吴恩达深度学习课后习题第5课第1周第3小节: Jazz Improvisation with LSTM
- Improvise a Jazz Solo with an LSTM Network
- Packages
- 1 - Problem Statement
- Overview of Section 2 and 3
- Exercise 1 - djmodel
- Inputs (given)
- Step 2: Loop through time steps
- 2A. Select the 't' time-step vector from X.
- 2B. Reshape x to be (1, n_values).
- 2C. Run x through one step of LSTM_cell.
- 2D. Dense layer
- 2E. Append output
- Step 3: After the loop, create the model
- Create the model object
- Compile the model for training
- Initialize hidden state and cell state
- Train the model
- Expected Output
- Exercise 1 - djmodel
- 3 - Generating Music
- Congratulations!
Improvise a Jazz Solo with an LSTM Network
Welcome to your final programming assignment of this week! In this notebook, you will implement a model that uses an LSTM to generate music. At the end, you'll even be able to listen to your own music!

By the end of this assignment, you'll be able to:
- Apply an LSTM to a music generation task
- Generate your own jazz music with deep learning
- Use the flexible Functional API to create complex models
This is going to be a fun one. Let's get started!
Packages
Run the following cell to load all the packages you'll need. This may take a few minutes!
import IPython
import sys
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from music21 import *
from grammar import *
from qa import *
from preprocess import *
from music_utils import *
from data_utils import *
from outputs import *
from test_utils import *
from tensorflow.keras.layers import Dense, Activation, Dropout, Input, LSTM, Reshape, Lambda, RepeatVector
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.utils import to_categorical
1 - Problem Statement
You would like to create a jazz music piece specially for a friend's birthday. However, you don't know how to play any instruments, or how to compose music. Fortunately, you know deep learning and will solve this problem using an LSTM network!
You will train a network to generate novel jazz solos in a style representative of a body of performed work.
1.1 - Dataset
To get started, you'll train your algorithm on a corpus of Jazz music. Run the cell below to listen to a snippet of the audio from the training set:
IPython.display.Audio('./data/30s_seq.wav')
The preprocessing of the musical data has been taken care of already, which for this notebook means it's been rendered in terms of musical "values."
What are musical "values"? (optional)
You can informally think of each "value" as a note, which comprises a pitch and duration. For example, if you press down a specific piano key for 0.5 seconds, then you have just played a note. In music theory, a "value" is actually more complicated than this -- specifically, it also captures the information needed to play multiple notes at the same time. For example, when playing a music piece, you might press down two piano keys at the same time (playing multiple notes at the same time generates what's called a "chord"). But you don't need to worry about the details of music theory for this assignment.
Music as a sequence of values
- For the purposes of this assignment, all you need to know is that you'll obtain a dataset of values, and will use an RNN model to generate sequences of values.
- Your music generation system will use 90 unique values.
Run the following code to load the raw music data and preprocess it into values. This might take a few minutes!
X, Y, n_values, indices_values, chords = load_music_utils('data/original_metheny.mid')
print('number of training examples:', X.shape[0])
print('Tx (length of sequence):', X.shape[1])
print('total # of unique values:', n_values)
print('shape of X:', X.shape)
print('Shape of Y:', Y.shape)
print('Number of chords', len(chords))
You have just loaded the following:
X: This is an (m, **T_x **, 90) dimensional array.- You have m training examples, each of which is a snippet of **T_x =30 ** musical values.
- At each time step, the input is one of 90 different possible values, represented as a one-hot vector.
- For example, X[i,t,:] is a one-hot vector representing the value of the i-th example at time t.
Y: a **(T_y, m, 90) ** dimensional array- This is essentially the same as
X, but shifted one step to the left (to the past). - Notice that the data in
Yis reordered to be dimension **(T_y, m, 90) **, where T_y = T_x. This format makes it more convenient to feed into the LSTM later. - Similar to the dinosaur assignment, you're using the previous values to predict the next value.
- So your sequence model will try to predict \(y^{\langle t \rangle}\) given \(x^{\langle 1\rangle}, \ldots, x^{\langle t \rangle}\).
- This is essentially the same as
n_values: The number of unique values in this dataset. This should be 90.indices_values: python dictionary mapping integers 0 through 89 to musical values.chords: Chords used in the input midi
a name='1-2'>
1.2 - Model Overview
Here is the architecture of the model you'll use. It's similar to the Dinosaurus model, except that you'll implement it in Keras.
