2021-05-29:最常使用的K个单词II。在实时数据流中找到最常使用的k个单词,实现TopK类中的三个方法: Top
2021-05-29:最常使用的K个单词II。在实时数据流中找到最常使用的k个单词,实现TopK类中的三个方法: TopK(k), 构造方法。add(word),增加一个新单词。topk(),得到当前最常使用的k个单词。如果两个单词有相同的使用频率,按字典序排名。
福大大 答案2021-05-30:
方法一:
redis的sorted set。hash+跳表实现计数和查找。无代码。
方法二:
节点结构体:有字符串和词频。
词频表:key是字符串,value是节点。
堆:节点数组。刚开始,我以为是大根堆。采用小根堆,如果比堆顶还小,是进不了小根堆的。
反向表:key是节点,value是在堆中的索引。
有代码。
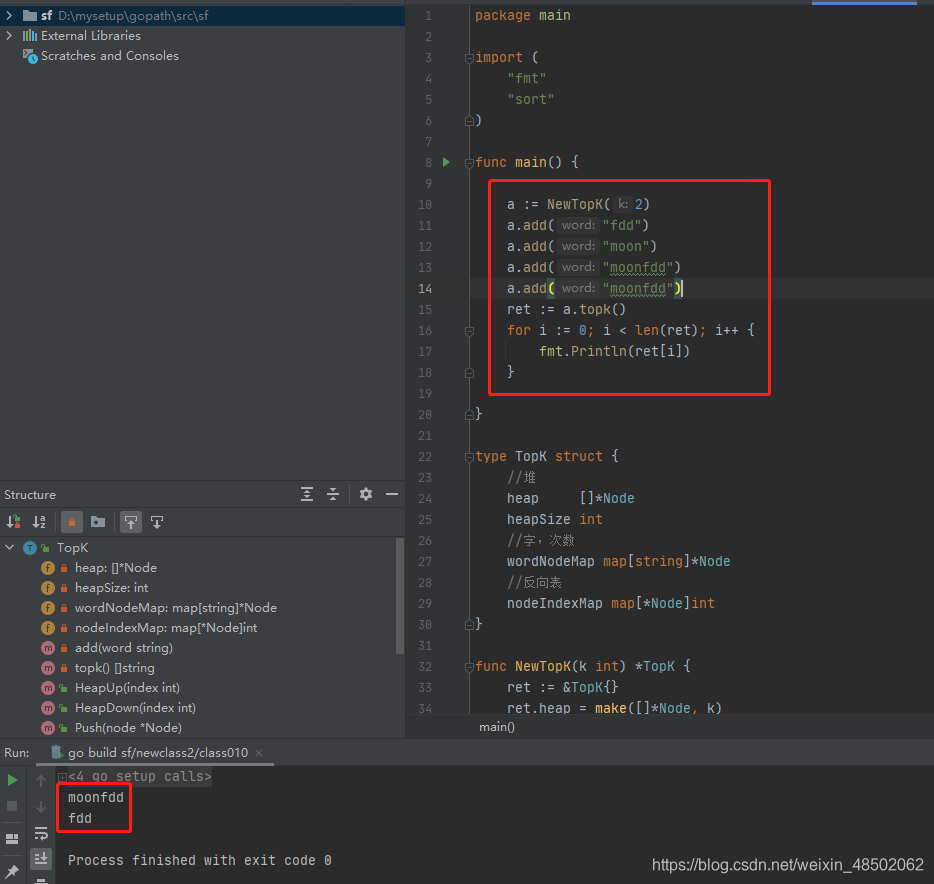
代码用golang编写。代码如下:
package main
import (
"fmt"
"sort"
)
func main() {
a := NewTopK(2)
a.add("fdd")
a.add("moon")
a.add("moonfdd")
a.add("moonfdd")
ret := a.topk()
for i := 0; i < len(ret); i++ {
fmt.Println(ret[i])
}
}
type TopK struct {
//堆
heap []*Node
heapSize int
//字,次数
wordNodeMap map[string]*Node
//反向表
nodeIndexMap map[*Node]int
}
func NewTopK(k int) *TopK {
ret := &TopK{}
ret.heap = make([]*Node, k)
ret.wordNodeMap = make(map[string]*Node)
ret.nodeIndexMap = make(map[*Node]int)
return ret
}
func (this *TopK) add(word string) {
if len(this.heap) == 0 {
return
}
var curNode *Node
preIndex := -1
curNode = this.wordNodeMap[word]
//词频表 反向表
if curNode == nil {
curNode = &Node{word, 1}
this.wordNodeMap[word] = curNode
this.nodeIndexMap[curNode] = -1
} else {
curNode.Times++
preIndex = this.nodeIndexMap[curNode]
}
//小根堆
if preIndex == -1 {
if this.heapSize == len(this.heap) {
if this.compare(curNode, this.heap[0]) {
//不用管了
return
}
curNode, this.heap[0] = this.heap[0], curNode
this.nodeIndexMap[curNode] = -1
this.nodeIndexMap[this.heap[0]] = 0
this.HeapDown(0)
} else {
this.Push(curNode)
}
} else {
this.HeapDown(preIndex)
}
}
func (this *TopK) topk() []string {
heapCopy := make([]*Node, this.heapSize)
copy(heapCopy, this.heap)
