理解SQL SERVER中的分区表(转)
简介
分区表是在SQL SERVER2005之后的版本引入的特性。这个特性允许把逻辑上的一个表在物理上分为很多部分。而对于SQL SERVER2005之前版本,所谓的分区表仅仅是分布式视图,也就是多个表做union操作.
分区表在逻辑上是一个表,而物理上是多个表.这意味着从用户的角度来看,分区表和普通表是一样的。这个概念可以简单如下图所示:
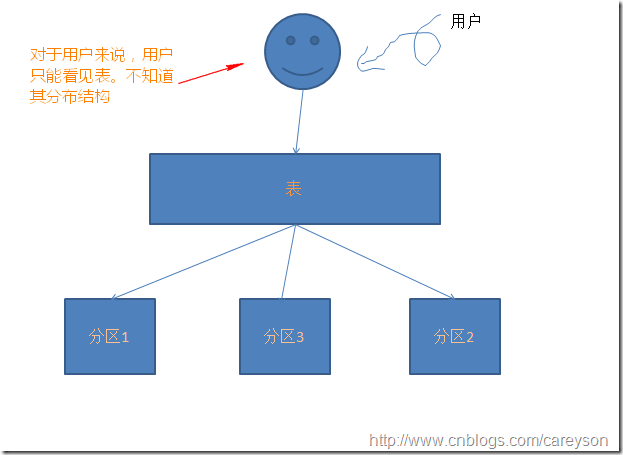
而对于SQL SERVER2005之前的版本,是没有分区这个概念的,所谓的分区仅仅是分布式视图:
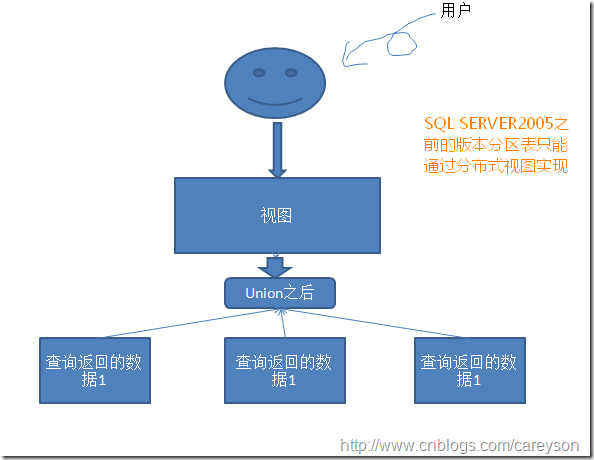
本篇文章所讲述的分区表指的是SQL SERVER2005之后引入的分区表特性.
为什么要对表进行分区
在回答标题的问题之前,需要说明的是,表分区这个特性只有在企业版或者开发版中才有,还有理解表分区的概念还需要理解SQL SERVER中文件和文件组的概念.
对表进行分区在多种场景下都需要被用到.通常来说,使用表分区最主要是用于:
- 存档,比如将销售记录中1年前的数据分到一个专门存档的服务器中
- 便于管理,比如把一个大表分成若干个小表,则备份和恢复的时候不再需要备份整个表,可以单独备份分区
- 提高可用性,当一个分区跪了以后,只有一个分区不可用,其它分区不受影响
- 提高性能,这个往往是大多数人分区的目的,把一个表分布到不同的硬盘或其他存储介质中,会大大提升查询的速度.
