利用linux curl爬取网站数据
看到一个看球网站的以下截图红色框数据,想爬取下来,通常爬取网站数据一般都会从java或者python爬取,但本人这两个都不会,只会shell脚本,于是硬着头皮试一下用shell爬取,方法很笨重,但旨在结果嘛,呵呵。
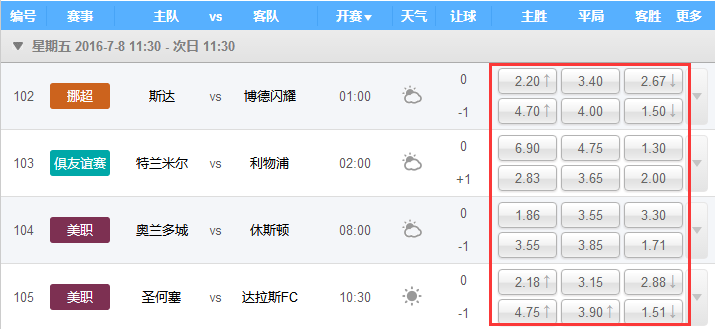
2.首先利用curl工具后者wget工具把整个网站数据爬取下来
curl 网址 >wangzhan.txt
3.查看wangzhan.txt文件,找出规则,看到数据是存放在哪个地方,本人是把txt文件拷到本机上用UE打开方便查看。通过查看文件,我发现数据是存储在“var automultiMatchList”与 “var setSingleMulti”这间的所有行,每个行后面的},结束代表一行:
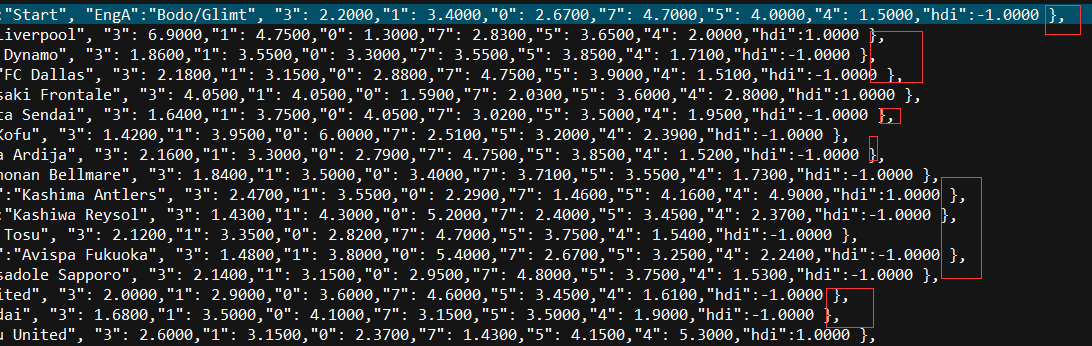
4. 截取所需的数据我是通过以下5个步骤

shell脚本分析:
(1)sed -n ‘/var automultiMatchList/,/var setSingleMulti/p‘ wangzhan.txt
这步是指从wangzhan.txt文件中查找到包含“var automultiMatchList”的行与包含“var setSingleMulti”的行之间的所有行:
 ···
···
···

(2)sed ‘$d‘ 是指删除最后一行的内容,因为这不是我们需要的数据。
(3)awk ‘NR<2‘ 是指把第一行取出来做特殊处理,因为第一行包含不要的数据(红色线框的内容)

(4)awk -F‘= {‘ ‘{print $2}‘ 是指通过 ={ 分隔域,输出$2就把上步红色线框的内容去掉了

(5)>1.txt 把第一行的数据输出到1.txt文件中
(6)第二条shell脚本中的awk ‘/[0-9]/{print $0}‘ 就是把最后的空行都去掉

去掉最后的空行变成:

(7)第二条shell脚本中的awk ‘NR>=2‘ >2.txt 是指把第二行及以下的所有行都输出到2.txt脚本
(8)awk 1 1.txt 2.txt>3.txt 这条命令是指把第一行和第二行及以下的所有行合并3.txt文件中,因为之前把第一行单独处理了,所以现在需要在合并到一块,相当于sql中union all。
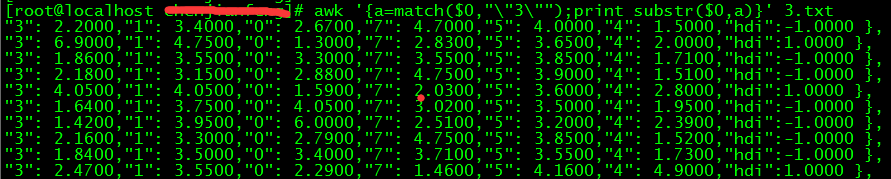
(9)awk ‘{a=match($0,"\"3\"");print substr($0,a)}‘ 3.txt 这条命令,因为通过wangzhan.txt文件发现,我们需要的内容都是在“3”这个字符之后:

这里用了awk的match和substr函数,就是找到“3”在这一行的所在位置之后,再截取需要的内容,这里不用过awk函数的同学可以复习一下awk函数。到这一步,我们要截取的数据的雏形就出来了。
(10)tr -d ‘ ‘ 是指把空格都去掉

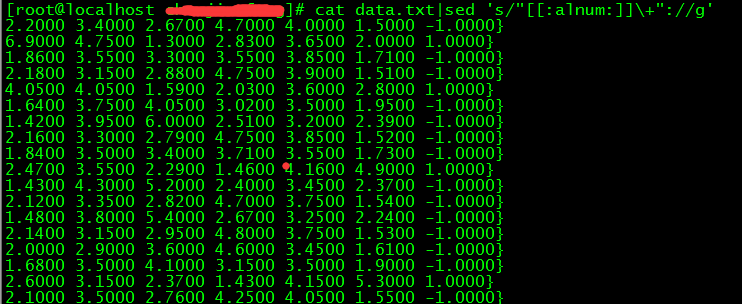
(11)awk -F‘,‘ ‘{print $1" "$2" "$3" "$4" "$5" "$6" "$7}‘>data.txt 是指通过逗号分隔域,然后再通过空格隔开:

(12)sed ‘s/"[[:alnum:]]\+"://g‘ 是指把冒号前面的数据都去掉,例如"3": 这种数据:
(13)awk ‘{print $1,$2,$3,$4,$5,$6}‘ 是指只打印我们需要的6个域:
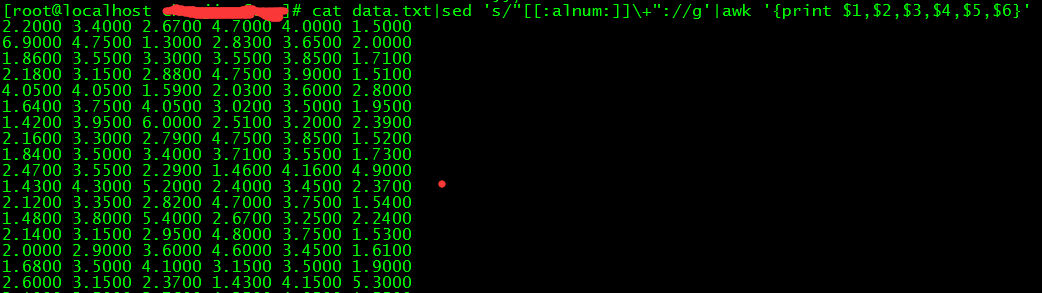
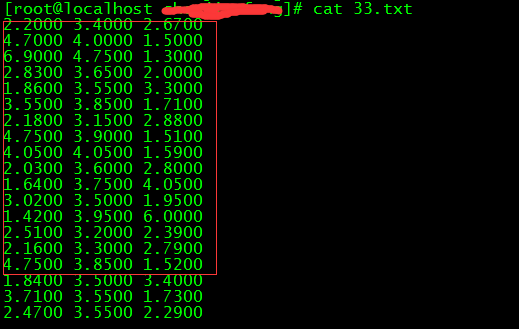
(14)xargs -n3 是指按照每3列输出,我们执行下第5条命令,然后33.txt的数据,就是我们要的数据:
总结:用shell爬取网站数据,需要熟悉sed,grep,awk等文本操作工具以及还运用到正则表达式,需要了解的内容比较多,比较繁琐复杂,
利用linux curl爬取网站数据的更多相关文章
- 利用phpspider爬取网站数据
本文实例原址:PHPspider爬虫10分钟快速教程 在我们的工作中可能会涉及到要到其它网站去进行数据爬取的情况,我们这里使用phpspider这个插件来进行功能实现. 1.首先,我们需要php环境, ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- 用curl抓取网站数据,仿造IP、防屏蔽终极强悍解决方式
最近在做一些抓取其它网站数据的工作,当然别人不会乖乖免费给你抓数据的,有各种防抓取的方法.不过道高一尺,魔高一丈,通过研究都是有漏洞可以钻的.下面的例子都是用PHP写的,不会用PHP来curl的孩纸先 ...
- python爬取网站数据保存使用的方法
这篇文章主要介绍了使用Python从网上爬取特定属性数据保存的方法,其中解决了编码问题和如何使用正则匹配数据的方法,详情看下文 编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这 ...
- C# 关于爬取网站数据遇到csrf-token的分析与解决
需求 某航空公司物流单信息查询,是一个post请求.通过后台模拟POST HTTP请求发现无法获取页面数据,通过查看航空公司网站后,发现网站使用避免CSRF攻击机制,直接发挥40X错误. 关于CSRF ...
- 手把手教你用Node.js爬虫爬取网站数据
个人网站 https://iiter.cn 程序员导航站 开业啦,欢迎各位观众姥爷赏脸参观,如有意见或建议希望能够不吝赐教! 开始之前请先确保自己安装了Node.js环境,还没有安装的的童鞋请自行百度 ...
- PHP用curl抓取网站数据,仿造IP、伪造来源等,防屏蔽解决方案教程
1.伪造客户端IP地址,伪造访问referer:(一般情况下这就可以访问到数据了) curl_setopt($curl, CURLOPT_HTTPHEADER, ['X-FORWARDED-FOR:1 ...
- 3.15学习总结(Python爬取网站数据并存入数据库)
