python3 爬虫五大模块之一:爬虫调度器
Python的爬虫框架主要可以分为以下五个部分:
爬虫调度器:用于各个模块之间的通信,可以理解为爬虫的入口与核心(main函数),爬虫的执行策略在此模块进行定义;
URL管理器:负责URL的管理,包括带爬取和已爬取的URL、已经提供相应的接口函数(类似增删改查的函数)
网页下载器:负责通过URL将网页进行下载,主要是进行相应的伪装处理模拟浏览器访问、下载网页
网页解析器:负责网页信息的解析,这里是解析方式视具体需求来确定
信息采集器:负责将解析后的信息进行存储、显示等处理
代码示例是爬取CSDN博主下的所有文章为例,文章仅作为笔记使用,理论知识rarely
一、爬虫调度器简介
爬虫调度器作为框架的核心组成部分和爬虫的入口,负责将各个模块进行统一管理和调度,类似于C语言里的main函数。
爬虫调度器核心框架:
'''
自定义Python伪代码:
''' # 1. 传入待爬取的网站URL链接
# 2. 将URL添加到URL管理器的待爬取url列表中
# 3. 执行爬行策略:
while condition:
#4. 将待爬取的URL从URL管理器中取出,并传递给网页下载器
#5. 将网页下载器下载的网页信息传递给网页解析器
#6. 将网页解析器解析后的新的URL信息添加到URL管理器
#7. 将网页解析器解析后的其他信息传递给采集器
# 8. 爬取完毕
二、爬虫调度器示例:(爬取CSDN博主下的所有文章)
# author : s260389826
# date : 2019/3/22
# position: chengdu
from cnsd import url_manager
from cnsd import html_downloader
from cnsd import html_parser
from cnsd import html_outputer
class SpiderMain:
def __init__(self): # 创建其余四个模块
self.urlManager = url_manager.UrlManager()
self.htmlDownloader = html_downloader.HtmlDownloader()
self.htmlParse = html_parser.HtmlParser()
self.htmlOutputer = html_outputer.HtmlOutputer()
# 根据博主名构建博主文章页的完整URL
def getAllUrl(self, usr_blog, page):
return "http://blog.csdn.net/" + usr_blog + "/article/list/" + str(page) + '?'
# 爬虫主函数
def crawl(self, usr_blog, total_pages):
if usr_blog is None or total_pages == 0:
print("spider_Main: initial url is None or total_pages is 0")
return
page = 1
seq = 0
root_url = self.getAllUrl(usr_blog, page) # 获取完整的URL
self.urlManager.add_page_url(root_url) # 添加到URL管理器
while self.urlManager.has_page_url():
page_url = self.urlManager.get_page_url() # 取出URL
html = self.htmlDownloader.downloader(page_url) # 下载网页
article_urls = self.htmlParse.parser(page# 解析网页_url, html) # 解析网页
for article_url in artic# 遍历文章的URLle_urls: # 遍历文章的URL
# print(article_url)
seq = seq + 1
html = self.htmlDownloader.downloader(article_url) # 下载文章
self.htmlOutputer.collect(usr_blog, seq, html) # 解析、存储文章
if page < total_pages: # 是否继续爬取下一页
page = page + 1
next_page_url = self.getAllUrl(usr_blog, page)
self.urlManager.add_page_url(next_page_url)
# print("-=-=-=-=-=-=-=-=-=-文章数量为:%d=-=-=-=-=-=-=-=-=-=-=-" % len(article_urls))
print("===================csdn spider over====================")
'''
该爬虫用来爬取CSDN博客博主的所有文章:
UserBlog : 博主账号名称
page_number : 博主博客下的页码数
'''
if __name__ == '__main__':
# print('Please input your CSDN blog\'name:')
# name = input()
# print('Please input your CSDN blog total pages:')
# page_number = input()
# base_url = 'http://blog.csdn.net/%s' % name
UserBlog = "yunsongice" #" http://blog.csdn.net/s2603898260"
page_number = int(16)
spider = SpiderMain()
spider.crawl(UserBlog, page_number)
三、上述代码用到的知识点:
1. 引用该packet下的其他类文件:
from cnsd import url_manager
from cnsd import html_downloader
from cnsd import html_parser
from cnsd import html_outputercnsd:在工程中创建的一个Python pagcket文件, 然后将其命名为“cnsd” (这是个手误操作):
创建后的目录为:
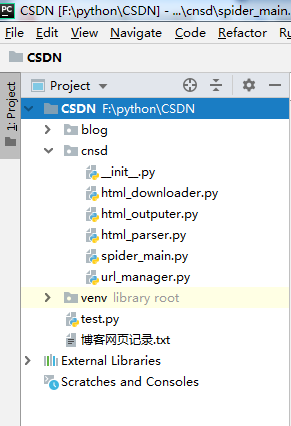
创建完packet目录后,依次创建了如上图所示的五个模块的python文件,引用的便是另外四个的文件名。
2. 通过构造器创建示例对象:
def __init__(self): # 创建其余四个模块
self.urlManager = url_manager.UrlManager()
self.htmlDownloader = html_downloader.HtmlDownloader()
self.htmlParse = html_parser.HtmlParser()
self.htmlOutputer = html_outputer.HtmlOutputer()3. 标记主函数入口:
if __name__ == '__main__':python3 爬虫五大模块之一:爬虫调度器的更多相关文章
- python3 爬虫五大模块之五:信息采集器
Python的爬虫框架主要可以分为以下五个部分: 爬虫调度器:用于各个模块之间的通信,可以理解为爬虫的入口与核心(main函数),爬虫的执行策略在此模块进行定义: URL管理器:负责URL的管理,包括 ...