分区表的步骤
分区表的定义大体上分为三个步骤:
- 定义分区函数
- 定义分区构架
- 定义分区表
分区函数,分区构架和分区表的关系如下:
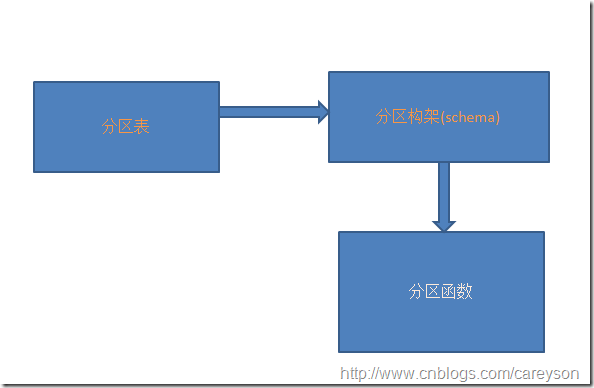
分区表依赖分区构架,而分区构架又依赖分区函数.值得注意的是,分区函数并不属于具体的分区构架和分区表,他们之间的关系仅仅是使用关系.
下面我们通过一个例子来看如何定义一个分区表:
假设我们需要定义的分区表结构如下:
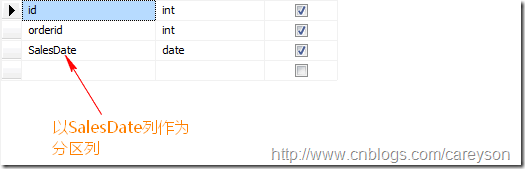
第一列为自增列,orderid为订单id列,SalesDate为订单日期列,也就是我们需要分区的依据.
下面我们按照上面所说的三个步骤来实现分区表.
定义分区函数
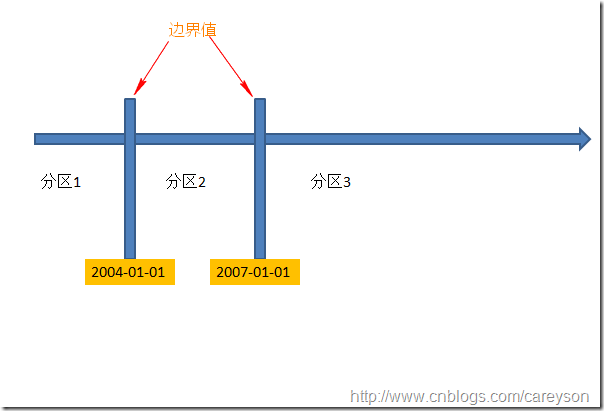
分区函数是用于判定数据行该属于哪个分区,通过分区函数中设置边界值来使得根据行中特定列的值来确定其分区,上面例子中,我们可以通过SalesDate 的值来判定其不同的分区.假设我们想定义两个边界值(boundaryValue)进行分区,则会生成三个分区,这里我设置边界值分别为 2004-01-01和2007-01-01,则前面例子中的表会根据这两个边界值分成三个区:
在MSDN中,定义分区函数的原型如下:
CREATE PARTITION FUNCTION partition_function_name ( input_parameter_type )
AS RANGE [ LEFT | RIGHT ]
FOR VALUES ( [ boundary_value [ ,...n ] ] )
[ ; ]
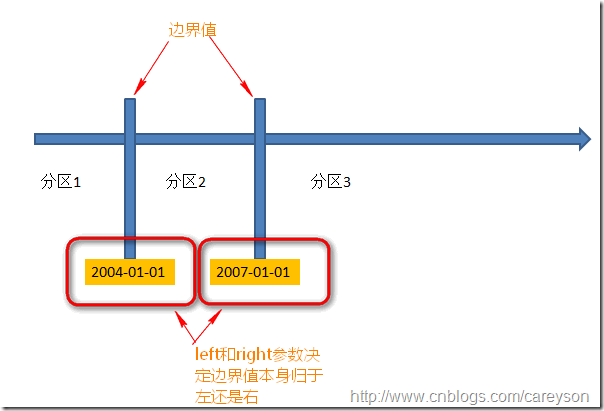
通过定义分区函数的原型,我们看出其中并没有具体涉及具体的表.因为分区函数并不和具体的表相绑定.上面原型中还可以看到Range left和right.这个参数是决定临界值本身应该归于“left”还是“right”:
下面我们根据上面的参数定义分区函数:
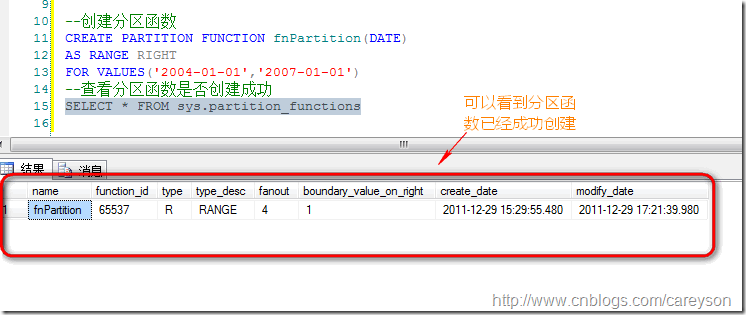
通过系统视图,可以看见这个分区函数已经创建成功
定义分区构架
定义完分区函数仅仅是知道了如何将列的值区分到了不同的分区。而每个分区的存储方式,则需要分区构架来定义.使用分区构架需要你对文件和文件组有点了解.
