十八般武艺玩转GaussDB(DWS)性能调优:总体调优策略
摘要: 性能调优是应用迁移或开发过程中的关键步骤,同时也在整个项目实施过程中占据很大的份量,本篇主要介绍数据库级别的性能调优思路和总体策略。
性能调优是应用迁移或开发过程中的关键步骤,同时也在整个项目实施过程中占据很大的份量,在很多实施步骤中都需要进行考虑,从开始的数据建模,表定义的设计,到数据库硬件、集群部署的选择,再到数据库系统级调优、数据表结构设计,以及单个SQL语句的编写及调优,都要考虑对性能的影响。
同时,性能调优通常没有明确的衡量标准,没有明确的对错之分,通常需要的隐式技能比较多,使得其的技术含金量得以提升。通常来看,要做到一个性能调优的高手,除了对于应用程序的逻辑做到游刃有余外,还需要对应用的数据库的基本实现原理有所了解,更甚者,还需要对操作系统、网络等基础知识有所涉猎,同时还要具备性能诊断和分析技巧。当然,性能调优是一个不断积累的过程,大家不用考虑一步到位,唯有进行实践的积累,才能在广阔的调优战场所向披靡。
本篇博文作为《GaussDB(DWS)性能调优系列》的专题文章,主要介绍数据库级别的性能调优思路和总体策略,包括系统级和语句级调优。同时,《GaussDB(DWS)性能调优系列》文章分为基础篇和实战篇,各位读者在通过基础篇文章了解数据库的基本原理后,可以结合调优思路,对实战篇的各个调优技巧进行深入的学习。有关整个调优过程中的其它方面,后续论坛会推出其它博文进行介绍。
1. GaussDB DWS执行架构及说明
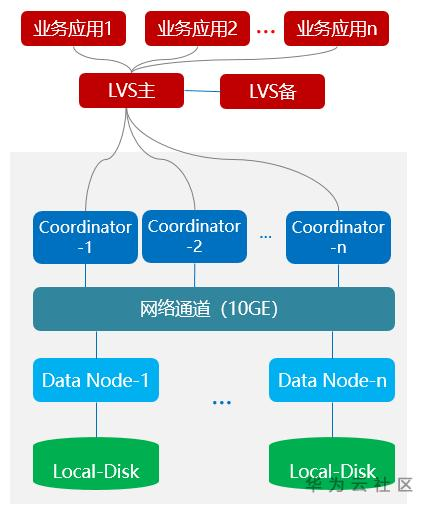
GaussDB DWS是典型的share-nothing架构,其计算组件的示意图如上图所示,主要由CN(Coordinator)和DN(DataNode)组成。CN是整个集群的协调者,是整个集群与应用进行连接处理的门户,用于接收客户的SQL语句并返回执行结果。DN是集群进行数据计算的主体,各个DN拥有独立的存储和计算资源,使得各个DN可以独立地进行计算。GaussDB DWS支持多CN架构,通常应用程序会通过LVS(负载均衡设备)将语句均匀分发到各个CN上,以减少单个CN的瓶颈作用。
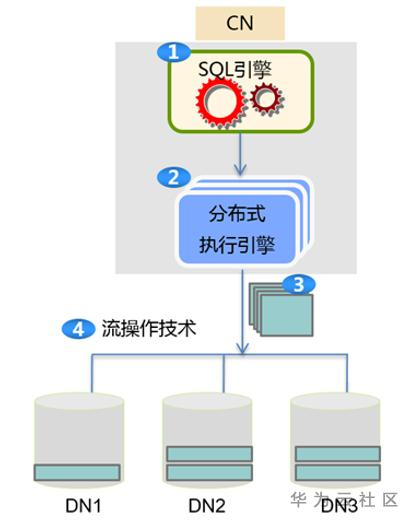
