Hadoop基础------>MR框架-->WordCount
认识Mapreduce
Mapreduce编程思想
Mapreduce执行流程
java版本WordCount实例
1. 简介:
Mapreduce源于Google一遍论文,是谷歌Mapreduce的克隆版,他充分借鉴了分而治之的思想,讲一个数据处理过程拆分为主要的Map(映射)和Reduce(归并)两步,只需要编写map函数和reduce函数即可。
2. Mapreduce优势:
分布式带来了三个复杂:1.程序的分布和启动
2.任务的监控和失败处理
3.中间数据的缓存和调度
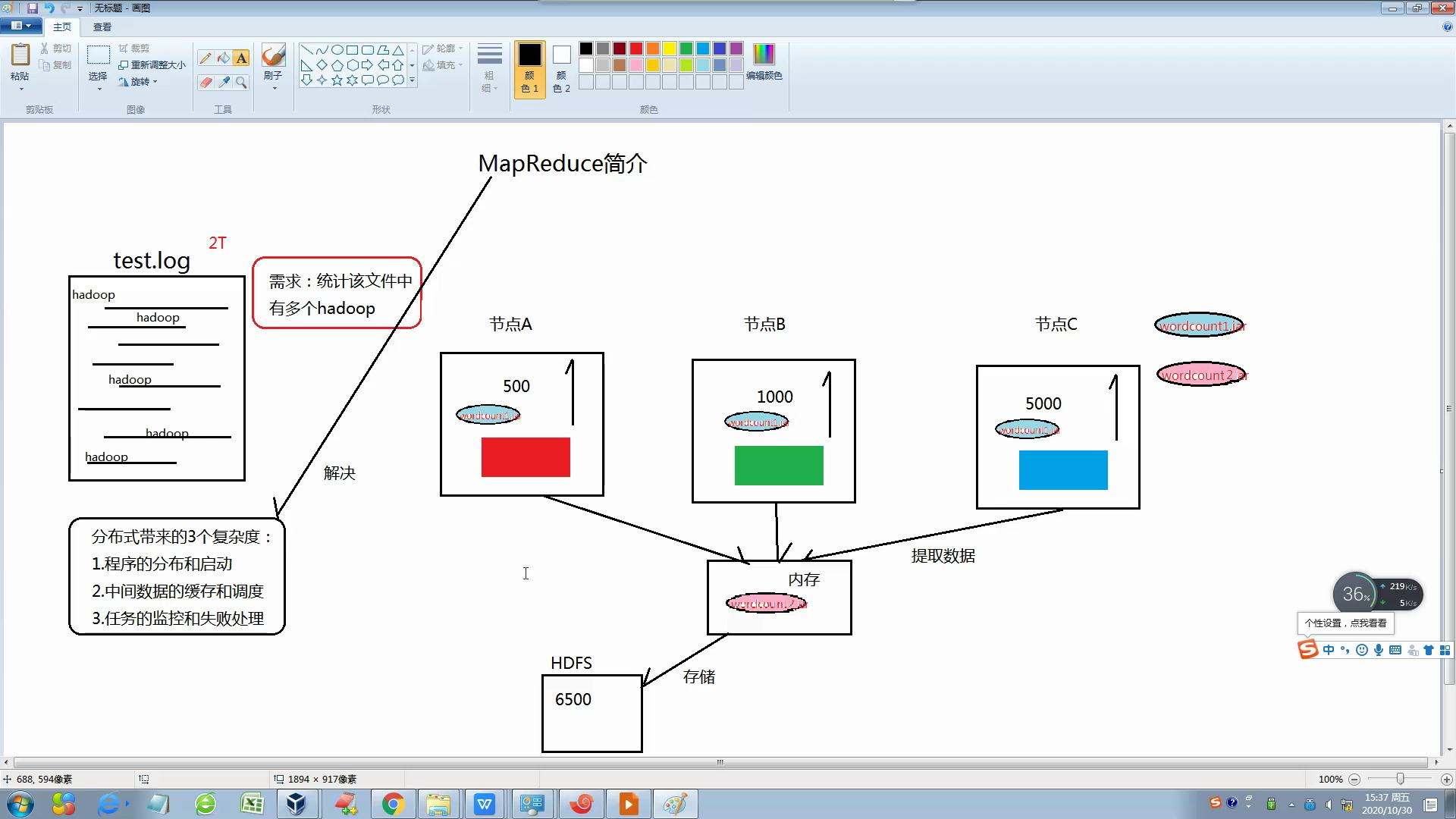
然后Mapreduce是一个并行程序设计模型与方法和好的解决了以上的缺点,并具有:1开发简单
2可扩展性强
3.容错性强
3 Mapreduce的执行流程图:

3-2 Mapreduce的实现过程图:
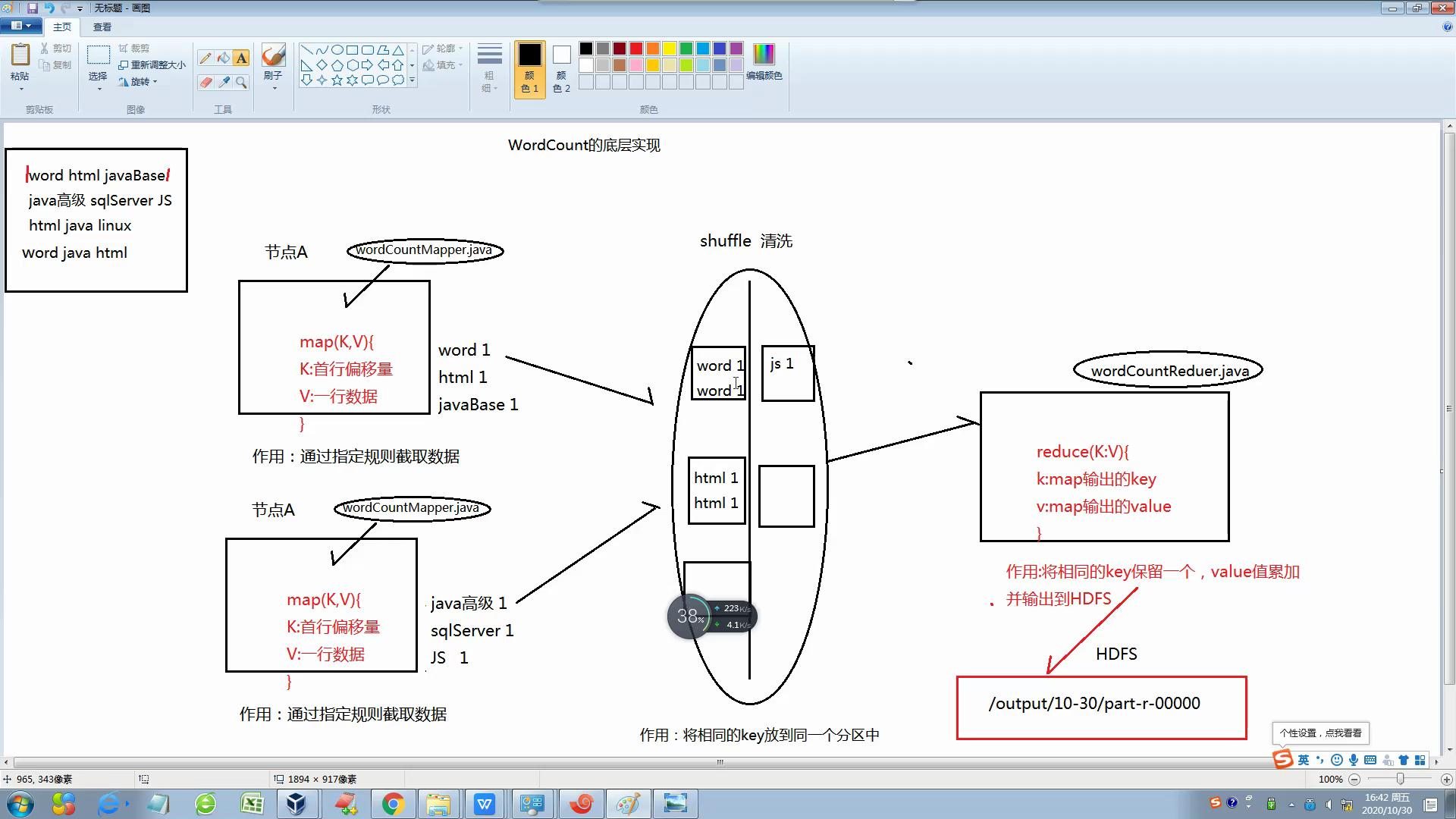
4 基层案例:
- 开发步骤:
- 1.新建项目导入所需的jar包
- 2.编写Mapper类
- 3.编写Reduce类
- 4.提交任务
- 5.观察结果
4-1 Mapper类:继承Mapper类重写map方法在父类中需要定义个泛型,含别4个设置,分别是:KEYIN,VALUEIN,KEYOUT,VALUEOUT
- KEYIN:读入每行文件开头的偏移量(首行偏移量)
- VALUEIN:读入每行文件内容的类型
- KEYOUT:表示Mapper完毕后,输出的文件作为KEY的数据类型
- VALUEOUT:表示Mapper完毕后,输出的文件作为VALUE的数据类型
执行流程:
- 读取一行数据
- 按照规则截取
- 获取有效数据
- 将数据写到上下文中
实例:
public class WordCount {
static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