我们先来看MSDN的分区构架的原型:
CREATE PARTITION SCHEME partition_scheme_name
AS PARTITION partition_function_name
[ ALL ] TO ( { file_group_name | [ PRIMARY ] } [ ,...n ] )
[ ; ]
从原型来看,分区构架仅仅是依赖分区函数.分区构架中负责分配每个区属于哪个文件组,而分区函数是决定如何在逻辑上分区:
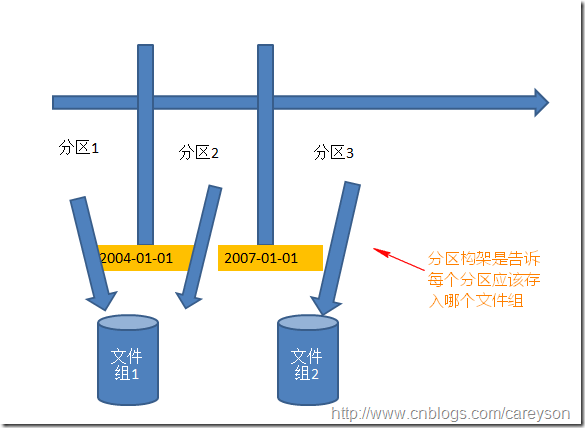
基于之前创建的分区函数,创建分区构架:
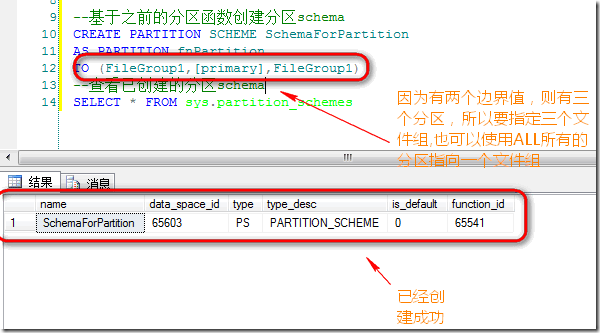
定义分区表
接下来就该创建分区表了.表在创建的时候就已经决定是否是分区表了。虽然在很多情况下都是你在发现已经表已经足够大的时候才想到要把表分区,但是分区表只能够在创建的时候指定为分区表。
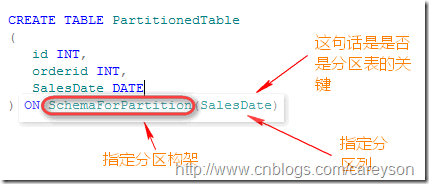
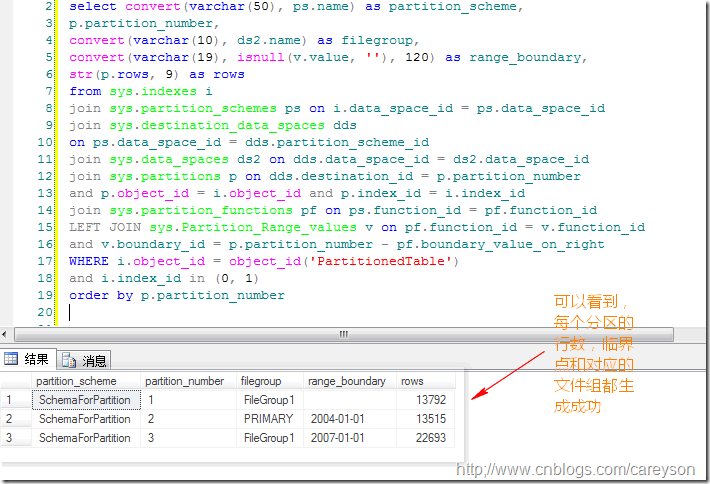
为刚建立的分区表PartitionedTable加入5万条测试数据,其中SalesDate随机生成,从2001年到2010年随机分布.加入数据后,我们通过如下语句来看结果:
select convert(varchar(50), ps.name) as partition_scheme,
p.partition_number,
convert(varchar(10), ds2.name) as filegroup,
convert(varchar(19), isnull(v.value, ''), 120) as range_boundary,
str(p.rows, 9) as rows
from sys.indexes i
join sys.partition_schemes ps on i.data_space_id = ps.data_space_id
join sys.destination_data_spaces dds
