Flink处理函数实战之二:ProcessFunction类
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
Flink处理函数实战系列链接
- 深入了解ProcessFunction的状态操作(Flink-1.10);
- ProcessFunction;
- KeyedProcessFunction类;
- ProcessAllWindowFunction(窗口处理);
- CoProcessFunction(双流处理);
关于处理函数(Process Function)
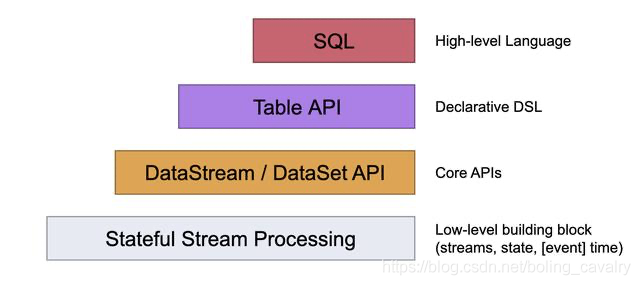
如下图,在常规的业务开发中,SQL、Table API、DataStream API比较常用,处于Low-level的Porcession相对用得较少,从本章开始,我们一起通过实战来熟悉处理函数(Process Function),看看这一系列的低级算子可以带给我们哪些能力?
关于ProcessFunction类
处理函数有很多种,最基础的应该ProcessFunction类,来看看它的类图,可见有RichFunction的特性open、close,然后自己有两个重要的方法processElement和onTimer:

常用特性如下所示:
- 处理单个元素;
- 访问时间戳;
- 旁路输出;
接下来写两个应用体验上述功能;
版本信息
- 开发环境操作系统:MacBook Pro 13寸, macOS Catalina 10.15.3
- 开发工具:IDEA ULTIMATE 2018.3
- JDK:1.8.0_211
- Maven:3.6.0
- Flink:1.9.2
源码下载
如果您不想写代码,整个系列的源码可在GitHub下载到,地址和链接信息如下表所示(https://github.com/zq2599/blog_demos):
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
这个git项目中有多个文件夹,本章的应用在flinkstudy文件夹下,如下图红框所示:
创建工程
执行以下命令创建一个flink-1.9.2的应用工程:
mvn \
archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.9.2
按提示输入groupId:com.bolingcavalry,architectid:flinkdemo
第一个demo
第一个demo用来体验以下两个特性:
- 处理单个元素;
- 访问时间戳;
创建Simple.java,内容如下:
package com.bolingcavalry.processfunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.util.Collector;
public class Simple {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 并行度为1
env.setParallelism(1);
// 设置数据源,一共三个元素
DataStream<Tuple2<String,Integer>> dataStream = env.addSource(new SourceFunction<Tuple2<String, Integer>>() {
@Override
public void run(SourceContext<Tuple2<String, Integer>> ctx) throws Exception {
for(int i=1; i<4; i++) {
String name = "name" + i;
Integer value = i;
long timeStamp = System.currentTimeMillis();
// 将将数据和时间戳打印出来,用来验证数据
System.out.println(String.format("source,%s, %d, %d\n",
name,
value,
timeStamp));
// 发射一个元素,并且戴上了时间戳
ctx.collectWithTimestamp(new Tuple2<String, Integer>(name, value), timeStamp);
// 为了让每个元素的时间戳不一样,每发射一次就延时10毫秒
Thread.sleep(10);
}
}
@Override
public void cancel() {
}
});
// 过滤值为奇数的元素
SingleOutputStreamOperator<String> mainDataStream = dataStream
.process(new ProcessFunction<Tuple2<String, Integer>, String>() {
@Override
public void processElement(Tuple2<String, Integer> value, Context ctx, Collector<String> out) throws Exception {
// f1字段为奇数的元素不会进入下一个算子
if(0 == value.f1 % 2) {