sort.Slice(heapCopy, func(i, j int) bool {
return !this.compare(heapCopy[i], heapCopy[j])
})
ans := make([]string, this.heapSize)
for i := 0; i < this.heapSize; i++ {
ans[i] = heapCopy[i].Str
}
return ans
}
type Node struct {
Str string
Times int
}
//索引上移,小根堆
func (this *TopK) HeapUp(index int) {
for (index-1)/2 != index && !this.compare(this.heap[(index-1)/2], this.heap[index]) { //父节点小于当前节点,当前节点必须上移
this.heap[index], this.heap[(index-1)/2] = this.heap[(index-1)/2], this.heap[index]
//加强堆
this.nodeIndexMap[this.heap[index]], this.nodeIndexMap[this.heap[(index-1)/2]] = (index-1)/2, index
index = (index - 1) / 2
}
}
//索引下沉,小根堆
func (this *TopK) HeapDown(index int) {
left := 2*index + 1
for left <= this.heapSize-1 { //左孩子存在
//获取小孩子
largest := left
if left+1 <= this.heapSize-1 && this.compare(this.heap[left+1], this.heap[left]) {
largest++
}
//比较
if !this.compare(this.heap[index], this.heap[largest]) { //当前大于最小孩子,必须下沉
this.heap[index], this.heap[largest] = this.heap[largest], this.heap[index]
//加强堆
this.nodeIndexMap[this.heap[index]], this.nodeIndexMap[this.heap[largest]] = largest, index
} else {
break
}
//下一次遍历
index = largest
left = 2*index + 1
}
}
func (this *TopK) Push(node *Node) {
this.heap[this.heapSize] = node
//加强堆
this.nodeIndexMap[node] = this.heapSize
//索引上移
this.HeapUp(this.heapSize)
this.heapSize++
}
func (this *TopK) Pop() *Node {
ans := this.heap[0]
this.heap[0], this.heap[this.heapSize-1] = this.heap[this.heapSize-1], this.heap[0]
//加强堆
this.nodeIndexMap[this.heap[0]] = 0
this.nodeIndexMap[this.heap[this.heapSize-1]] = -1
this.heapSize--
//索引下沉
this.HeapDown(0)
return ans
}
func (this *TopK) compare(node1 *Node, node2 *Node) bool {
