机器学习算法及代码实现–K邻近算法
机器学习算法及代码实现–K邻近算法
1、K邻近算法
将标注好类别的训练样本映射到X(选取的特征数)维的坐标系之中,同样将测试样本映射到X维的坐标系之中,选取距离该测试样本欧氏距离(两点间距离公式)最近的k个训练样本,其中哪个训练样本类别占比最大,我们就认为它是该测试样本所属的类别。

2、算法步骤:
1)为了判断未知实例的类别,以所有已知类别的实例作为参照
2)选择参数K
3)计算未知实例与所有已知实例的距离
4)选择最近K个已知实例
5)根据少数服从多数的投票法则(majority-voting),让未知实例归类为K个最邻近样本中最多数的类别3、距离
Euclidean Distance 定义
其他距离衡量:余弦值(cos), 相关度 (correlation), 曼哈顿距离 (Manhattan distance)
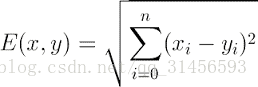
其他距离衡量:余弦值(cos), 相关度 (correlation), 曼哈顿距离 (Manhattan distance)
4、例子
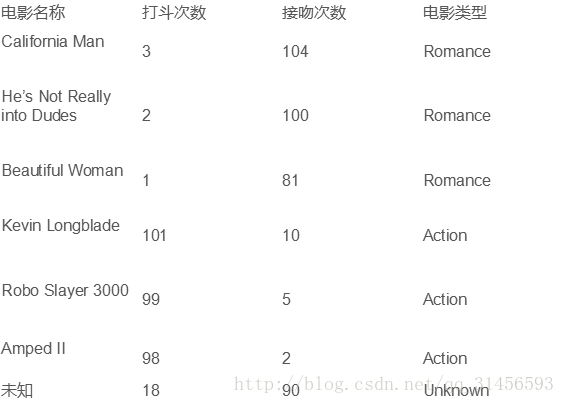
将其映射到2维空间
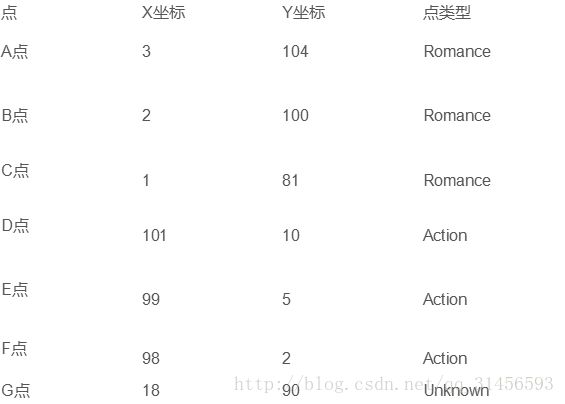
求距G点最近的k点中哪一类点最多,就可以预测G点类型。
5、算法优缺点:
优点
1)简单
2)易于理解
3)容易实现
4)通过对K的选择可具备丢噪音数据的健壮性
缺点
1)需要大量空间储存所有已知实例
2)算法复杂度高(需要比较所有已知实例与要分类的实例)
3) 当其样本分布不平衡时,比如其中一类样本过大(实例数量过多)占主导的时候,新的未知实例容易被归类为这个主导样本,因为这类样本实例的数量过大,但这个新的未知实例实际并木接近目标样本
6、 改进版本
考虑距离,根据距离加上权重
比如: 1/d (d: 距离)代码
# -*- coding: utf-8 -*-
from sklearn import neighbors
from sklearn import datasets
# 调用knn分类器
knn = neighbors.KNeighborsClassifier()
# 导入数据集
iris = datasets.load_iris() print iris # 训练
knn.fit(iris.data, iris.target) # 预测
predictedLabel = knn.predict([[0.1, 0.2, 0.3, 0.4]])
print 'predictedLabel:'
print predictedLabel
机器学习算法及代码实现–K邻近算法的更多相关文章
- 《机器学习实战》学习笔记一K邻近算法
一. K邻近算法思想:存在一个样本数据集合,称为训练样本集,并且每个数据都存在标签,即我们知道样本集中每一数据(这里的数据是一组数据,可以是n维向量)与所属分类的对应关系.输入没有标签的新数据后,将 ...