GaussDB DWS的SQL处理流程如上方右图所示,其包含以下几个主要步骤:(1)CN通过驱动或客户端接收到一条SQL后,会进行解析、优化,并最终返回执行结果;(2)CN进行优化后,生成相应的执行计划;(3)CN将相同的执行计划下发到各个DN进行执行;(4)如果DN之间需要进行数据交换,则执行计划中包含流操作算子Stream,DN之间同步通过Stream算子进行数据交换,共同完成计划的执行并向CN返回结果。同时,GaussDB DWS对于不需要DN间数据交换的语句,还支持语句下发到DN生成计划;对于部分不支持分布式查询的语句,生成不能下推的计划(此计划对于大数据量性能较差)。各种计划的对比可详见博文《GaussDB(DWS)性能调优系列基础篇三:衍化至繁之分布式计划详解》。本文后续的讨论均基于Stream计划。
2. 整体调优思路
通过前面对SQL语句执行流程的介绍,我们可以知道,性能瓶颈可能发生在CN端、DN端,以及结果集返回,驱动数据处理等环节,性能调优的第一步就是定位瓶颈点主要发生在哪个环节。由于GaussDB DWS大数据量处理时,大部分执行时间消耗在DN端,故本博文主要针对DN端语句执行进行总体调优思路的分享。
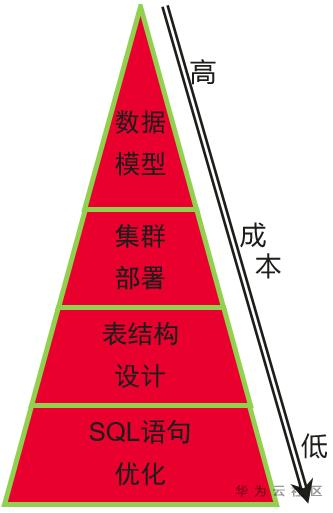
谈到执行性能,其实从数据模型建模、集群部署、表结构设计,到最终的SQL语句优化,都与之紧密相关,如上图所示,我们使用金字塔来描述整个调优过程。越接近塔尖,其对于整个业务性的影响范围越广,需要调优时,调优成本也越高,所以在设计之初需要投入足够精力,从上至下,我们需要全面的设计,才能减少在最终SQL调优时返工的可能。
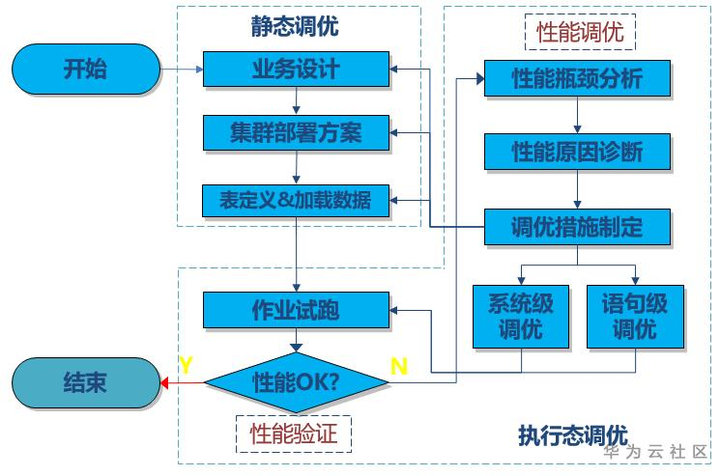
整个调优过程其实是一个不断迭代的过程,如上图所示。即使设计再严密,也有可能出现SQL语句性能的优化需要导致数据建模更改、集群部署、表分布键调整的情况,这时一发动全身将引起较高的成本,同时会对其它已经调优完毕的SQL产生影响,导致重新调优,成本较高。
我们统一将前三阶段归结为静态调优,将SQL语句级调优归结为执行态调优。下面重点来探讨执行态调优-SQL语句调优,从调优步骤来看可以分为性能瓶颈诊断、性能原因分析和调优项实施,从调优实施对象来看,可能包括前面提到的数据建模、集群部署、表结构设计方面的修改,SQL语句层调优可以分为系统级调优和语句级调优。当然,有一些调优项,例如系统调优项,可以作为经验固化下来,在集群部署的时候就一并设置好,减少这方面调优花费的成本。同时,SQL调优也是一个迭代的过程,在实施一次调优项后,需要继续重新进行调优分析,直至性能达到标准为止。后面的章节,将围绕调优步骤和SQL层的调优项来开展。
3. 性能瓶颈诊断
GaussDB DWS提供了丰富的计划信息显示工具Explain,以及动态执行信息分析工具Top SQL。
