Java 爬取 51job 数据 WebMagic实现
Java 爬取 51job 数据
一、项目Maven环境配置
相关依赖 jar 包配置
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.2.RELEASE</version>
</parent>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<!--SpringMVC-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--SpringData Jpa-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!--MySQL连接包-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!--WebMagic核心包-->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--WebMagic扩展-->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
<!--WebMagic对布隆过滤器的支持-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>16.0</version>
</dependency>
<!--工具包-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
</dependency>
</dependencies>
application.properties 配置文件
#DB Configuration:
spring.datasource.driverClassName=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/crawler
spring.datasource.username=root
spring.datasource.password=root
#JPA Configuration:
spring.jpa.database=MySQL
spring.jpa.show-sql=true
二、相关类
pojo 类
@Entity
public class JobInfo {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String companyName;
private String companyAddr;
private String companyInfo;
private String jobName;
private String jobAddr;
private String jobInfo;
private Integer salaryMin;
private Integer salaryMax;
private String url;
private String time;
... toString() 、 get/set()方法略
}
dao 类
public interface JobInfoDao extends JpaRepository<JobInfo,Long> {}
Service 类
public interface JobInfoService {
/**
* 保存工作信息
*
* @param jobInfo
*/
public void save(JobInfo jobInfo);
/**
* 根据条件查询工作信息
*
* @param jobInfo
* @return
*/
public List<JobInfo> findJobInfo(JobInfo jobInfo);
}
ServiceImpl 类
@Service
public class JobInfoServiceImpl implements JobInfoService {
@Autowired
private JobInfoDao jobInfoDao;
// 查询原有的数据
// 判断数据库是否有已存在的数据
// 如果存在,就执行更新
// 不存在,就执行新增
@Override
@Transactional
public void save(JobInfo jobInfo) {
// 根据查询结果是否为空
JobInfo param = new JobInfo();
param.setUrl(jobInfo.getUrl());
param.setTime(jobInfo.getTime());
// 执行查询
List<JobInfo> list = this.findJobInfo(param);
// 判断查询结果是否为空
if (list.size()==0){
// 如果查询结果为空,表示招聘信息数据不存在,或者已经更新了,需要新增或更新数据库
this.jobInfoDao.saveAndFlush(jobInfo); // 新增或更新方法
}
}
@Override
public List<JobInfo> findJobInfo(JobInfo jobInfo) {
// 设置查询条件
Example example = Example.of(jobInfo);
// 执行查询
List list = this.jobInfoDao.findAll(example);
return list;
}
}
功能实现类 Task
@Component
public class JobProcessor implements PageProcessor {
private String url = "https://search.51job.com/list/000000,000000,0000,32%252C01,9,99,java,2,1.html?lang=c&stype=&postchannel=0000" +