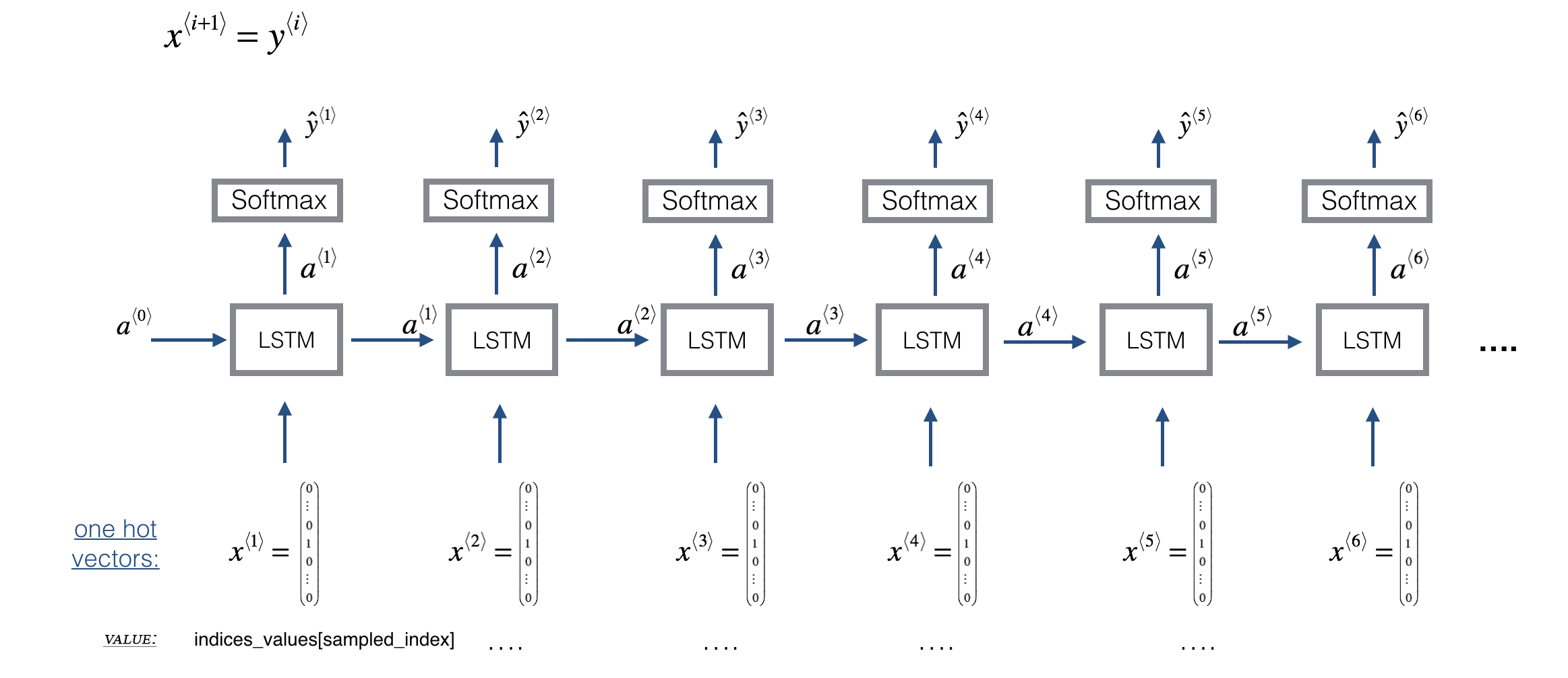
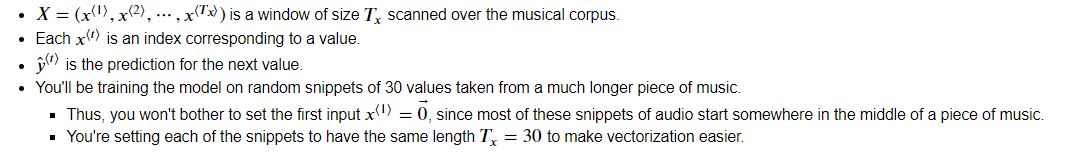
Overview of Section 2 and 3
In Section 2, you're going to train a model that predicts the next note in a style similar to the jazz music it's trained on. The training is contained in the weights and biases of the model.
Then, in Section 3, you're going to use those weights and biases in a new model that predicts a series of notes, and using the previous note to predict the next note.