Explain工具主要针对单个语句进行展示,可以使用explain命令显示CN生成的SQL语句的计划,也可以使用explain analyze/performance命令显示执行态信息。通过执行态信息,我们可以分析出算子为单位的性能,也可以分析出算子内部各步骤的性能,进一步为诊断性能的瓶颈打下了基础。Explain工具相关内容请参考博文《GaussDB(DWS)性能调优系列基础篇二:大道至简explain计划信息》。
Top SQL工具则针对集群中运行的语句进行整体性能分析,其包含12个视图,可以将执行时间超过一定设置阈值的语句的执行状态、执行结果进行实时查询,同时可以设置将其转储用作后续分析。附加于该工具之上的SQL自诊断调优工具,则通过瓶颈点的分析,给出可能的性能原因分析。同时,我们还提供Unique SQL工具,进行一类SQL的性能持续跟踪,可以用于发现系统资源及硬件问题对SQL性能产生的影响。Top SQL工具相关内容请参考博文《GaussDB(DWS)性能调优系列实战篇二:十八般武艺之坏味道SQL识别》。
4. 性能原因分析
性能原因分析属于性能调优里的高阶知识了,通常要对数据库的执行实现原理有基本了解才能够逐步深入下去。本章节将深入浅出地介绍数据库执行实现原理的基本技术,帮助各位读者朋友能够有兴趣去主动查找性能产生的原因,从而自己找到性能调优的方法。
前面已经对GaussDB DWS的执行流程进行了介绍,由CN生成执行计划下发到DN去执行。GaussDB DWS是基于代价来生成计划的,因此需要依据基表的统计信息,进行每一步结果集统计信息的估算,根据数据规模的场景从GaussDB DWS支持的备选算子中选择最优的算子组合成计划进行执行。因此,统计信息是计划准确的前提,在执行SQL语句前要确保收集最新的统计信息,有关统计信息的收集可以参见博文《GaussDB(DWS)性能调优系列基础篇一:万物之始analyze统计信息》。
由于统计信息只包含基表的统计信息,表关联之后的统计信息只能通过估算得到,因此仍然可能存在估算不准的情况。GaussDB DWS针对不同的SQL语句中的操作,为每个操作内部实现了不同的算子。每个算子可能在部分场景下是占优的,但其它场景比较差。SQL优化时,根据具体的场景去自动匹配最优的算子。如果存在估算不准,将导致算子选择出现失误,从而计划较差,此时就需要根据计划的瓶颈来分析具体的原因了。
通常情况下,GaussDB处理的操作类型主要分为:扫描算子(Scan)、关联算子(Join)、聚集算子(Agg)和网络传输算子(Stream)。下表列出了各算子类别的使用场景,以及各类别中可选的算子,及其适用范围,同时列出调优场景,供大家参考。