"&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0" +
"&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=";
@Override
public void process(Page page) {
// 解析页面,获取招聘信息详情的url地址
List<Selectable> list = page.getHtml().css("div#resultList div.el").nodes();
// 判断获取到的集合是否为空
if (list.size()==0){
// 如果为空,表示这是招聘详情页,解析页面,获取招聘详情信息,保存数据
this.saveJobInfo(page);
}else {
// 如果不为空,表示这是列表页,解析出详情页的url地址,放到任务队列中
for (Selectable selectable : list) {
// 获取到url地址
String JobInfoUrl = selectable.links().toString();
// 把获取到url地址放到任务队列中
page.addTargetRequest(JobInfoUrl);
}
// 获取下一列功能的url
String nextUrl = page.getHtml().css("div.p_in li.bk").nodes().get(1).links().toString();
// 把url放到任务队列中
page.addTargetRequest(nextUrl);
}
}
/**
* 解析页面,获取招聘详情信息,保存数据
* @param page
*/
private void saveJobInfo(Page page) {
// 创建招聘详情对象
JobInfo jobInfo = new JobInfo();
// 解析页面
Html html = page.getHtml();
// 获取数据,封装到对象中
// 公司名字
jobInfo.setCompanyName(html.css("div.cn p.cname a", "text").toString());
// 公司地址
String cAddr = Jsoup.parse(html.css("div.cn p.ltype", "text").toString()).text().replace("-","");
cAddr = cAddr.substring(0,6);
jobInfo.setCompanyAddr(cAddr);
// 公司信息
jobInfo.setCompanyInfo(Jsoup.parse(html.css("div.tmsg", "text").toString()).text());
// 工作名字
jobInfo.setJobName(html.css("div.cn h1", "text").toString());
// 工作地址
String jAddr = Jsoup.parse(html.css("div.bmsg").nodes().get(1).toString()).text();
// 部分公司暂没有填写公司详细地址,得非空判断
if (StringUtils.isBlank(jAddr)){
jobInfo.setJobAddr(jobInfo.getCompanyAddr());
}else {
jAddr = jAddr.replace("地图","");
jobInfo.setJobAddr(jAddr);
}
// 工作信息
jobInfo.setJobInfo(Jsoup.parse(html.css("div.job_msg").toString()).text());
// 个人薪水
Integer[] salary = MathSalarys.getSalary(html.css("div.cn strong", "text").toString());
jobInfo.setSalaryMin(salary[0]);
jobInfo.setSalaryMax(salary[1]);
// 发布时间
String time = Jsoup.parse(html.css("div.cn p.msg", "text").toString()).text();
int length = time.lastIndexOf("发布");
jobInfo.setTime(time.substring(length-5,length));
// url地址
jobInfo.setUrl(page.getUrl().toString());
// 把结果保存起来,等待 ResultItem获取 获取
page.putField("jobInfo",jobInfo);
}
private Site site = Site.me()
.setCharset("gbk") // 设置字符集
.setTimeOut(10*1000) // 设置超时时间
.setRetrySleepTime(3000) // 设置重试时间的间隔
.setRetryTimes(3); // 设置重试次数
@Override
public Site getSite() {
return site;
}
@Autowired
private SpringDataPipeline pipeline;
// initialDelay:当任务启动后,等等多久执行方法
// fixedDelay:每隔多久执行方法
@Scheduled(initialDelay = 1000,fixedDelay = 10000)
public void process(){
