SuperPoint: Self-Supervised Interest Point Detection and Description 论文笔记
Introduction
这篇文章设计了一种自监督网络框架,能够同时提取特征点的位置以及描述子。相比于patch-based方法,本文提出的算法能够在原始图像提取到像素级精度的特征点的位置及其描述子。本文提出了一种单映性适应(Homographic Adaptation)的策略以增强特征点的复检率以及跨域的实用性(这里跨域指的是synthetic-to-real的能力,网络模型在虚拟数据集上训练完成,同样也可以在真实场景下表现优异的能力)。
SuperPoint Architecture
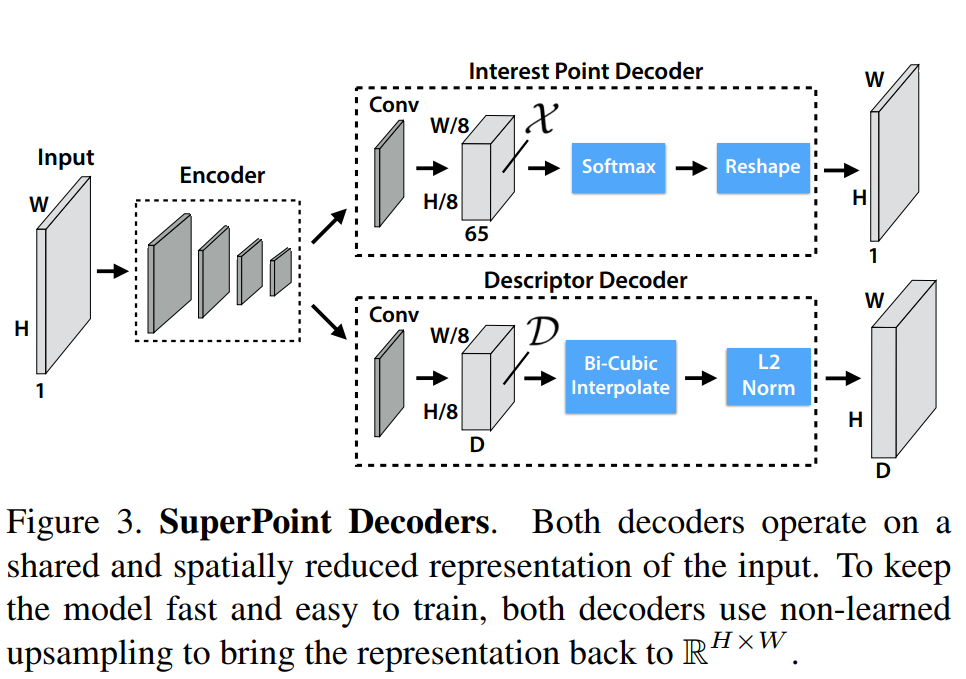
1 Shared Encoder
这是一个VGG-style的网络层,将原始输入图片进行一系列的处理后,将原始输入图片的尺寸变成\(H_c=H/8,W_c = W/8\)
2 Interest Point Decoder
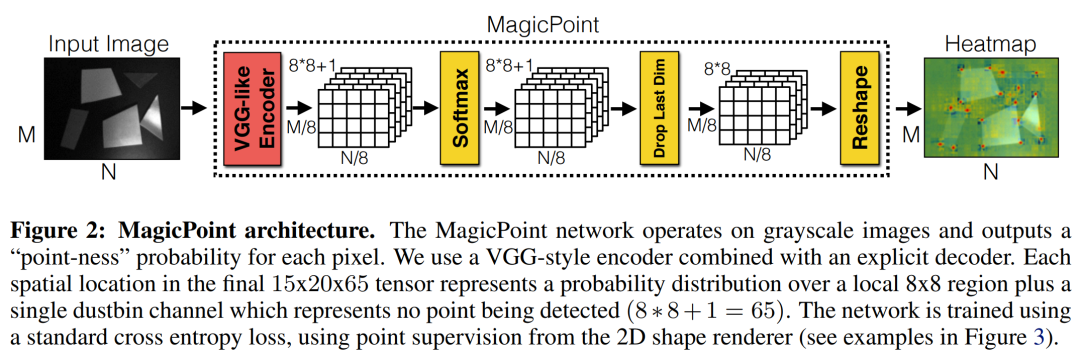
The 65 channels correspond to local, non-overlapping 8 × 8 grid regions of pixels plus an extra “no interest point” dustbin.
