种命令可以作用于commit或者一个文件. Commit级别的操作 注意了git reve ...
- Swift 3.0 【Swift 3.0 相较于 Swift 2.2 的变化】
一.编译器和语法变化 函数或方法参数 调用函数或方法时从第一个参数开始就必须指定参数名 在Swift的历史版本中出现过在调用函数时不需要指定任何函数参数(或者从第二个参数开始指定参数名),在调用方法时 ...
- 292. Nim Game
292. Nim Game You are playing the following Nim Game with your friend: There is a heap of stones on ...
- 第3月第9天 循环引用 block
一.一个对象没有被引用,那么在函数块完成时就会被dealloc,这种情况因为对象销毁了,block块也永远不会执行. MyNetworkOperation *op = [[MyNetworkOpera ...
- javascript数据结构-链表
gihtub博客地址 链表 是一种物理存储单元上非连续.非顺序的存储结构,它既可以表示线性结构,也可以用于表示非线性结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的.链表由一系列结点(链表中每 ...
- UVA2636
理解;类似我们离散的命题 因为只有一个是坏的 超过一个人说你坏 你一定就是坏的 有人说你对 你就对了 分为两种情况 1.说你对的是好的 他的判断是正确的 2.说你对的人 是坏的 他的判断是错误 ...
- PHP程序员进阶学习书籍参考指南
PHP程序员进阶学习书籍参考指南 @heiyeluren lastmodify: 2016/2/18 [初阶](基础知识及入门) 01. <PHP与MySQL程序设计(第4版)> ...
- 使用jquery实现单选框、多选框取消选中状态
function radioReset(){ /*方式一*/ /* var radios = $("input[type='radio']"); for (i=0; i<ra ...