Spider.create(new JobProcessor())
.addUrl(url)
.setScheduler(new QueueScheduler().setDuplicateRemover(new BloomFilterDuplicateRemover(100000)))
.thread(10)
.addPipeline(pipeline)
.run();
}
}
这里面用到了一个 统计工资的工具类 MathSalary
public class MathSalary {
/**
* 获取薪水范围
*
* @param salaryStr
* @return
*/
public static Integer[] getSalary(String salaryStr) {
//声明存放薪水范围的数组
Integer[] salary = new Integer[2];
//"500/天"
//0.8-1.2万/月
//5-8千/月
//5-6万/年
String date = salaryStr.substring(salaryStr.length() - 1, salaryStr.length());
//如果是按天,则直接乘以240进行计算
if (!"月".equals(date) && !"年".equals(date)) {
salaryStr = salaryStr.substring(0, salaryStr.length() - 2);
salary[0] = salary[1] = str2Num(salaryStr, 240);
return salary;
}
String unit = salaryStr.substring(salaryStr.length() - 3, salaryStr.length() - 2);
String[] salarys = salaryStr.substring(0, salaryStr.length() - 3).split("-");
salary[0] = mathSalary(date, unit, salarys[0]);
salary[1] = mathSalary(date, unit, salarys[1]);
return salary;
}
//根据条件计算薪水
private static Integer mathSalary(String date, String unit, String salaryStr) {
Integer salary = 0;
//判断单位是否是万
if ("万".equals(unit)) {
//如果是万,薪水乘以10000
salary = str2Num(salaryStr, 10000);
} else {
//否则乘以1000
salary = str2Num(salaryStr, 1000);
}
//判断时间是否是月
if ("月".equals(date)) {
//如果是月,薪水乘以12
salary = str2Num(salary.toString(), 12);
}
return salary;
}
private static int str2Num(String salaryStr, int num) {
try {
// 把字符串转为小数,必须用Number接受,否则会有精度丢失的问题
Number result = Float.parseFloat(salaryStr) * num;
return result.intValue();
} catch (Exception e) {
}
return 0;
}
}
导出数据到数据库相关类 Pipeline
@Component
public class SpringDataPipeline implements Pipeline {
@Autowired
private JobInfoService jobInfoService;
@Override
public void process(ResultItems resultItems, Task task) {
// 获取我们封装好的招聘详情对象
JobInfo jobInfo = resultItems.get("jobInfo");
// 判断我们的数据是否不为空
if (jobInfo != null){
// 不为空就保存到数据库中
this.jobInfoService.save(jobInfo);
}
}
}
引导类 Application
@SpringBootApplication
@EnableScheduling// 开启定时任务
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class,args);
}
}
结果展示:
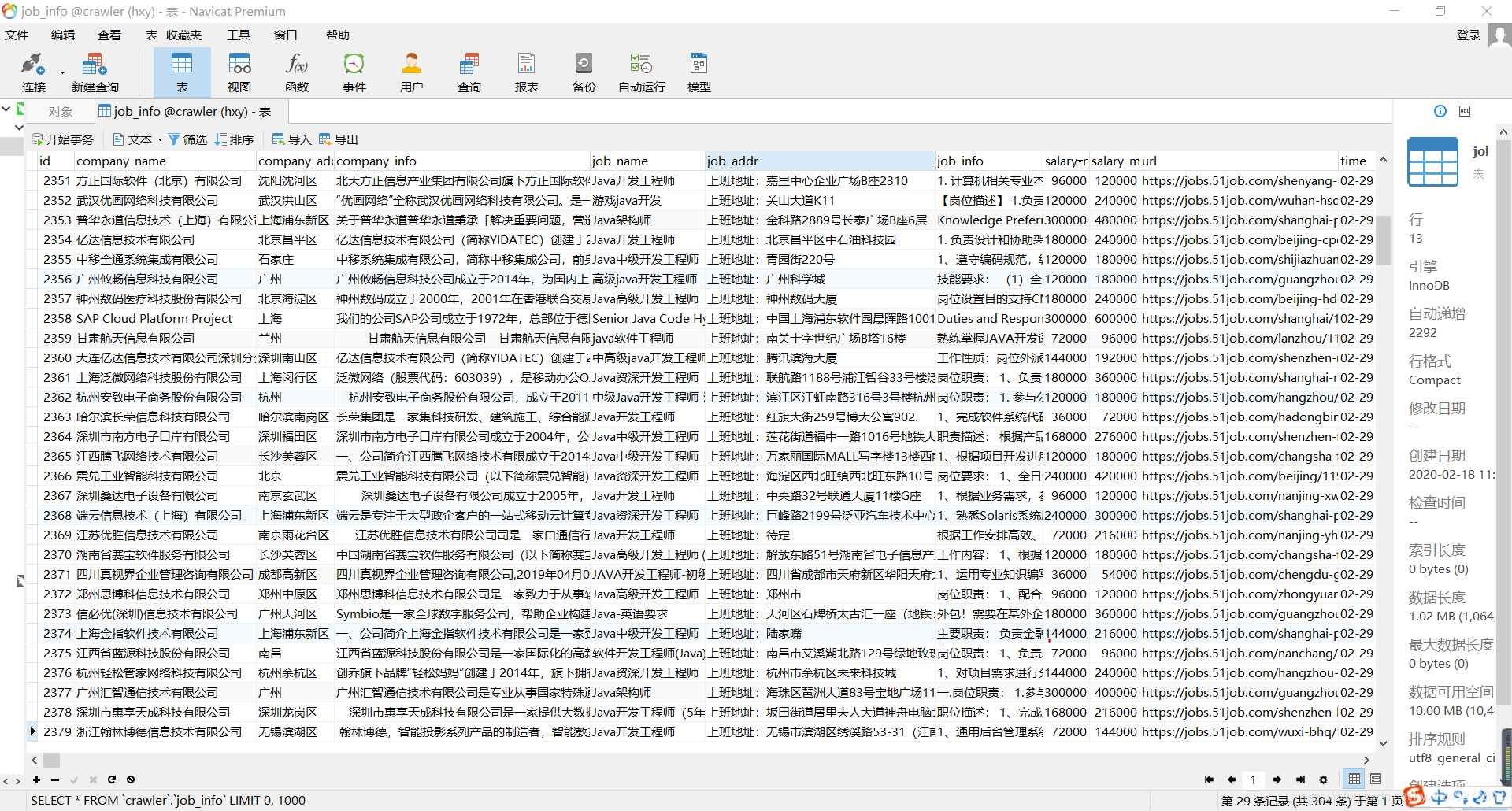
整理了以下,可能会出现以下问题,可自行修改
// String index out of range: -1: 存在部分字符串越界问题,应该是截取那里除了问题
// Data too long for column 'job_addr' at row 1: 数据库的字符集出错,将数据库数据类型换成了longtext 长度不用设置
// failed: connect timed out: 有可能是网络问题,网络不畅通会有超时的现象
// could not execute statement: 数据库中有字段不允许为空,而我们提交的数据中却没有提交该字段的值,就会造成这个异常。
Java 爬取 51job 数据 WebMagic实现的更多相关文章
- Java爬取51job保存到MySQL并进行分析
大二下实训课结业作业,想着就爬个工作信息,原本是要用python的,后面想想就用java试试看, java就自学了一个月左右,想要锻炼一下自己面向对象的思想等等的, 然后网上转了一圈,拉钩什么的是动态 ...