on ps.data_space_id = dds.partition_scheme_id
join sys.data_spaces ds2 on dds.data_space_id = ds2.data_space_id
join sys.partitions p on dds.destination_id = p.partition_number
and p.object_id = i.object_id and p.index_id = i.index_id
join sys.partition_functions pf on ps.function_id = pf.function_id
LEFT JOIN sys.Partition_Range_values v on pf.function_id = v.function_id
and v.boundary_id = p.partition_number - pf.boundary_value_on_right
WHERE i.object_id = object_id('PartitionedTable')
and i.index_id in (0, 1)
order by p.partition_number
可以看到我们分区的数据分布:
分区表的分割
分区表的分割。相当于新建一个分区,将原有的分区需要分割的内容插入新的分区,然后删除老的分区的内容,概念如下图:
假设我新加入一个分割点:2009-01-01,则概念如下:
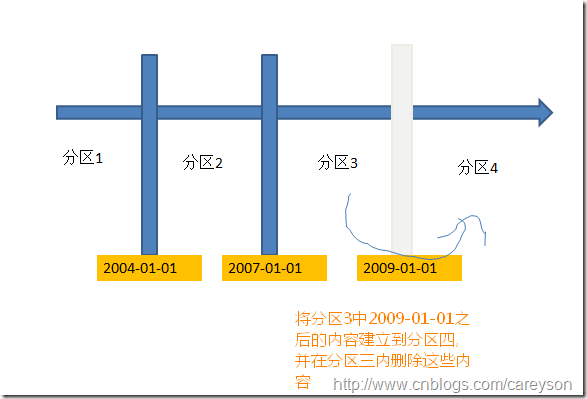
通过上图我们可以看出,如果分割时,被分割的分区3内有内容需要分割到分区4,则这些数据需要被复制到分区4,并删除分区3上对应数据。
这种操作非常非常消耗IO,并且在分割的过程中锁定分区三内的内容,造成分区三的内容不可用。不仅仅如此,这个操作生成的日志内容会是被转移数据的4倍!
所以我们如果不想因为这种操作给客户带来麻烦而被老板爆菊的话…最好还是把分割点建立在未来(也就是预先建立分割点),比如2012-01-01。则分区3内的内容不受任何影响。在以后2012的数据加入时,自动插入到分区4.