out.collect(String.format("processElement,%s, %d, %d\n",
value.f0,
value.f1,
ctx.timestamp()));
}
}
});
// 打印结果,证明每个元素的timestamp确实可以在ProcessFunction中取得
mainDataStream.print();
env.execute("processfunction demo : simple");
}
}
这里对上述代码做个介绍:
- 创建一个数据源,每个10毫秒发出一个元素,一共三个,类型是Tuple2,f0是个字符串,f1是整形,每个元素都带时间戳;
- 数据源发出元素时,提前把元素的f0、f1、时间戳打印出来,和后面的数据核对是否一致;
- 在后面的处理中,创建了ProcessFunction的匿名子类,里面可以处理上游发来的每个元素,并且还能取得每个元素的时间戳(这个能力很重要),然后将f1字段为奇数的元素过滤掉;
- 最后将ProcessFunction处理过的数据打印出来,验证处理结果是否符合预期;
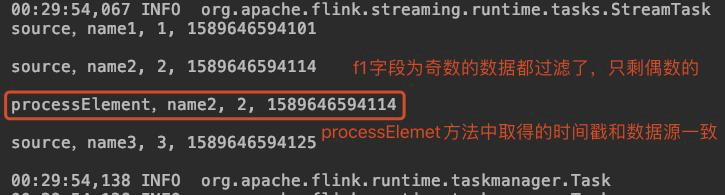
直接执行Simple类,结果如下,可见过滤和提取时间戳都成功了:
第二个demo
第二个demo是实现旁路输出(Side Outputs),对于一个DataStream来说,可以通过旁路输出将数据输出到其他算子中去,而不影响原有的算子的处理,下面来演示旁路输出:
创建SideOutput类:
package com.bolingcavalry.processfunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.util.ArrayList;
import java.util.List;
public class SideOutput {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 并行度为1
env.setParallelism(1);
// 定义OutputTag
final OutputTag<String> outputTag = new OutputTag<String>("side-output"){};
// 创建一个List,里面有两个Tuple2元素
List<Tuple2<String, Integer>> list = new ArrayList<>();
list.add(new Tuple2("aaa", 1));
list.add(new Tuple2("bbb", 2));
list.add(new Tuple2("ccc", 3));
//通过List创建DataStream
DataStream<Tuple2<String, Integer>> fromCollectionDataStream = env.fromCollection(list);
//所有元素都进入mainDataStream,f1字段为奇数的元素进入SideOutput
SingleOutputStreamOperator<String> mainDataStream = fromCollectionDataStream
.process(new ProcessFunction<Tuple2<String, Integer>, String>() {
@Override
public void processElement(Tuple2<String, Integer> value, Context ctx, Collector<String> out) throws Exception {
//进入主流程的下一个算子
out.collect("main, name : " + value.f0 + ", value : " + value.f1);
//f1字段为奇数的元素进入SideOutput
if(1 == value.f1 % 2) {
ctx.output(outputTag, "side, name : " + value.f0 + ", value : " + value.f1);
}
}
});
// 禁止chanin,这样可以在页面上看清楚原始的DAG
mainDataStream.disableChaining();
// 取得旁路数据
DataStream<String> sideDataStream = mainDataStream.getSideOutput(outputTag);
mainDataStream.print();
sideDataStream.print();
env.execute("processfunction demo : sideoutput");
}
}
这里对上述代码做个介绍:
- 数据源是个集合,类型是Tuple2,f0字段是字符串,f1字段是整形;
- ProcessFunction的匿名子类中,将每个元素的f0和f1拼接成字符串,发给主流程算子,再将f1字段为奇数的元素发到旁路输出;
- 数据源发出元素时,提前把元素的f0、f1、时间戳打印出来,和后面的数据核对是否一致;
- 将主流程和旁路输出的元素都打印出来,验证处理结果是否符合预期;
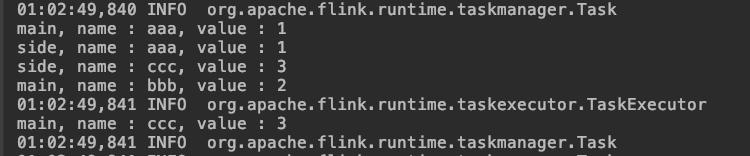