After a channel-wise softmax, the dustbin dimension is removed and a RH c ×W c ×64 ⇒ RH×W reshape is performed.
65个通道对应原始图片\(8\times 8\)的网格,加上一个非特征点dustbin,通过在channel维度上做softmax,非特征点dustbin会被删除,同时会做一步图像的reshape (使用的是一个叫做\(子像素卷积^{[1]}\)的方法),得到一个和输出图片size相同的概率图。
3 Descriptor Decoder
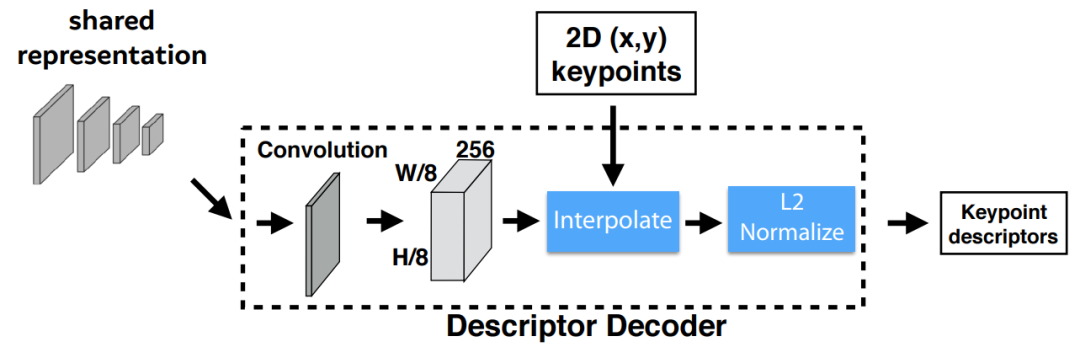
首先利用类似于UCN的网络得到一个半稠密的描述子(此处参考文献\(UCN^{[3]}\) ),这样可以减少算法 训练内存开销同时减少算法运行时间。之后通过双三次多项式揷值得到其余描述,然后通过 L2normalizes 归一化描述子得到统一的长度描述。特征维度由 \(\mathcal{D} \in \mathbb{R}^{H_{c} \times W_{c} \times D}\) 变为 \(\mathbb{R}^{H \times W \times D}\) 。
4 Loss Functions
可见损失函数由两项组成,其中一项为特征点检测loss\(\mathcal{L}_{p}\) ,另外一项是描述子的loss\(\mathcal{L}_{d}\)。
前者使用的是交叉熵误差函数:
The interest point detector loss function \(\mathcal{L}_{p}\) is a fully convolutional cross-entropy loss over the cells \(\mathbf{x}_{h w} \in \mathcal{X}\). We call the set of corresponding ground-truth interest point labels \(Y\) and individual entries as \(y_{h w}\). The loss is:
\]
where
\]
描述子的损失函数:
\]
where
l_{d}\left(\mathbf{d}, \mathbf{d}^{\prime} ; s\right)=\lambda_{d} * s * \max \left(0, m_{p}-\mathbf{d}^{T} \mathbf{d}^{\prime}\right) \\
+(1-s) * \max \left(0, \mathbf{d}^{T} \mathbf{d}^{\prime}-m_{n}\right)
\end{array}
\]
其中对应每个cell的s是这样定义的:
\]
Synthetic Pre-Training
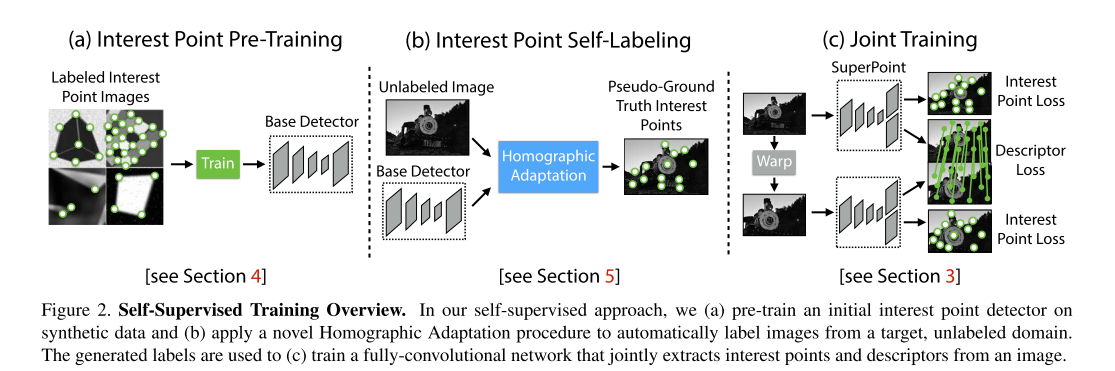