分割现有的分区需要两个步骤:
1.首先告诉SQL SERVER新建立的分区放到哪个文件组
2.建立新的分割点
可以通过如下语句来完成:
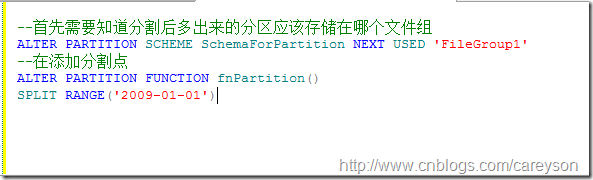
如果我们的分割构架在定义的时候已经指定了NEXT USED,则直接添加分割点即可。
通过文中前面查看分区的长语句..再来看:
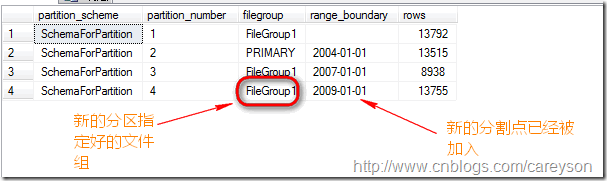
新的分区已经加入!
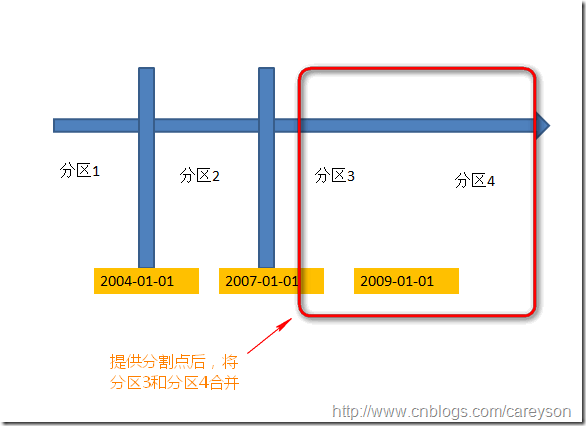
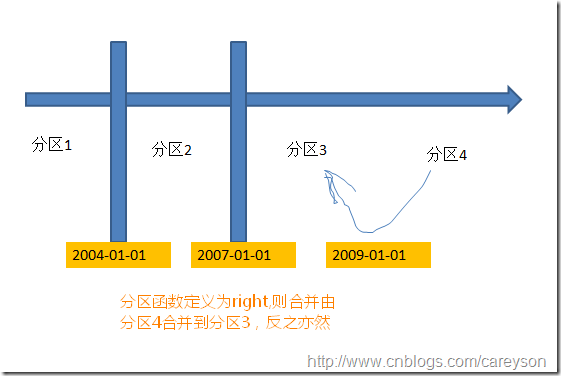
分区的合并
分区的合并可以看作分区分割的逆操作。分区的合并需要提供分割点,这个分割点必须在现有的分割表中已经存在,否则进行合并就会报错
假设我们需要根据2009-01-01来合并分区,概念如下:
只需要使用merge参数:
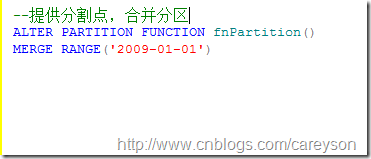
再来看分区信息:
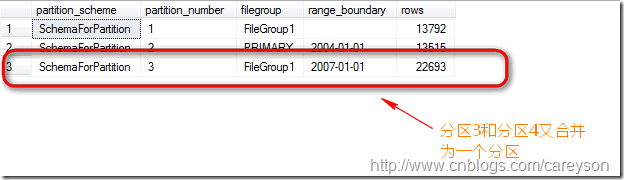
这里值得注意的是,假设分区3和分区4不再一个文件组,则合并后应该存在哪个文件组呢?换句话说,是由分区3合并到分区4还是由分区4合并到分区3?这个 需要看我们的分区函数定义的是left还是right.如果定义的是left.则由左边的分区3合并到右边的分区4.反之,则由分区4合并到分区3:
总结
本文从讲解了SQL SERVER中分区表的使用方式。分区表是一个非常强大的功能。使用分区表相对传统的分区视图来说,对于减少DBA的管理工作来说,会更胜一筹!