- The weights and biases are transferred to the new model using the global shared layers (
LSTM_cell,densor,reshaper) described below
# number of dimensions for the hidden state of each LSTM cell.
n_a = 64
Sequence generation uses a for-loop
- If you're building an RNN where, at test time, the entire input sequence \(x^{\langle 1 \rangle}, x^{\langle 2 \rangle}, \ldots, x^{\langle T_x \rangle}\) is given in advance, then Keras has simple built-in functions to build the model.
- However, for sequence generation, at test time you won't know all the values of \(x^{\langle t\rangle}\) in advance.
- Instead, you'll generate them one at a time using \(x^{\langle t\rangle} = y^{\langle t-1 \rangle}\).
- The input at time "t" is the prediction at the previous time step "t-1".
- So you'll need to implement your own for-loop to iterate over the time steps.
Shareable weights
- The function
djmodel()will call the LSTM layer \(T_x\) times using a for-loop. - It is important that all \(T_x\) copies have the same weights.
- The \(T_x\) steps should have shared weights that aren't re-initialized.
- Referencing a globally defined shared layer will utilize the same layer-object instance at each time step.
- The key steps for implementing layers with shareable weights in Keras are:
- Define the layer objects (you'll use global variables for this).
- Call these objects when propagating the input.
3 types of layers
- The layer objects you need for global variables have been defined.
- Just run the next cell to create them!
- Please read the Keras documentation and understand these layers:
n_values = 90 # number of music values
reshaper = Reshape((1, n_values)) # Used in Step 2.B of djmodel(), below
LSTM_cell = LSTM(n_a, return_state = True) # Used in Step 2.C
densor = Dense(n_values, activation='softmax') # Used in Step 2.D
reshaper,LSTM_cellanddensorare globally defined layer objects that you'll use to implementdjmodel().- In order to propagate a Keras tensor object X through one of these layers, use
layer_object().- For one input, use
layer_object(X) - For more than one input, put the inputs in a list:
layer_object([X1,X2])
- For one input, use
Exercise 1 - djmodel
Implement djmodel().
Inputs (given)
- The
Input()layer is used for defining the inputXas well as the initial hidden state 'a0' and cell statec0. - The
shapeparameter takes a tuple that does not include the batch dimension (m).- For example,
X = Input(shape=(Tx, n_values)) # X has 3 dimensions and not 2: (m, Tx, n_values)
Step 1: Outputs
- Create an empty list "outputs" to save the outputs of the LSTM Cell at every time step.
Step 2: Loop through time steps
- Loop for \(t \in 1, \ldots, T_x\):
2A. Select the 't' time-step vector from X.
- X has the shape (m, Tx, n_values).
- The shape of the 't' selection should be (n_values,).
- Recall that if you were implementing in numpy instead of Keras, you would extract a slice from a 3D numpy array like this:
var1 = array1[:,1,:]
2B. Reshape x to be (1, n_values).
- Use the
reshaper()layer. This is a function that takes the previous layer as its input argument.
2C. Run x through one step of LSTM_cell.
- Initialize the
LSTM_cellwith the previous step's hidden state \(a\) and cell state \(c\). - Use the following formatting:
next_hidden_state, _, next_cell_state = LSTM_cell(inputs=input_x, initial_state=[previous_hidden_state, previous_cell_state])
* Choose appropriate variables for inputs, hidden state and cell state.
2D. Dense layer
- Propagate the LSTM's hidden state through a dense+softmax layer using
densor.
2E. Append output
- Append the output to the list of "outputs".
Step 3: After the loop, create the model
Use the Keras
Modelobject to create a model. There are two ways to instantiate theModelobject. One is by subclassing, which you won't use here. Instead, you'll use the highly flexible Functional API, which you may remember from an earlier assignment in this course! With the Functional API, you'll start from your Input, then specify the model's forward pass with chained layer calls, and finally create the model from inputs and outputs.Specify the inputs and output like so:
model = Model(inputs=[input_x, initial_hidden_state, initial_cell_state], outputs=the_outputs)
* Then, choose the appropriate variables for the input tensor, hidden state, cell state, and output.
- See the documentation for Model
# UNQ_C1 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)
# GRADED FUNCTION: djmodel
def djmodel(Tx, LSTM_cell, densor, reshaper):
"""
Implement the djmodel composed of Tx LSTM cells where each cell is responsible
for learning the following note based on the previous note and context.