网络的训练分为三个步骤:
第一步是采用虚拟的三维物体作为数据集,训练网络去提取角点,这里得到的是
BaseDetector即MagicPoint使用真实场景图片(MS-CoCo),用第一步训练出来的网络
MagicPoint+Homographic Adaptation提取角点,这一步称作兴趣点自标注(Interest Point Self-Labeling)对第二步使用的图片进行几何变换得到新的图片,这样就有了已知位姿关系的图片对,把这两张图片输入SuperPoint网络,提取特征点和描述子,然后计算loss,进行训练。
这里重点介绍一下Homographic Adaptation
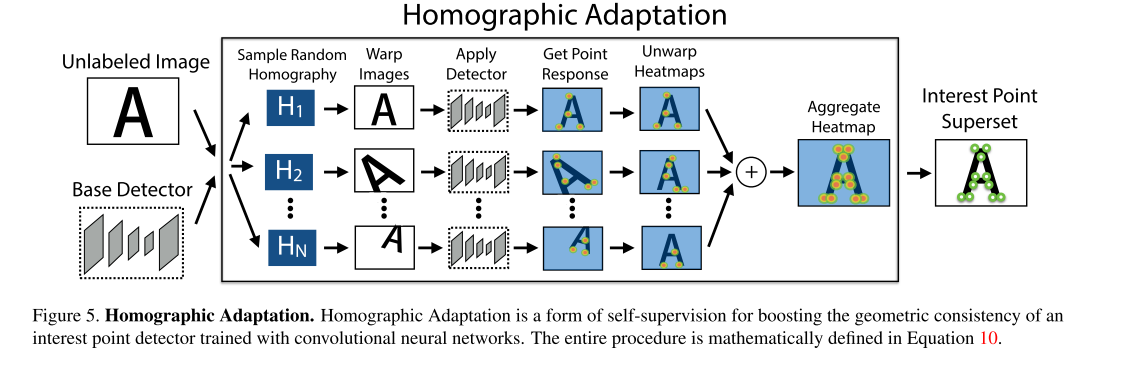
针对Magicpoint在真实数据上的缺点,作者提出了Homographic Adaptation,也就是把真实图片做几次单应变换,将这些单应变换的结果都输入Magicpoint,然后将检测到的特征点投影到原始的图片上,合起来作为最后的特征点真值。这样使检测到的特征点更丰富,也具备了一定的单应不变性。然后将通过这个步骤得到的图片结合原图片送入到SuperPoint进行训练。
Running
观察到论文的作者在GitHub上开源了SuperPoint的\(代码^{[2]}\),拉下来跑了一下。
| input | output |
|---|---|
 |
 |
 |
 |
真的牛!!!!
Conclusion
作者先使用一个合成的数据集训练MagicPoint,然后再结合Homographic Adaptation使其在真实世界里的表现得到了提升。同时特征点的检测也可以使用深度学习的方法来解决了。并且取得了较传统的方法很大的性能提升。
Refer
[1]子像素卷积:https://blog.csdn.net/leviopku/article/details/84975282
[2]superpoint:https://github.com/magicleap/SuperPointPretrainedNetwork
[3]C. B. Choy, J. Gwak, S. Savarese, and M. Chandraker. Universal Correspondence Network. In NIPS. 2016.2, 3, 8
SuperPoint: Self-Supervised Interest Point Detection and Description 论文笔记的更多相关文章
- Learning Rich Features from RGB-D Images for Object Detection and Segmentation论文笔记
相关工作: 将R-CNN推广到RGB-D图像,引入一种新的编码方式来捕获图像中像素的地心姿态,并且这种新的编码方式比单纯使用深度通道有了明显的改进. 我们建议在每个像素上用三个通道编码深度图像:水平视 ...