- Java爬取同花顺股票数据(附源码)
最近有小伙伴问我能不能抓取同花顺的数据,最近股票行情还不错,想把数据抓下来自己分析分析.我大A股,大家都知道的,一个概念火了,相应的股票就都大涨. 如果能及时获取股票涨跌信息,那就能在刚开始火起来的时 ...
- python之爬取网页数据总结(一)
今天尝试使用python,爬取网页数据.因为python是新安装好的,所以要正常运行爬取数据的代码需要提前安装插件.分别为requests Beautifulsoup4 lxml 三个插件 ...
- 利用linux curl爬取网站数据
看到一个看球网站的以下截图红色框数据,想爬取下来,通常爬取网站数据一般都会从java或者python爬取,但本人这两个都不会,只会shell脚本,于是硬着头皮试一下用shell爬取,方法很笨重,但旨在 ...
- 使用webdriver+urllib爬取网页数据(模拟登陆,过验证码)
urilib是python的标准库,当我们使用Python爬取网页数据时,往往用的是urllib模块,通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获得ur ...
- Java爬取校内论坛新帖
Java爬取校内论坛新帖 为了保持消息灵通,博主没事会上上校内论坛看看新帖,作为爬虫爱好者,博主萌生了写个爬虫自动下载的想法. 嗯,这次就选Java. 第三方库准备 Jsoup Jsoup是一款比较好 ...
- Python的scrapy之爬取51job网站的职位
今天老师讲解了Python中的爬虫框架--scrapy,然后带领我们做了一个小爬虫--爬取51job网的职位信息,并且保存到数据库中 用的是Python3.6 pycharm编辑器 爬虫主体: im ...
- Node.js爬取豆瓣数据
一直自以为自己vue还可以,一直自以为webpack还可以,今天在慕课逛node的时候,才发现,自己还差的很远.众所周知,vue-cli基于webpack,而webpack基于node,对node不了 ...
- MinerHtmlThread.java 爬取页面线程
MinerHtmlThread.java 爬取页面线程 package com.iteye.injavawetrust.miner; import org.apache.commons.logging ...
随机推荐
- 使用Hugo和GitHub搭建博客
折腾了几天博客的框架终于搭建起来了.研究了一番之后,最终还是选择使用Hugo和GitHub来搭建博客.本文介绍了如何使用Hugo来搭建静态博客网站,并将其部署在GitHub上.使用https://&l ...
- Docker与数据:三种挂载方式
操作系统与存储 操作系统中将存储定义为 Volume(卷) ,这是对物理存储的逻辑抽象,以达到对物理存储提供有弹性的分割方式.另外,将外部存储关联到操作系统的动作定义为 Mount(挂载). Dock ...
- Redis笔记(一)
redis:1.什么是缓存? mybatis一级缓存和二级缓存 mybatis的一级缓存存在哪? SqlSession,就不会再走数据库 什么情况下一级缓存会失效? 当被更新,删除的时候sqlsess ...
- ffmpeg命令 从网络摄像头录制视频
安装 sudo apt-get install ffmpeg 录制视频为record.mp4文件 ffmpeg -y -i rtsp://cameral_ip:port -vcodec copy -a ...
- 详细分析MySQL事务日志(undo log)
2.undo log 2.1 基本概念 undo log有两个作用:提供回滚和多个行版本控制(MVCC). 在数据修改的时候,不仅记录了redo,还记录了相对应的undo,如果因为某些原因导致事务失败 ...
- Docker私有镜像仓库Harbor
一.安装Harbor(离线安装包的方式安装) 1.解压离线包 2.进入harbor目录中编辑harbor.yml 3.安装docker-compose yum -y install docker-co ...
- Django中使用MySQL数据库的连接配置
1. 安装pymysql pip install pymysql 2. 导入 # 在与 settings.py 同级目录下的 __init__.py 中引入模块和进行配置 import pymysql ...
- JS020. Array map()函数查到需要的元素时跳出遍历循环,不再执行到数组边界
Array.prototype.map() map( ) 方法创建一个 新数组 *,其结果是该数组中的每个元素是调用一次提供的 函数后的返回值 *.[ MDN / RUNOOB ] * map 添加 ...
- Servlet生命周期和方法
一.五个生命周期方法,有三个很重要,初始化方法.提供服务方法和销毁方法 1.三个主要方法 2.另外两个重写的成员方法只做了解 二.生命周期详解 其中,每次刷新页面都是一次对servlet访问: 页面访 ...
- Markdown时序图--基础语法
时序图 序列图是一种交互图,它显示了流程以何种顺序相互操作. Mermaid可以渲染序列图,如下定义. sequenceDiagram Alice->>John:Message Hel ...