//读取一行数据
String line = value.toString();
//根据指定规则截取数据
String [] words = line.split(" ");
//获取有效数据
for (int i = 0; i < words.length; i++) {
//将数据写入上下文
context.write(new Text(words[i]), new IntWritable(1));
}
}
}
}
4-2 Reduce类:在写的时候需要继承Reducer类重写ducer方法在父类中需要定义个泛型,含别4个设置,分别是:KEYIN,VALUEIN,KEYOUT,VALUEOUT
- KEYIN:表示从mapper中传递过来的key的数据的数据类型
- VALUEIN:表示从mapper中传递过来的value的数据的数据类型
- KEYOUT:表示Reducer完毕后,输出的文件作为KEY的数据类型
- VALUEOUT:表示Reducer完毕后,输出的文件作为VAKUE的数据类型
执行流程:
- 定义一个空的变量来接受定义的值(累加器)
- 遍历values集合,累加统计
- 将结果写入上下文中
实例:
static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//定义空变量
int i = 0 ;
//遍历values集合,累加统计
for (IntWritable value : values) {
i += value.get();
}
//写入上下文
context.write(key, new IntWritable(i));
}
}
4-3 提交类编写流程:
- 创建Configuration
- 准备清理已存在的输出目录
- 创建Jop
- 设置job的提交类
- 设置mapper相关的类和参数
- 设置reduce相关的类和参数
- 提交任务
实例:
public static void main(String[] args) throws Exception {
//加载配置文件
Configuration config = new Configuration();
//创建job对象
Job job = Job.getInstance(config);
//设置提交主类
job.setJarByClass(wordCountApp.class);
//设置mapper相关设置提交主类
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置reducer相关
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置输入路径(必须存在hdfs上)
FileInputFormat.setInputPaths(job, new Path("/score.txt"));
//设置输出路径
FileOutputFormat.setOutputPath(job, new Path("/ouput10"));
//提交任务
job.waitForCompletion(true);
}
使用eclipse导出架包,并通关传输软件到LinuX上最后完成上传
Hadoop基础------>MR框架-->WordCount的更多相关文章
- Hadoop基础学习框架
我们主要使用Hadoop的2个部分:分布式文件存储系统(HDFS)和MapReduce计算模型. 关于这2个部分,可以参考一下Google的论文:The Google File System 和 Ma ...
- hadoop之mr框架的源码理解注意点
1.reduce源码中的 GroupComparable和SecondaryComparable到底都是干什么的 理解点1: 源码位置 理解点 secondaryComparable这个是可以对map ...
- Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习MapReduce时的一些 ...
- Hadoop基础-配置历史服务器
Hadoop基础-配置历史服务器 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比 ...
- Hadoop基础-MapReduce的工作原理第一弹
Hadoop基础-MapReduce的工作原理第一弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在本篇博客中,我们将深入学习Hadoop中的MapReduce工作机制,这些知识 ...
- Hadoop基础-MapReduce的常用文件格式介绍
Hadoop基础-MapReduce的常用文件格式介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MR文件格式-SequenceFile 1>.生成SequenceF ...
- Hadoop基础原理
Hadoop基础原理 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 业内有这么一句话说:云计算可能改变了整个传统IT产业的基础架构,而大数据处理,尤其像Hadoop组件这样的技术出 ...
- Hadoop【MR开发规范、序列化】
Hadoop[MR开发规范.序列化] 目录 Hadoop[MR开发规范.序列化] 一.MapReduce编程规范 1.Mapper阶段 2.Reducer阶段 3.Driver阶段 二.WordCou ...
- Hadoop MapReduceV2(Yarn) 框架简介[转]
对于业界的大数据存储及分布式处理系统来说,Hadoop 是耳熟能详的卓越开源分布式文件存储及处理框架,对于 Hadoop 框架的介绍在此不再累述,读者可参考 Hadoop 官方简介.使用和学习过老 H ...
随机推荐
- Python练习题 031:Project Euler 003:最大质因数
本题来自 Project Euler 第3题:https://projecteuler.net/problem=3 # Project Euler: Problem 3: Largest prime ...
- 2.1 java语言概述
链接:https://pan.baidu.com/s/1ab2_KapIW-ZaT8kedNODug 提取码:miao
- 中部:执具 | R语言数据分析(北京邮电大学)自整理笔记
第5章工欲善其事.必先利其器 代码,是延伸我们思想最好的工具. 第6章基础编程--用别人的包和函数讲述自己的故事 6.1编程环境 1.R语言的三段论 大前提:计算机语言程序=算法+数据结构 小前提:R ...
- Python实现的数据结构与算法之快速排序详解
一.概述 快速排序(quick sort)是一种分治排序算法.该算法首先 选取 一个划分元素(partition element,有时又称为pivot):接着重排列表将其 划分 为三个部分:left( ...
- C#入门——Console.Write()与Console.WriteLine()
参考:https://blog.csdn.net/qujunyao/article/details/72884670 两者区别: Console.Write("abc"); 输出到 ...
- 题解【QTree3】
题目描述 给出N个点的一棵树(N-1条边),节点有白有黑,初始全为白 有两种操作: 0 i : 改变某点的颜色(原来是黑的变白,原来是白的变黑) 1 v : 询问1到v的路径上的第一个黑点,若无,输出 ...
- 《穷查理年鉴》习惯 & 工作 & 自省 & 自律 (关于自己)
习惯 001.在那充满古老年鉴的年代里,扔掉你的恶行,不管它们曾经给你带来多大的好处. 002.许多关于预言的争论都可以简化为:当你说是时,就有人说浊;当你认为不是时,一定有人说是. 003.坏习惯和 ...
- 联赛模拟测试12 B. trade
题目描述 分析 \(n^2\) 的 \(dp\) 应该比较好想 设 \(f[i][j]\) 为当前在第 \(i\) 天剩余的货物数量为 \(j\) 时的最大收益 那么它可以由 \(f[i-1][j]\ ...
- 常见的Mysql十款高可用方案
简介 我们在考虑MySQL数据库的高可用架构时,主要考虑如下几方面: 如果数据库发生了宕机或者意外中断等故障,能尽快恢复数据库的可用性,尽可能的减少停机时间,保证业务不会因为数据库的故障而中断. 用作 ...
- centos7 下 kafka的安装和基本使用
首先确保自己的linux环境下正确安装了Java 8+. 1:取得KAFKA https://mirrors.bfsu.edu.cn/apache/kafka/2.6.0/kafka_2.13-2.6 ...