- python3 爬虫五大模块之三:网页下载器
Python的爬虫框架主要可以分为以下五个部分: 爬虫调度器:用于各个模块之间的通信,可以理解为爬虫的入口与核心(main函数),爬虫的执行策略在此模块进行定义: URL管理器:负责URL的管理,包括 ...
- python3 爬虫五大模块之二:URL管理器
Python的爬虫框架主要可以分为以下五个部分: 爬虫调度器:用于各个模块之间的通信,可以理解为爬虫的入口与核心(main函数),爬虫的执行策略在此模块进行定义: URL管理器:负责URL的管理,包括 ...
- python3 爬虫五大模块之四:网页解析器
Python的爬虫框架主要可以分为以下五个部分: 爬虫调度器:用于各个模块之间的通信,可以理解为爬虫的入口与核心(main函数),爬虫的执行策略在此模块进行定义: URL管理器:负责URL的管理,包括 ...
- python 爬虫 urllib模块 反爬虫机制UA
方法: 使用urlencode函数 urllib.request.urlopen() import urllib.request import urllib.parse url = 'https:// ...
- python 爬虫 urllib模块 目录
python 爬虫 urllib模块介绍 python 爬虫 urllib模块 url编码处理 python 爬虫 urllib模块 反爬虫机制UA python 爬虫 urllib模块 发起post ...
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
本次python爬虫百步百科,里面详细分析了爬虫的步骤,对每一步代码都有详细的注释说明,可通过本案例掌握python爬虫的特点: 1.爬虫调度入口(crawler_main.py) # coding: ...
- golang实现并发爬虫三(用队列调度器实现)
欲看此文,必先可先看: golang实现并发爬虫一(单任务版本爬虫功能) gollang实现并发爬虫二(简单调度器) 上文中的用简单的调度器实现了并发爬虫. 并且,也提到了这种并发爬虫的实现可以提高爬 ...
- golang实现并发爬虫二(简单调度器)
上篇文章当中实现了单任务版爬虫. 那么这篇文章就大概说下,如何在上一个版本中进行升级改造,使之成为一个多任务版本的爬虫.加快我们爬取的速度. 话不多说,先看图: 其实呢,实现方法就是加了一个sched ...
随机推荐
- Node.js躬行记(8)——通用接口
一.GraphQL 最近服务端的同事分享了GraphQL,他分享的目的就是要把我们与他们的数据库隔离,这么做我们也求之不得. 我们组目前维护着一个后台管理系统,会直接读取数据库中的表,如果能隔离的话, ...
- IPSec组播概要
IPSec作为主流IP安全协议之一,在单播环境下,特别是在VPN场景中应用广泛.但是在组播环境貌似看到的不多,通过RFC4301了解到IPSec首先是支持组播的,即通过手动配置的方式可以实现组播包加密 ...
- CVE-2020-1472
主要记下流程 我擦,这个洞mimikatz也可以搞 但是我就不记录了 检验漏洞是否存在 https://github.com/SecuraBV/CVE-2020-1472 先获取域控信息 然后测试能否 ...
- Access Java API in Groovy Script
$ cat Hello.java package test; public class Hello { public int myadd(int x, int y) { return 10 * x + ...
- 【笔记】多项式回归的思想以及在sklearn中使用多项式回归和pipeline
多项式回归以及在sklearn中使用多项式回归和pipeline 多项式回归 线性回归法有一个很大的局限性,就是假设数据背后是存在线性关系的,但是实际上,具有线性关系的数据集是相对来说比较少的,更多时 ...
- DVWA-全等级验证码Insecure CAPTCHA
DVWA简介 DVWA(Damn Vulnerable Web Application)是一个用来进行安全脆弱性鉴定的PHP/MySQL Web应用,旨在为安全专业人员测试自己的专业技能和工具提供合法 ...
- kubernetes/k8s CNI分析-容器网络接口分析
关联博客:kubernetes/k8s CSI分析-容器存储接口分析 kubernetes/k8s CRI分析-容器运行时接口分析 概述 kubernetes的设计初衷是支持可插拔架构,从而利于扩展k ...
- 一文搞懂Java/Spring/Dubbo框架中的SPI机制
几天前和一位前辈聊起了Spring技术,大佬突然说了SPI,作为一个熟练使用Spring的民工,心中一紧,咱也不敢说不懂,而是在聊完之后赶紧打开了浏览器,开始的学习之路,所以也就有了这篇文章.废话不多 ...
- redis支持的数据类型有哪些?
string,list,hash,set,zset 底层实现数据结构 数据结构 String sds struct sdshdr{ //等于 SDS 保存字符串的长度 int len; //记录 bu ...
- SpringCache(redis)
pom <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spr ...