在官网上下载了Python和PyCharm,并在网上简单的学习了爬虫的相关知识. 结对开发的第一阶段要求: 网上爬取最新疫情数据,并存入到MySql数据库中 在可视化显示数据详细信息 项目代码: im ...
- 利用Jsoup包爬取网站内容
一 Jsoup包 下载链接:http://download.csdn.net/detail/u014000832/7994245 二 爬取搜狐新闻网站标题等内容 package com.test1; ...
随机推荐
- 动态调用WebService(传对象返回接受对象)
基础属性//客户端代理服务命名空间,可以设置成需要的值. string ns = string.Format("WindowsForms"); private Assembly a ...
- SpringMVC Mybatis Spring
Spring MVC Mybatis整合过程中 Mapper.java 不需要使用 @componenet, Service 等spring注解 但是在service 中创建mapper对象的时候是需 ...
- squid 3.5 window x64
下载1: https://download.csdn.net/download/runliuv/11131620 下载2: 链接: https://pan.baidu.com/s/1A_o_Xvg1y ...
- 黄聪:原生js的音频播放器,兼容pc端和移动端(原创)
更新时间:2018/9/3 下午1:32:54 更新说明:添加音乐的loop设置和ended事件监听 loop为ture的时候不执行ended事件 1 2 3 4 5 6 7 8 9 10 11 12 ...
- 如何找出单链表中的倒数第k个元素
方法一:快慢指针法 在查找过程中,设置两个指针,初始时指向首元结点(第一个元素结点). 然后,让其中一个指针先前移k步. 然后两个指针再同时往前移动.当先行的指针值为NULL时,另一个指针所指的位置就 ...
- 对话框--pop&dialog总结
pinguo-zhouwei/CustomPopwindow:(通用PopupWindow,几行代码搞定PopupWindow弹窗(续)): 1,通用PopupWindow,几行代码搞定PopupWi ...
- S2-052 RCE漏洞 初步分析
PS:初步分析,只是分析了Struts2 REST插件的部分,本来菜的抠脚不敢发,但看到各大中心发的也没比我高到哪里去,索性发出来做个记事! 漏洞描述 2017年9月5日,Apache Struts发 ...
- LeetCode 789. Escape The Ghosts
题目链接:https://leetcode.com/problems/escape-the-ghosts/description/ You are playing a simplified Pacma ...
- tigervnc-server 无法启动问题
[root@moodle-bak .X11-unix]# vncserver WARNING: The first attempt to start Xvnc failed, possibly bec ...
- 棒槌的工作第11天-----------------------单词(select和epoll)
https://baike.baidu.com/item/epoll/10738144?fr=aladdin epoll百科 https://baike.baidu.com/item/select%2 ...