if node1.Times == node2.Times {
return node1.Str > node2.Str
}
return node1.Times < node2.Times
}
执行结果如下:
福大大 答案2021-05-29:
方法一:
redis的sorted set。hash+跳表实现计数和查找。无代码。
方法二:
节点结构体:有字符串和词频。
词频表:key是字符串,value是节点。
堆:节点数组。
反向表:key是节点,value是在堆中的索引。
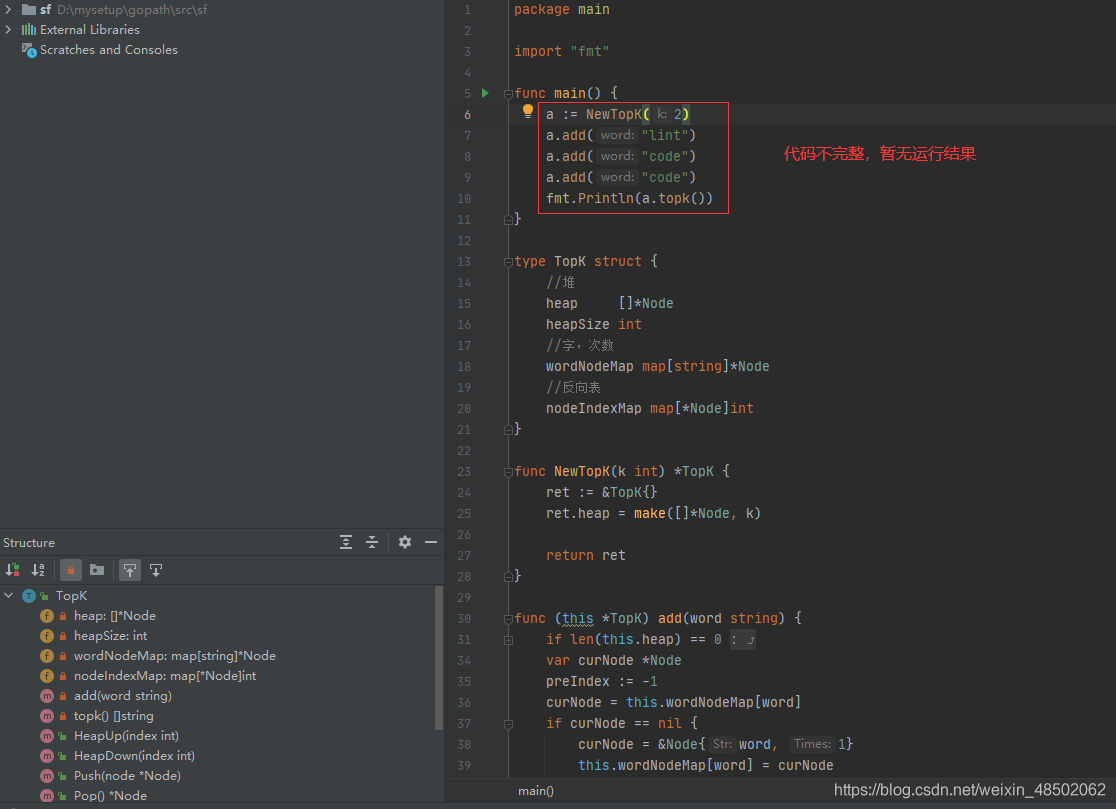
有代码,但不完整,因为时间紧。
代码用golang编写。代码如下:
package main
import "fmt"
func main() {
a := NewTopK(2)
a.add("lint")
a.add("code")
a.add("code")
fmt.Println(a.topk())
}
type TopK struct {
//堆
heap []*Node
heapSize int
//字,次数
wordNodeMap map[string]*Node
//反向表
nodeIndexMap map[*Node]int
}
func NewTopK(k int) *TopK {
ret := &TopK{}
ret.heap = make([]*Node, k)
return ret
}
func (this *TopK) add(word string) {
if len(this.heap) == 0 {
return
}
var curNode *Node
preIndex := -1
curNode = this.wordNodeMap[word]
if curNode == nil {
curNode = &Node{word, 1}
this.wordNodeMap[word] = curNode
this.nodeIndexMap[curNode] = -1
} else {
//tree set
curNode.Times++
preIndex = this.nodeIndexMap[curNode]
}
if preIndex == -1 {
if this.heapSize == len(this.heap) {
//treeset
} else {
//tree add
this.nodeIndexMap[curNode] = this.heapSize
this.heap[this.heapSize] = curNode
this.HeapUp(preIndex)
}
} else {
//tree add
this.HeapDown(preIndex)
}
}
func (this *TopK) topk() []string {
ans := make([]string, len(this.heap))
return ans
}
type Node struct {
Str string
Times int
}
//索引上移,大根堆
func (this *TopK) HeapUp(index int) {
for this.heap[(index-1)/2].Times < this.heap[index].Times { //父节点小于当前节点,当前节点必须上移
this.heap[index], this.heap[(index-1)/2] = this.heap[(index-1)/2], this.heap[index]
//加强堆
this.nodeIndexMap[this.heap[index]], this.nodeIndexMap[this.heap[(index-1)/2]] = (index-1)/2, index