Each cell has the following schema:
[X_{t}, a_{t-1}, c0_{t-1}] -> RESHAPE() -> LSTM() -> DENSE()
Arguments:
Tx -- length of the sequences in the corpus
LSTM_cell -- LSTM layer instance
densor -- Dense layer instance
reshaper -- Reshape layer instance
Returns:
model -- a keras instance model with inputs [X, a0, c0]
"""
# Get the shape of input values
n_values = densor.units
# Get the number of the hidden state vector
n_a = LSTM_cell.units
# Define the input layer and specify the shape
X = Input(shape=(Tx, n_values))
# Define the initial hidden state a0 and initial cell state c0
# using `Input`
a0 = Input(shape=(n_a,), name='a0')
c0 = Input(shape=(n_a,), name='c0')
a = a0
c = c0
### START CODE HERE ###
# Step 1: Create empty list to append the outputs while you iterate (≈1 line)
outputs =[]
# Step 2: Loop over tx
for t in range(Tx):
# Step 2.A: select the "t"th time step vector from X.
x = X[:,t,:]
# Step 2.B: Use reshaper to reshape x to be (1, n_values) (≈1 line)
x = reshaper(x)
# Step 2.C: Perform one step of the LSTM_cell
a, _, c = LSTM_cell(inputs=x,initial_state=[a,c])
# Step 2.D: Apply densor to the hidden state output of LSTM_Cell
out = densor(a)
# Step 2.E: add the output to "outputs"
outputs.append(out)
# Step 3: Create model instance
model = Model(inputs=[X, a0, c0], outputs=outputs)
### END CODE HERE ###
return model
Create the model object
- Run the following cell to define your model.
- We will use
Tx=30. - This cell may take a few seconds to run.
model = djmodel(Tx=30, LSTM_cell=LSTM_cell, densor=densor, reshaper=reshaper)
# UNIT TEST
output = summary(model)
comparator(output, djmodel_out)
model.summary()
Expected Output
Scroll to the bottom of the output, and you'll see the following:
Total params: 45,530
Trainable params: 45,530
Non-trainable params: 0
Compile the model for training
- You now need to compile your model to be trained.
- We will use:
- optimizer: Adam optimizer
- Loss function: categorical cross-entropy (for multi-class classification)
opt = Adam(lr=0.01, beta_1=0.9, beta_2=0.999, decay=0.01)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
Initialize hidden state and cell state
Finally, let's initialize a0 and c0 for the LSTM's initial state to be zero.
m = 60
a0 = np.zeros((m, n_a))
c0 = np.zeros((m, n_a))
Train the model
You're now ready to fit the model!
- You'll turn
Yinto a list, since the cost function expectsYto be provided in this format.list(Y)is a list with 30 items, where each of the list items is of shape (60,90).- Train for 100 epochs (This will take a few minutes).
history = model.fit([X, a0, c0], list(Y), epochs=100, verbose = 0)
print(f"loss at epoch 1: {history.history['loss'][0]}")
print(f"loss at epoch 100: {history.history['loss'][99]}")
plt.plot(history.history['loss'])
Expected Output
The model loss will start high, (100 or so), and after 100 epochs, it should be in the single digits. These won't be the exact number that you'll see, due to random initialization of weights.
For example:
loss at epoch 1: 129.88641357421875
...
Scroll to the bottom to check Epoch 100
loss at epoch 100: 9.21483039855957
Now that you have trained a model, let's go to the final section to implement an inference algorithm, and generate some music!
3 - Generating Music
You now have a trained model which has learned the patterns of a jazz soloist. You can now use this model to synthesize new music!