sqlserver表分区
原理就类似于把一个表的资 料放在不同的分区里面,当查询时,如果都在同一个单独的分区内的话,就不用进行全表扫描,因此在这些情况下可以提高查询的效率,但如果所有分区都要查询所 有资料的话,分区并不会提高效率.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
--创建分区表过程一共分为三步:创建分区函数、创建分区方案、创建分区表USE [CardID]GOBEGIN TRANSACTION----创建分区函数CREATE PARTITION FUNCTION [SlotecardFunction](datetime) AS RANGE left FOR VALUES (N'2014-03-26T00:00:00', N'2014-04-26T00:00:00', N'2014-05-26T00:00:00', N'2014-06-26T00:00:00', N'2014-07-26T00:00:00', N'2014-08-26T00:00:00', N'2014-09-26T00:00:00')--查看分区函数是否创建成功 --select * from sys.partition_functions--创建分区方案 关联到分区函数CREATE PARTITION SCHEME [Slotecard] AS PARTITION [SlotecardFunction] TO ([PRIMARY], [fg1], [fg2], [fg3], [fg4], [fg5], [fg6], [fg7])--查看已创建的分区方案--select * from sys.partition_schemesALTER TABLE [dbo].[ak_SloteCardTimes] DROP CONSTRAINT [PK_ak_SloteCardTimes]--这里要注意一个语法,因为现在表已经存在了,那么就不能再通过CREATE TABLE的方式来创建分区表了,而是通过创建一个聚集索引的方式。但又把它删除掉。--但是,如果表上面已经有一个聚集索引呢?肯定会出错,因为一个表只能有一个聚集索引。那么该怎么办呢?--我们发现向导会这样做,先把原先的聚集索引改为非聚聚的。ALTER TABLE [dbo].[ak_SloteCardTimes] ADD CONSTRAINT [PK_ak_SloteCardTimes] PRIMARY KEY NONCLUSTERED ( [RecordID] ASC)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]--创建聚集索引CREATE CLUSTERED INDEX [ClusteredIndex_on_Slotecard_635317831823593750] ON [dbo].[ak_SloteCardTimes] (<br> [SloteCardTime])WITH (SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [Slotecard]([SloteCardTime])--删除聚集索引DROP INDEX [ClusteredIndex_on_Slotecard_635317831823593750] ON [dbo].[ak_SloteCardTimes] WITH ( ONLINE = OFF )COMMIT TRANSACTION |
除了提供了创建分区的向导之外,还有一个管理分区的向导,主要是可以做SWITCH,MERGE,SPLIT这些操作。也可以查看数据 也可以手动创建新的分区临时表
|
1
2
3
4
5
6
7
8
|
select $PARTITION.Slotecard([SloteCardTime]) as 分区编号,count([RecordID]) as 记录数 from [ak_SloteCardTimes] group by $PARTITION.Slotecard([SloteCardTime]) -- 查询某个分区--这里我们要用到$PARTITION 函数,这个函数可以帮助我们查询某个分区的数据,还可以检索某个值所隶属的分区号。$PARTITION 函数的进一步细节可以查看MSDN--查询已分区表Order的第一个分区,代码如下: select*from [ak_SloteCardTimes] where $partition.Slotecard ([SloteCardTime])=1 |
理解SQL SERVER中的分区表(转)的更多相关文章
- (转)理解SQL SERVER中的分区表
简介 分区表是在SQL SERVER2005之后的版本引入的特性.这个特性允许把逻辑上的一个表在物理上分为很多部分.而对于SQL SERVER2005之前版本,所谓的分区表仅仅是分布式视图,也就是多个 ...
- 理解SQL SERVER中的分区表
转自:http://www.cnblogs.com/sienpower/archive/2011/12/31/2308741.html 简介 分区表是在SQL SERVER2005之后的版本引入的特性 ...
- T-SQL 理解SQL SERVER中的分区表(转)
转载来源一定要明显: http://www.cnblogs.com/CareySon/archive/2011/12/30/2307766.html 而且这个大神对于数据库方面的文章非常棒 强烈推荐 ...