index = (index - 1) / 2
}
}
//索引下沉,大根堆
func (this *TopK) HeapDown(index int) {
left := 2*index + 1
for left <= this.heapSize-1 { //左孩子存在
//获取大孩子
largest := left
if left+1 <= this.heapSize-1 && this.heap[left+1].Times > this.heap[left].Times {
largest++
}
//比较
if this.heap[index].Times < this.heap[largest].Times { //当前小于最大孩子,必须下沉
this.heap[index], this.heap[largest] = this.heap[largest], this.heap[index]
//加强堆
this.nodeIndexMap[this.heap[index]], this.nodeIndexMap[this.heap[largest]] = largest, index
} else {
break
}
//下一次遍历
index = largest
left = 2*index + 1
}
}
func (this *TopK) Push(node *Node) {
this.heap[this.heapSize] = node
//加强堆
this.nodeIndexMap[node] = this.heapSize
this.heapSize++
//索引上移
this.HeapUp(this.heapSize)
}
func (this *TopK) Pop() *Node {
ans := this.heap[0]
this.heap[0], this.heap[this.heapSize-1] = this.heap[this.heapSize-1], this.heap[0]
//加强堆
this.nodeIndexMap[this.heap[0]] = 0
this.nodeIndexMap[this.heap[this.heapSize-1]] = -1
this.heapSize--
//索引下沉
this.HeapDown(0)
return ans
}
执行结果如下:
2021-05-29:最常使用的K个单词II。在实时数据流中找到最常使用的k个单词,实现TopK类中的三个方法: Top的更多相关文章
- 《程序员代码面试指南》第八章 数组和矩阵问题 在数组中找到出现次数大于N/K 的数
题目 在数组中找到出现次数大于N/K 的数 java代码 package com.lizhouwei.chapter8; import java.util.ArrayList; import java ...
- 2021.05.29【NOIP提高B组】模拟 总结
T1 题意:给你一个图,可以不花代价经过 \(K\) 条边,问从起点到终点的最短路 考试的想法:设 \(dis_{i,j}\) 表示从起点免费了 \(j\) 条边到 \(i\) 的最短路 然后直接跑 ...
- [算法]在数组中找到出现次数大于N/K的数
题目: 1.给定一个整型数组,打印其中出现次数大于一半的数.如果没有出现这样的数,打印提示信息. 如:1,2,1输出1. 1,2,3输出no such number. 2.给定一个整型数组,再给 ...
- 2021.10.29 数位dp
2021.10.29 数位dp 1.数字计数 我们先设数字为ABCD 看A000,如果我们要求出它所有数位之和,我们会怎么求? 鉴于我们其实已经求出了0到9,0到99,0到999...上所有数字个数( ...