3.1 - Predicting & Sampling
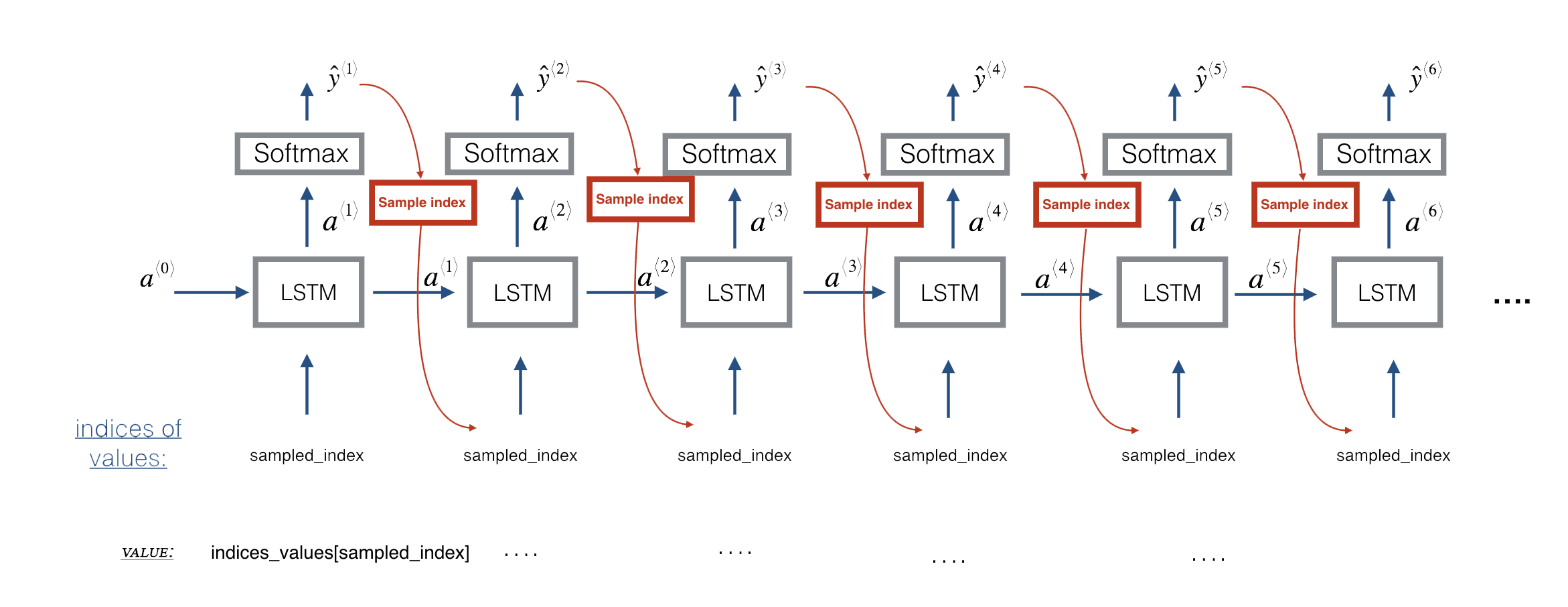
At each step of sampling, you will:
- Take as input the activation '
a' and cell state 'c' from the previous state of the LSTM. - Forward propagate by one step.
- Get a new output activation, as well as cell state.
- The new activation '
a' can then be used to generate the output using the fully connected layer,densor.
Initialization
- You'll initialize the following to be zeros:
x0- hidden state
a0 - cell state
c0
Exercise 2 - music_inference_model
Implement music_inference_model() to sample a sequence of musical values.
Here are some of the key steps you'll need to implement inside the for-loop that generates the \(T_y\) output characters:
Step 1: Create an empty list "outputs" to save the outputs of the LSTM Cell at every time step.
Step 2.A: Use LSTM_Cell, which takes in the input layer, as well as the previous step's 'c' and 'a' to generate the current step's 'c' and 'a'.
next_hidden_state, _, next_cell_state = LSTM_cell(input_x, initial_state=[previous_hidden_state, previous_cell_state])
- Choose the appropriate variables for
input_x,hidden_state, andcell_state
2.B: Compute the output by applying densor to compute a softmax on 'a' to get the output for the current step.
2.C: Append the output to the list outputs.
2.D: Convert the last output into a new input for the next time step. You will do this in 2 substeps:
- Get the index of the maximum value of the predicted output using tf.math.argmax along the last axis.
- Convert the index into its n_values-one-hot encoding using tf.one_hot.
2.E: Use RepeatVector(1)(x) to convert the output of the one-hot enconding with shape=(None, 90) into a tensor with shape=(None, 1, 90)
Step 3: Inference Model:
This is how to use the Keras Model object:
model = Model(inputs=[input_x, initial_hidden_state, initial_cell_state], outputs=the_outputs)
- Choose the appropriate variables for the input tensor, hidden state, cell state, and output.
Hint: the inputs to the model are the initial inputs and states.
# UNQ_C2 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)
# GRADED FUNCTION: music_inference_model
def music_inference_model(LSTM_cell, densor,Ty=100):
"""
Uses the trained "LSTM_cell" and "densor" from model() to generate a sequence of values.