- <机器学习实战>读书笔记--k邻近算法KNN
k邻近算法的伪代码: 对未知类别属性的数据集中的每个点一次执行以下操作: (1)计算已知类别数据集中的点与当前点之间的距离: (2)按照距离递增次序排列 (3)选取与当前点距离最小的k个点 (4)确定 ...
- [机器学习实战] k邻近算法
1. k邻近算法原理: 存在一个样本数据集,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系.输入没有标签的新数据后,将新数据的每个特征与样本集中数据对 ...
- Python实现kNN(k邻近算法)
Python实现kNN(k邻近算法) 运行环境 Pyhton3 numpy科学计算模块 计算过程 st=>start: 开始 op1=>operation: 读入数据 op2=>op ...
- 监督学习——K邻近算法及数字识别实践
1. KNN 算法 K-近邻(k-Nearest Neighbor,KNN)是分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似( ...
- k邻近算法(KNN)实例
一 k近邻算法原理 k近邻算法是一种基本分类和回归方法. 原理:K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实 ...
- kaggle赛题Digit Recognizer:利用TensorFlow搭建神经网络(附上K邻近算法模型预测)
一.前言 kaggle上有传统的手写数字识别mnist的赛题,通过分类算法,将图片数据进行识别.mnist数据集里面,包含了42000张手写数字0到9的图片,每张图片为28*28=784的像素,所以整 ...
- 数据挖掘算法(一)--K近邻算法 (KNN)
数据挖掘算法学习笔记汇总 数据挖掘算法(一)–K近邻算法 (KNN) 数据挖掘算法(二)–决策树 数据挖掘算法(三)–logistic回归 算法简介 KNN算法的训练样本是多维特征空间向量,其中每个训 ...
- 2 kNN-K-Nearest Neighbors algorithm k邻近算法(一)
给定训练数据样本和标签,对于某测试的一个样本数据,选择距离其最近的k个训练样本,这k个训练样本中所属类别最多的类即为该测试样本的预测标签.简称kNN.通常k是不大于20的整数,这里的距离一般是欧式距离 ...
随机推荐
- Git基本操作和使用
基本命令: git config git init git clone git remote git fetch git commit git rebase git push 本地基本操作: git ...
- MySQL系列(四)
本章内容: 主从复制 简介原理 Mysql主从同步脚本部署 读写分离 如果主宕机了,怎么办? 双主的情况 MySQL 备份及恢复方案 备份单个及多个数据库 mysqldump 的常用参数 如何增量恢复 ...
- Manjaro Linux 入门使用教程
Manjaro 初体验 Manjaro 是一款基于 Arch LInux 的自由开源发行版,它吸收了 Arch Linux 优秀丰富的软件管理,同时提供了稳定流畅的操作体验.优雅简单是它的追求,稳定实 ...
- 基于docker-compose部署LNMP
一.配置环境 [root@docker ~]# systemctl stop firewalld[root@docker ~]# iptables -F[root@docker ~]# setenfo ...
- 【Linux常见命令】find命令
find - search for files in a directory hierarchy find命令用来在指定目录下查找文件. 任何位于参数之前的字符串都将被视为欲查找的目录名. 如果使用该 ...
- 【STM32 .Net MF开发板学习-05】PC通过Modbus协议远程操控开发板
从2002年就开始接触Modbus协议,以后陆续在PLC.DOS.Windows..Net Micro Framework等系统中使用了该协议,在我以前写的一篇博文中详细记载了这一段经历,有兴趣的朋友 ...
- 前端程序员难翻身,没有好的学习方法,你永远无法成功,vue.js专题
学习vue正确思路,是先学vue-cli,再学vue.js单文件引用的用法,这样会在极短时间内撤底撑握vue, 如果先学vue.js单文件用法,再去学vue-cli4,可以说是重新学vue,,,,难处 ...
- codeforce 270B Multithreading
B. Multithreading Emuskald is addicted to Codeforces, and keeps refreshing the main page not to miss ...
- python-unittest环境下单独运行一个用例的方法
在unittest单元测试的框架下,想要调出如图所示的绿三角 需要有两个步骤: 1.确定在工具栏中时在unittest模式下运行的,如果为普通模式的话可以通过下三角下拉修改运行环境: 2.在代码中im ...
- andorid jar/库源码解析之错误提示
目录:andorid jar/库源码解析 错误: 错误1: Error: Static interface methods are only supported starting with Andro ...