(1)扫描算子(Scan):主要用于处理从存储扫描数据,返回上层算子,包括:全表扫描算子、索引扫描算子,其中行列存均对应不同的全套扫描算子,索引扫描包括:IndexScan(普通索引扫描)、IndexOnlyScan(仅扫描索引即可获得结果)、BitmapScan(需要索引扫描获取位图后再到基表上扫描),BitmapScanAnd/Or(从多个索引扫描进行位图运算后再到基表上扫描),由于索引扫描的原理基本都相同,故一并探讨。
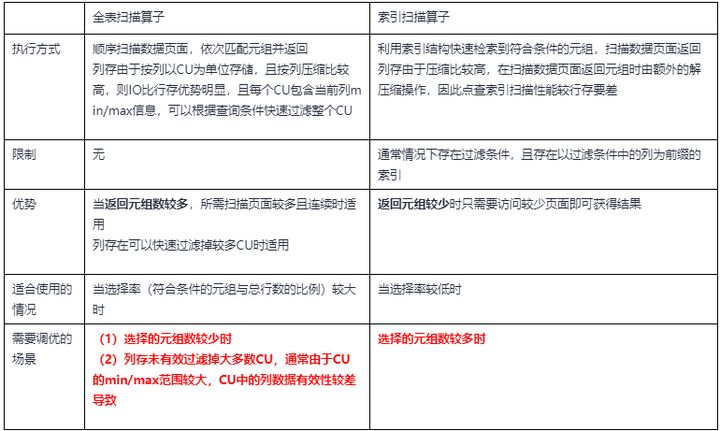
(2)关联算子(Join):主要用于处理表的关联操作。在数据库中,多表关联时,SQL优化会选择关联顺序进行两两关联。表关联时可以包含关联操作,也可以没有关联操作(笛卡尔积)。在GaussDB DWS中,主要包含NestLoop, HashJoin, MergeJoin三种关联算子。
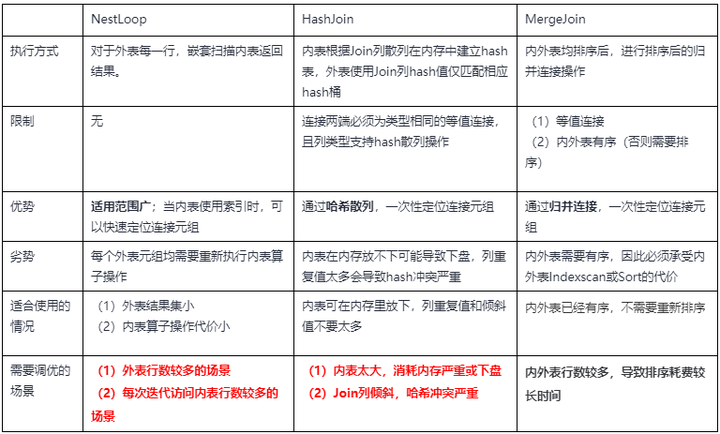
(3)聚集算子(Agg):
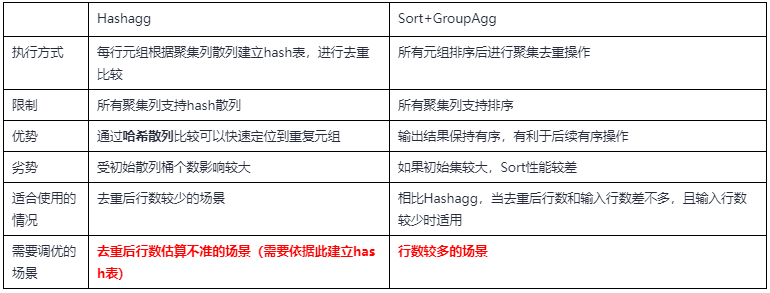
(4)网络传输算子(Stream):

(5)其它算子:同时GaussDB DWS还支持排序(Sort)、集合(SetOp)、物化(Materialize)、窗口聚集(WindowAgg)和输出限制(Limit)算子,由于调优基本不涉及,故此处略过。
5. 调优项实施
在知道导致性能问题的原因后,就可以制定调优项并开始实施了。前面已经提到,调优项实施的范围很广。本博文仅探讨数据库级的调优项,包括系统级调优和语句级调优两部分。
a)系统级调优项
系统级调优又细分为操作系统参数调优和数据库全局参数调优,通常涉及到的是系统CPU、IO、内存、网络资源的充分使用,避免资源冲突,提升整个系统查询的吞吐量。
由于数据库是运行在操作系统之上的,因此操作系统资源的利用率对于数据库性能的提升起到基石的作用。对于操作系统参数的调优,主要集中在操作系统内存参数、IO参数以及网络参数的设置上,具体可参见GaussDB DWS产品文档。
数据库级别的调优,主要也是集中在上述资源的使用上,在上述四维度有以下主要因素的考虑(具体设置方法可以参见GaussDB DWS产品文档):

b)语句级调优项
语句级调优通常需要通过计划分析,找到性能瓶颈点,然后根据瓶颈点对应的扫描、关联、聚集、Stream等算子,分析是否属于算子适用场景,是否符合调优条件。如果是,我们有以下调优手段:
i. 通过修改表定义,包括行列存、表的分布方式,达到减少IO和网络资源开销的目的,详见博文《GaussDB(DWS)性能调优系列实战篇三:十八般武艺之好味道表定义》。