- 【论文笔记】Malware Detection with Deep Neural Network Using Process Behavior
[论文笔记]Malware Detection with Deep Neural Network Using Process Behavior 论文基本信息 会议: IEEE(2016 IEEE 40 ...
- 论文笔记《Spatial Memory for Context Reasoning in Object Detection》
好久不写论文笔记了,不是没看,而是很少看到好的或者说值得记的了,今天被xinlei这篇paper炸了出来,这篇被据老大说xinlei自称idea of the year,所以看的时候还是很认真的,然后 ...
- [CVPR 2016] Weakly Supervised Deep Detection Networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #323333 } p. ...
- 论文笔记:Chaotic Invariants of Lagrangian Particle Trajectories for Anomaly Detection in Crowded Scenes
[原创]Liu_LongPo 转载请注明出处 [CSDN]http://blog.csdn.net/llp1992 近期在关注 crowd scene方面的东西.由于某些原因须要在crowd scen ...
- [CVPR2017] Weakly Supervised Cascaded Convolutional Networks论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px "Helvetica Neue"; color: #042eee } p. ...
- [Arxiv1706] Few-Example Object Detection with Model Communication 论文笔记
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px "Helvetica Neue"; color: #042eee } p. ...
- 论文笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
在上计算机视觉这门课的时候,老师曾经留过一个作业:识别一张 A4 纸上的手写数字.按照传统的做法,这种手写体或者验证码识别的项目,都是按照定位+分割+识别的套路.但凡上网搜一下,就能找到一堆识别的教程 ...
- 论文笔记之:Learning Cross-Modal Deep Representations for Robust Pedestrian Detection
Learning Cross-Modal Deep Representations for Robust Pedestrian Detection 2017-04-11 19:40:22 Moti ...
随机推荐
- 【LeetCode】693. Binary Number with Alternating Bits 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 遍历判断 判断是否是交替模式 位运算 日期 题目地址 ...
- 【LeetCode】503. Next Greater Element II 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 暴力解法 单调递减栈 日期 题目地址:https:/ ...
- 【剑指Offer】栈的压入、弹出队列 解题报告(Python)
[剑指Offer]栈的压入.弹出队列 解题报告(Python) 标签(空格分隔): 剑指Offer 题目地址:https://www.nowcoder.com/ta/coding-interviews ...
- codeforces626D . Jerry's Protest
Andrew and Jerry are playing a game with Harry as the scorekeeper. The game consists of three rounds ...
- 问题--ImportError: DLL load failed: 找不到指定的模块
今天在运行别人的项目时出现了问题: ImportError: DLL load failed: 找不到指定的模块. 解决方法: 卸载后重新安装. 详情参考: Python报错:ImportError: ...
- 分割字符串StringTokenizer
StringTokenizer 原来是一个遗留类,并未被废弃,只是出于兼容性原因而被保留,在新代码中已经不鼓励使用它了,建议使用 String 的 split 方法或 java.util.regex ...
- Java初学者作业——分析计费规则后,编写程序输入乘坐出租车的时间和里程数,计算里程价格
返回本章节 返回作业目录 需求说明: 某城市的出租车计费规则如下: 在 7:00 - 23:00 之间,3km 以内收取起步价 10 元,超过 3km 每 km 收取 2 元. 如果不在这个时间段,在 ...
- JavaScript交互式网页设计 • 【第8章 jQuery动画与特效】
全部章节 >>>> 本章目录 8.1 显示隐藏动画效果 8.1.1 show() 方法与hide() 方法 8.1.2 toggle()方法 8.1.3 实践练习 8.2 ...
- UML 基本模型元素
目录 1. 结构模型元素 (1)类(class) (2)接口(interface) (3)协作(collaboration) (4)用例(use case) (5)活动类(active class) ...
- C# .net 环境下使用rabbitmq消息队列
消息队列的地位越来越重要,几乎是面试的必问问题了,不会使用几种消息队列都显得尴尬,正好本文使用C#来带你认识rabbitmq消息队列 首先,我们要安装rabbitmq,当然,如果有现成的,也可以使用, ...