Arguments:
LSTM_cell -- the trained "LSTM_cell" from model(), Keras layer object
densor -- the trained "densor" from model(), Keras layer object
Ty -- integer, number of time steps to generate
Returns:
inference_model -- Keras model instance
"""
# Get the shape of input values
n_values = densor.units
# Get the number of the hidden state vector
n_a = LSTM_cell.units
# Define the input of your model with a shape
x0 = Input(shape=(1, n_values))
# Define s0, initial hidden state for the decoder LSTM
a0 = Input(shape=(n_a,), name='a0')
c0 = Input(shape=(n_a,), name='c0')
a = a0
c = c0
x = x0
### START CODE HERE ###
# Step 1: Create an empty list of "outputs" to later store your predicted values (≈1 line)
outputs = []
# Step 2: Loop over Ty and generate a value at every time step
for t in range(Ty):
# Step 2.A: Perform one step of LSTM_cell. Use "x", not "x0" (≈1 line)
a, _, c = LSTM_cell(x,initial_state=[a,c])
# Step 2.B: Apply Dense layer to the hidden state output of the LSTM_cell (≈1 line)
out = densor(a)
# print(out.shape)
# Step 2.C: Append the prediction "out" to "outputs". out.shape = (None, 90) (≈1 line)
outputs.append(out)
# print(out.shape)
# Step 2.D:
# Select the next value according to "out",
# Set "x" to be the one-hot representation of the selected value
# See instructions above.
x = tf.math.argmax(out,axis=1)#注意axis,重要
x = tf.one_hot(x,depth=n_values)#depth重要
print(x.shape)
# Step 2.E:
# Use RepeatVector(1) to convert x into a tensor with shape=(None, 1, 90)
x = RepeatVector(1)(x)
print(x.shape)
#x=Lambda(one_hot)(out)
# Step 3: Create model instance with the correct "inputs" and "outputs" (≈1 line)
inference_model = Model([x0,a0,c0],outputs)
return inference_model
Run the cell below to define your inference model. This model is hard coded to generate 50 values.
inference_model = music_inference_model(LSTM_cell, densor, Ty = 50)
Initialize inference model
The following code creates the zero-valued vectors you will use to initialize x and the LSTM state variables a and c.
x_initializer = np.zeros((1, 1, n_values))
a_initializer = np.zeros((1, n_a))
c_initializer = np.zeros((1, n_a))
Exercise 3 - predict_and_sample
Implement predict_and_sample().
This function takes many arguments, including the inputs x_initializer, a_initializer, and c_initializer.
In order to predict the output corresponding to this input, you'll need to carry out 3 steps:
Step 1:
- Use your inference model to predict an output given your set of inputs. The output
predshould be a list of length \(T_y\) where each element is a numpy-array of shape (1, n_values).
inference_model.predict([input_x_init, hidden_state_init, cell_state_init])
* Choose the appropriate input arguments to `predict` from the input arguments of this `predict_and_sample` function.
Step 2:
- Convert
predinto a numpy array of \(T_y\) indices.- Each index is computed by taking the
argmaxof an element of thepredlist. - Use numpy.argmax.
- Set the
axisparameter.- Remember that the shape of the prediction is \((m, T_{y}, n_{values})\)
- Each index is computed by taking the
Step 3:
- Convert the indices into their one-hot vector representations.
- Use to_categorical.
- Set the
num_classesparameter. Note that for grading purposes: you'll need to either:- Use a dimension from the given parameters of
predict_and_sample()(for example, one of the dimensions of x_initializer has the value for the number of distinct classes). - Or just hard code the number of distinct classes (will pass the grader as well).
- Note that using a global variable such as
n_valueswill not work for grading purposes.
- Use a dimension from the given parameters of
# UNQ_C3 (UNIQUE CELL IDENTIFIER, DO NOT EDIT)
# GRADED FUNCTION: predict_and_sample
def predict_and_sample(inference_model, x_initializer = x_initializer, a_initializer = a_initializer,
c_initializer = c_initializer):
"""
Predicts the next value of values using the inference model.