ii. 如果最终分析是由于估算不准导致,可以通过相关GUC参数调整来设置不同的结果集估算模型,或禁止生成某种类型的算子,通过改进估算值达到优化计划的目的,详见博文《GaussDB(DWS)性能调优系列实战篇五:十八般武艺之路径干预》。
iii.如果在迁移或升级过程中出现计划劣化,也可以通过Plan Hint的调优方式干预优化器生成理想的计划,详见博文《GaussDB(DWS)性能调优系列实战篇六:十八般武艺Plan hint运用》。
iv.对于上述调优手段都无法解决的问题,例如:下推问题,相关子查询提升,NOT IN等问题,或者SQL语句存在计算冗余等问题,需要根据瓶颈点选择灵活多变的SQL改写策略消除瓶颈点,具体可参见博文《GaussDB(DWS)性能调优系列实战篇四:十八般武艺之SQL改写》
总的来说,性能调优是一项艰巨的工程,当然深入其中,学习到的知识以及获得的收获都是非常大的。后续论坛也会推出更多的博文对性能调优的方方面面进行介绍,帮助各位读者迅速积累调优的经验。
十八般武艺玩转GaussDB(DWS)性能调优:总体调优策略的更多相关文章
- 十八般武艺玩转GaussDB(DWS)性能调优:SQL改写
摘要:本文将系统介绍在GaussDB(DWS)系统中影响性能的坏味道SQL及SQL模式,帮助大家能够从原理层面尽快识别这些坏味道SQL,在调优过程中及时发现问题,进行整改. 数据库的应用中,充斥着坏味 ...
- 十八般武艺玩转GaussDB(DWS)性能调优:路径干预
摘要:路径生成是表关联方式确定的主要阶段,本文介绍了几个影响路径生成的要素:cost_param, scan方式,join方式,stream方式,并从原理上分析如何干预路径的生成. 一.cost模型选 ...
- 十八般武艺玩转GaussDB(DWS)性能调优(三):好味道表定义
摘要:表结构设计是数据库建模的一个关键环节,表定义好坏直接决定了集群的有效容量以及业务查询性能,本文从产品架构.功能实现以及业务特征的角度阐述在GaussDB(DWS)的中表定义时需要关注的一些关键因 ...
- Java性能调优(一):调优的流程和程序性能分析
https://blog.csdn.net/Oeljeklaus/article/details/80656732 Java性能调优 随着应用的数据量不断的增加,系统的反应一般会越来越慢,这个时候我 ...
- java性能调优---------------------JVM调优方案
JVM的调优的主要过程有: 1.确定堆内存大小(-Xmx.-Xms) 2.合理分配新生代和老年代(-XX:NewRatio.-Xmn.-XX:SurvivorRatio) 3.确定永久区大小(-XX: ...