- 2021.05.03 T3 数字
2021.05.03 T3 数字 问题描述 一个数字被称为好数字当他满足下列条件: 1. 它有**2*n**个数位,n是正整数(允许有前导0) 2. 构成它的每个数字都在给定的数字集合S中. 3. 它 ...
- 2021.05.14 tarjan
2021.05.14 tarjan 标准版tarjan 这里使用数组来模拟栈 void tarjan(int x){ ++ind; dfn[x]=low[x]=ind; stacki[++top]=x ...
- 项目Beta冲刺(团队)——05.29(7/7)
项目Beta冲刺(团队)--05.29(7/7) 格式描述 课程名称:软件工程1916|W(福州大学) 作业要求:项目Beta冲刺(团队) 团队名称:为了交项目干杯 作业目标:记录Beta敏捷冲刺第7 ...
- 2021.6.29考试总结[NOIP模拟10]
T1 入阵曲 二位前缀和暴力n4可以拿60. 观察到维护前缀和时模k意义下余数一样的前缀和相减后一定被k整除,前缀和维护模数,n2枚举行数,n枚举列, 开一个桶记录模数出现个数,每枚举到该模数就加上它 ...
- 2021.10.29 P1649 [USACO07OCT]Obstacle Course S(BFS)
2021.10.29 P1649 [USACO07OCT]Obstacle Course S(BFS) 题意: 给一张n*n的图,起点为A,终点为 B,求从A到B转弯次数最少为多少. 分析: 是否存在 ...
- 2021.05.09【NOIP提高组】模拟赛总结
2021.05.09[NOIP提高组]模拟赛总结 T1 T2
随机推荐
- Java8-聚合操作
Java聚合操作(Aggregate Operations)是对一堆数据进行处理的新的操作方法,我们知道,如果想对一堆数据进行处理,比如一个List对象中的数据进行处理,传统的操作就是遍历List数据 ...
- pom文件信息的解析
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://mave ...
- java代码审计-SpEL表达式注入
0x01 前言 Spring Expression Language(简称 SpEL)是一种功能强大的表达式语言.用于在运行时查询和操作对象图:语法上类似于Unified EL,但提供了更多的特性,特 ...
- Centos 7安装ansible自动化运维工具
1.介绍: ansible是新出现的自动化运维工具,基于Python开发,集合了众多运维工具(puppet.SaltStack.chef.func)的优点,实现了批量系统配置.批量程序部署.批 ...
- python3各数据类型的常用方法
python3数据类型包括: 数字.字符串str.列表list.元组tuple.字典dict.集合set.布尔bool 1.字符串(str)-可变-用"".''定义 (1)uppe ...
- CISCN2021-第十四届全国大学生信息安全竞赛-WriteUp
WriteUp - Maple_root -CISCN2021 总结 总得分:3400 总排名:203 赛区排名:21 第一次认真参加正式的CTF,24+3小时的脑血栓比赛时长,收获还是很多的. 开卷 ...
- Java---->枚举类
自定义的枚举类 package doy1; /** * @author shkstart * @create 2021-10-28 19:23 */ /** * 一.枚举类的使用 * 1.枚举类的理解 ...
- SELinux入门学习总结
前言 安全增强型 Linux(Security-Enhanced Linux)简称 SELinux,它是一个 Linux 内核模块,也是 Linux 的一个安全子系统. SELinux 主要由美国国家 ...
- [Nginx/Linux/CENTOS]安装Nginx
1 基本信息 服务器OS : Linux CENTSO 7.9 待安装的Nginx版本: NGINX 15.12 2 安装过程 step1 下载安装包 # cd /usr/local/software ...
- [Linux]浅析"command > /dev/null 2>&1 &" 与 "command 1>/dev/null 2>&1 &"
1 问题描述 1.1 问题描述 在一项目中查看CENTOS 服务器的定时任务crontab时查看到如下这段命令: 命令clearLog.sh > /dev/null 2>&1 &a ...