Arguments:
inference_model -- Keras model instance for inference time
x_initializer -- numpy array of shape (1, 1, 90), one-hot vector initializing the values generation
a_initializer -- numpy array of shape (1, n_a), initializing the hidden state of the LSTM_cell
c_initializer -- numpy array of shape (1, n_a), initializing the cell state of the LSTM_cel
Returns:
results -- numpy-array of shape (Ty, 90), matrix of one-hot vectors representing the values generated
indices -- numpy-array of shape (Ty, 1), matrix of indices representing the values generated
"""
n_values = x_initializer.shape[2]
### START CODE HERE ###
# Step 1: Use your inference model to predict an output sequence given x_initializer, a_initializer and c_initializer.
pred = inference_model.predict([x_initializer, a_initializer, c_initializer])
print("1")
# Step 2: Convert "pred" into an np.array() of indices with the maximum probabilities
indices = np.argmax(pred,axis=2)
print("2")
# Step 3: Convert indices to one-hot vectors, the shape of the results should be (Ty, n_values)
results = to_categorical(indices, num_classes=n_values)
print("3")
### END CODE HERE ###
return results, indices
then test
results, indices = predict_and_sample(inference_model, x_initializer, a_initializer, c_initializer)
print("np.argmax(results[12]) =", np.argmax(results[12]))
print("np.argmax(results[17]) =", np.argmax(results[17]))
print("list(indices[12:18]) =", list(indices[12:18]))
Expected (Approximate) Output:
- Your results may likely differ because Keras' results are not completely predictable.
- However, if you have trained your LSTM_cell with model.fit() for exactly 100 epochs as described above:
- You should very likely observe a sequence of indices that are not all identical. Perhaps with the following values:
| **np.argmax(results[12])** = | 26 |
| **np.argmax(results[17])** = | 7 |
| **list(indices[12:18])** = | [array([26]), array([18]), array([53]), array([27]), array([40]), array([7])] |
3.2 - Generate Music
Finally! You're ready to generate music.
Your RNN generates a sequence of values. The following code generates music by first calling your predict_and_sample() function. These values are then post-processed into musical chords (meaning that multiple values or notes can be played at the same time).
Most computational music algorithms use some post-processing because it's difficult to generate music that sounds good without it. The post-processing does things like clean up the generated audio by making sure the same sound is not repeated too many times, or that two successive notes are not too far from each other in pitch, and so on.
One could argue that a lot of these post-processing steps are hacks; also, a lot of the music generation literature has also focused on hand-crafting post-processors, and a lot of the output quality depends on the quality of the post-processing and not just the quality of the model. But this post-processing does make a huge difference, so you should use it in your implementation as well.
Let's make some music!
Run the following cell to generate music and record it into your out_stream. This can take a couple of minutes.
out_stream = generate_music(inference_model, indices_values, chords)
mid2wav('output/my_music.midi')
IPython.display.Audio('./output/rendered.wav')
To listen to your music, click File->Open... Then go to "output/" and download "my_music.midi". Either play it on your computer with an application that can read midi files if you have one, or use one of the free online "MIDI to mp3" conversion tools to convert this to mp3.
As a reference, here is a 30 second audio clip generated using this algorithm:
IPython.display.Audio('./data/30s_trained_model.wav')
Congratulations!
You've completed this assignment, and generated your own jazz solo! The Coltranes would be proud.
By now, you've:
- Applied an LSTM to a music generation task
- Generated your own jazz music with deep learning
- Used the flexible Functional API to create a more complex model
This was a lengthy task. You should be proud of your hard work, and hopefully you have some good music to show for it. Cheers and see you next time!
吴恩达深度学习课后习题第5课第1周第3小节: Jazz Improvisation with LSTM的更多相关文章
- 【Deeplearning.ai 】吴恩达深度学习笔记及课后作业目录
吴恩达深度学习课程的课堂笔记以及课后作业 代码下载:https://github.com/douzujun/Deep-Learning-Coursera 吴恩达推荐笔记:https://mp.weix ...
- 吴恩达深度学习第4课第3周编程作业 + PIL + Python3 + Anaconda环境 + Ubuntu + 导入PIL报错的解决
问题描述: 做吴恩达深度学习第4课第3周编程作业时导入PIL包报错. 我的环境: 已经安装了Tensorflow GPU 版本 Python3 Anaconda 解决办法: 安装pillow模块,而不 ...
- 吴恩达深度学习第2课第2周编程作业 的坑(Optimization Methods)
我python2.7, 做吴恩达深度学习第2课第2周编程作业 Optimization Methods 时有2个坑: 第一坑 需将辅助文件 opt_utils.py 的 nitialize_param ...
- 吴恩达深度学习第1课第4周-任意层人工神经网络(Artificial Neural Network,即ANN)(向量化)手写推导过程(我觉得已经很详细了)
学习了吴恩达老师深度学习工程师第一门课,受益匪浅,尤其是吴老师所用的符号系统,准确且易区分. 遵循吴老师的符号系统,我对任意层神经网络模型进行了详细的推导,形成笔记. 有人说推导任意层MLP很容易,我 ...