- java虚拟机学习-JVM调优总结-调优方法(12)
JVM调优工具 Jconsole,jProfile,VisualVM Jconsole : jdk自带,功能简单,但是可以在系统有一定负荷的情况下使用.对垃圾回收算法有很详细的跟踪.详细说明参考这里 ...
- spark调优——JVM调优
对于JVM调优,首先应该明确,(major)full gc/minor gc,都会导致JVM的工作线程停止工作,即stop the world. JVM调优一:降低cache操作的内存占比 1. ...
- spark调优——Shuffle调优
在Spark任务运行过程中,如果shuffle的map端处理的数据量比较大,但是map端缓冲的大小是固定的,可能会出现map端缓冲数据频繁spill溢写到磁盘文件中的情况,使得性能非常低下,通过调节m ...
- spark调优——算子调优
算子调优一:mapPartitions 普通的map算子对RDD中的每一个元素进行操作,而mapPartitions算子对RDD中每一个分区进行操作.如果是普通的map算子,假设一个partition ...
- JVM 调优 内存调优 CPU 使用调优 锁竞争调优 I/O 调优
Twitter 工程师谈 JVM 调优 2016年03月24日 10:22:30 wenniuwuren https://blog.csdn.net/wenniuwuren/article/detai ...
随机推荐
- 12. 用Rust手把手编写一个wmproxy(代理,内网穿透等), TLS的双向认证信息及token验证
12. 用Rust手把手编写一个wmproxy(代理,内网穿透等), TLS的双向认证信息及token验证 项目 ++wmproxy++ gite: https://gitee.com/tickbh/ ...
- 双数组字典树 (Double-array Trie) -- 代码 + 图文,看不懂你来打我
目录 Trie 字典树 双数组Trie树 构建 字符编码 计算规则 构建 Base Array.Check Array 处理字典首字 处理字典二层字 处理字典三层字 处理字典四层字 叶子节点处理 核心 ...
- OpenTiny Vue 支持 Vue2.7 啦!
你好,我是 Kagol. 前言 上个月发布了一篇 Vue2 升级 Vue3 的文章. 少年,该升级 Vue3 了! 里面提到使用了 ElementUI 的 Vue2 项目,可以通过 TinyVue 和 ...
- RSA总结 From La神
常用工具 分解大素数 factordb (http://www.factordb.com / API: http://factordb.com/api?query=) yafu (p q 相差过大或过 ...
- IDEA的Maven换源
打开IDEA安装路径,然后打开下面的文件夹 plugins\maven\lib\maven3\conf 在conf文件目录下出现一个setting.xml的文件.(ps:如果没有,请忽略本文,自行创建 ...
- Vue 项目部署到GitHub Pages并同步到Gitee Pages
前言:相信很多前端开发者都拥有自己的vue项目,若想把自己的项目做成网站分享给大家看,最常用的就是利用Github提供的GitHub Pages服务和Gitee提供的Gitee Pages服务.其中, ...
- TiDB binlog故障处理之drainer周期性罢工
背景 前段时间用户反馈某生产环境 TiDB 集群 drainer 频繁发生故障,要么服务崩溃无法启动,要么数据跑着跑着就丢失了,很是折磨人.该集群跑的是离线分析业务,数据量20T ,v4版本,有多个 ...
- string函数部分解释
```c1. 运算符重载+.+= 连接字符串= 字符串赋值>.>=.<.<= 字符串比较(例如a < b, aa < ab)==.!= 比较字符串<<. ...
- C# 12 Blazor入门教程
Blazor简介 Blazor 是由Microsoft开发的一款基于.NET的开源交互式Web UI框架.Blazor使开发人员能够使用C#和HTML建立全堆栈的单页应用程序,并避免使用JavaScr ...
- (Good topic)双指针:判断子序列
给定字符串 s 和 t ,判断 s 是否为 t 的子序列. 你可以认为 s 和 t 中仅包含英文小写字母.字符串 t 可能会很长(长度 ~= 500,000),而 s 是个短字符串(长度 <=1 ...