执行SideOutput看结果,如下图,main前缀的都是主流程算子,一共三条记录,side前缀的是旁路输出,只有f1字段为奇数的两条记录,符合预期:
上面的操作都是在IDEA上执行的,还可以将flink单独部署,再将上述工程构建成jar,提交到flink的jobmanager,可见DAG如下:
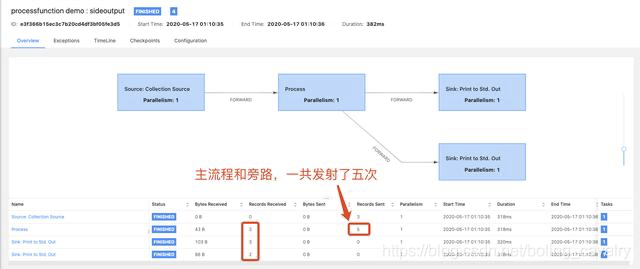
至此,处理函数中最简单的ProcessFunction类的学习和实战就完成了,接下来的文章我们会尝试更多了类型的处理函数;
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
Flink处理函数实战之二:ProcessFunction类的更多相关文章
- Flink处理函数实战之三:KeyedProcessFunction类
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink处理函数实战之四:窗口处理
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink处理函数实战之一:深入了解ProcessFunction的状态(Flink-1.10)
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink处理函数实战之五:CoProcessFunction(双流处理)
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink的sink实战之二:kafka
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink的sink实战之一:初探
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink的sink实战之三:cassandra3
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Flink的sink实战之四:自定义
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- [Java聊天室server]实战之二 监听类
前言 学习不论什么一个稍有难度的技术,要对其有充分理性的分析,之后果断做出决定---->也就是人们常说的"多谋善断":本系列尽管涉及的是socket相关的知识,但学习之前,更 ...
随机推荐
- windows 快速安装Python3.7.2
1.官方下载地址:https://www.python.org/downloads/release/python-372/ 其他地址:http://www.uzzf.com/soft/449550.h ...
- docker启动服务---------------nginx+php
环境 首先安装Docker,无论你是Windows还是Linux.MocOS都可以.安装Docker自行百度. Docker镜像源 访问https://hub.docker.com即可,它是镜像大仓库 ...
- kibana-安装-通过docker
拉取镜像 docker pull kibana:7.9.1 创建用户自定义网络 docker network create esnet 运行Kibana docker run --name ...
- 第七章 TCP和UDP原理
一.引入 1.TCP/IP协议族的传输层协议主要包括TCP和UDP 2.TCP是面向连接的可靠的传输层协议.它支持在并不可靠的网络上实现面向连接的可靠的数据传输 3.UDP是无连接的传输协议,主要用于 ...
- buuctf-misc-snake 详解
打开压缩包,里面一张蛇的图片,看的我是真恶心,看了看详细信息,没什么,然后我用formstlrb分离,然后有一个压缩包 以为还像往常一样,有伪加密或者简单加密,但是居然啥也没有,里面有两个文件,key ...
- 白话k8s-Pod的组成
k8s的所有功能都是围绕着Pod进行展开的,我们经常会看到类似这样一张图 告诉我们,Pod是一组container的集合,container之间可以通过localhost:port的方式直接访问. 感 ...
- PHP程序员必须会的 45 个PHP 面试题
Q1: == 和 === 之间有什么区别? 话题: PHP困难: 如果是两个不同的类型,运算符 == 则在两个不同的类型之间进行强制转换 === 操作符执行'类型安全比较' 这意味着只有当两个操作数具 ...
- GDB使用checkpoint复现bug
今天面试被问到一个问题,如何调试多进程的程序,我回答gdb attach [pid],之后又问如果程序中有些数据读取不对,但这种现象是偶然发生的,这时候要怎么操作,当时就懵了......,通过查找资料 ...
- while语句的一个使用技巧
作用类似于可以输入一个不定量长度的数组,但是严格来说 不可能出现任意长度. 内存是有限的 超出一定长度后,不可能存的下,虽然这个值可能是超级大的,但总有限度. 这里我们利用while(cin>& ...
- Java学习的第三十四天
1.今天复习完了第十二章 2.有很多的方法不知道什么意思,也记不清该用什么方法. 3.明天写例题.