- 吴恩达深度学习 反向传播(Back Propagation)公式推导技巧
由于之前看的深度学习的知识都比较零散,补一下吴老师的课程希望能对这块有一个比较完整的认识.课程分为5个部分(粗体部分为已经看过的): 神经网络和深度学习 改善深层神经网络:超参数调试.正则化以及优化 ...
- 深度学习 吴恩达深度学习课程2第三周 tensorflow实践 参数初始化的影响
博主 撸的 该节 代码 地址 :https://github.com/LemonTree1994/machine-learning/blob/master/%E5%90%B4%E6%81%A9%E8 ...
- Coursera 吴恩达 深度学习 学习笔记
神经网络和深度学习 Week 1-2 神经网络基础 Week 3 浅层神经网络 Week 4 深层神经网络 改善深层神经网络 Week 1 深度学习的实用层面 Week 2 优化算法 Week 3 超 ...
- 吴恩达深度学习笔记(deeplearning.ai)之卷积神经网络(二)
经典网络 LeNet-5 AlexNet VGG Ng介绍了上述三个在计算机视觉中的经典网络.网络深度逐渐增加,训练的参数数量也骤增.AlexNet大约6000万参数,VGG大约上亿参数. 从中我们可 ...
- 吴恩达深度学习笔记(deeplearning.ai)之循环神经网络(RNN)(三)
1. 导读 本节内容介绍普通RNN的弊端,从而引入各种变体RNN,主要讲述GRU与LSTM的工作原理. 事先声明,本人采用ng在课堂上所使用的符号系统,与某些学术文献上的命名有所不同,不过核心思想都是 ...
随机推荐
- Docker | 入门 & 基础操作
Dcoker 入门 确保docker 已经安装好了,如没有装好的可以参考:Docker | 安装 运行第一个容器 docker run -it ubuntu /bin/bash docker run ...
- Python - typing 模块 —— Optional
前言 typing 是在 python 3.5 才有的模块 前置学习 Python 类型提示:https://www.cnblogs.com/poloyy/p/15145380.html 常用类型提示 ...
- Jenkins持续集成接口压测
步骤 自动化压测- jmeter + shell Jenkins与jmeter压测,环境要求 自动压测运行逻辑 Jmeter输出压力测试报告 压测报告与Jenkins集成 Jenkins任务:源码同步 ...
- C# Dapper基本三层架构使用 (三、DAL)
数据访问层(DAL),主要是存放对数据类的访问,即对数据库的添加.删除.修改.更新等基本操作 首先需要在UI层App.Config配置文件中增加连接字符串,如下所示 <connectionStr ...
- 计算机网络-TCP篇
TCP篇 之前的总结文章:TCP简单版本介绍-三次握手等 基本认识 TCP 是⾯向连接的(⼀定是「⼀对⼀」才能连接).可靠的.基于字节流的传输层通信协议. RFC 793 是如何定义「连接」的:⽤于保 ...
- vue 工作随笔
现在工作要做一个电商项目,将工3作的笔记记在这儿,以后方便结总 本套项目用的前端方案 是: vue vue-router Element -ui Axios Echarts 后端技术采用node.js ...
- 使用Eclipse的基本配置
因本人 IntelliJ IDEA 正版授权前些日子已到期,最近开始使用 Eclipse .体验开发了一阵子,觉得除了在界面美观与前端编辑的操作上 Eclipse 与 IDEA 差距还比较大以外,其他 ...
- CodeForce-799C Fountains (记忆化DP)
Fountains CodeForces - 799C 某土豪想要造两座喷泉.现在有 n 个造喷泉的方案,我们已知每个方案的价格以及美观度.有两种合法的货币:金币和钻石.这两种货币之间不能以任何方式转 ...
- 【OI】蛇形填数题的深入探究
题目:在 n×n 方阵里填入 1,2,...n×n, 要求蛇形填数.例如,n=4 时方阵为: 10 11 12 1 9 16 13 2 8 15 14 3 7 6 ...
- eclipse中的一些快捷键
1.内容提示 Alt+/ 2.快速修复 ctrl+/ 3.导包 ctrl+shift+o 4.格式代码块 ctrl+shift+o 5.向前向后 Alt+方向键 6.添加注释 ctrl+shift+/ ...