- 理解SQL Server中的权限体系(下)----安全对象和权限
原文:http://www.cnblogs.com/CareySon/archive/2012/04/12/SQL-Security-SecurableAndPermission.html 在开始阅读 ...
- 理解SQL Server中索引的概念
T-SQL查询进阶--理解SQL Server中索引的概念,原理以及其他 简介 在SQL Server中,索引是一种增强式的存在,这意味着,即使没有索引,SQL Server仍然可以实现应有的功能 ...
- 【转】T-SQL查询进阶—理解SQL Server中的锁
简介 在SQL Server中,每一个查询都会找到最短路径实现自己的目标.如果数据库只接受一个连接一次只执行一个查询.那么查询当然是要多快好省的完成工作.但对于大多数数据库来说是需要同时处理多个查 ...
- 理解SQL Server中的权限体系(上)----主体
原文:http://www.cnblogs.com/CareySon/archive/2012/04/10/mssql-security-principal.html 简介 权限两个字,一个权力,一个 ...
- T-SQL查询进阶—理解SQL Server中的锁
在SQL Server中,每一个查询都会找到最短路径实现自己的目标.如果数据库只接受一个连接一次只执行一个查询.那么查询当然是要多快好省的完成工作.但对于大多数数据库来说是需要同时处理多个查询的.这些 ...
- T-SQL查询进阶--理解SQL Server中索引的概念,原理以及其他
简介 在SQL Server中,索引是一种增强式的存在,这意味着,即使没有索引,SQL Server仍然可以实现应有的功能.但索引可以在大多数情况下大大提升查询性能,在OLAP中尤其明显.要完全理解索 ...
随机推荐
- Android Intent到底能做些什么
Android Intent到底能做些什么 原文:http://www.toutiao.com/i6348296465147757058/?tt_from=mobile_qq&utm_camp ...
- 服务器重启后Oracle监听服务没有自动启动的解决方案
最近一直在被这样一个问题烦恼,就是服务器断电重启后,Oracle监听服务没有正常自动启动(监听服务已经设置为自启动). 具体是这样的,监听服务设置为开机自启动,Oracle数据库服务设置为开机延时启动 ...
- 解决iOS中tabBarItem图片默认颜色的问题(指定代码渲染模式为以原样模式的方式显示出来)
解决iOS中tabBarItem图片默认颜色的问题(指定代码渲染模式为以原样模式的方式显示出来) 解决办法:指定图片的渲染模式(imageWithRenderingMode为:UIImageRende ...
- Sql省市三级联动一张表
CREATE TABLE [dbo].[region]( [region_id] [int] NULL, [region_name] [varchar](50) COLLATE Chinese_PRC ...
- php 之 数据访问 增删改查练习题
练习题内容: 一.查看新闻页面-----主页面: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" ...
- 使用PHP对数据库输入进行恶意代码清除
这是一个有用的PHP函数清理了所有的输入数据,并删除代码注入的几率. function sanitize_input_data($input_data) { $input_data = trim(ht ...
- Tomcat目录下的各个文件夹的作用
1.bin:存放各种不同平台开启与关闭Tomcat的脚本文件. 2.lib:存tomcat与web应用的Jar包 3.conf:存放tomcat的配置文件 4.webapps:web应用的发布目录,包 ...
- iOS知识点全梳理-备用
感谢大神分享 文/Jack_lin(简书作者)原文链接:http://www.jianshu.com/p/5d2163640e26著作权归作者所有,转载请联系作者获得授权,并标注“简书作者”. 序言 ...
- jquery serialize的使用
serialize() 方法通过序列化表单值,创建 URL 编码文本字符串. <!DOCTYPE html> <html lang="en"> <he ...
- intel安装mac os
一.变色龙: 1.http://bbs.pcbeta.com/forum.php?mod=viewthread&tid=1518901&extra=page%3D1%26orderby ...