网络流量预测入门(一)之RNN 介绍
网络流量预测入门(一)之RNN 介绍
了解RNN之前,神经网络的知识是前提,如果想了解神经网络,可以去参考一下我之前写的博客:数据挖掘入门系列教程(七点五)之神经网络介绍 and 数据挖掘入门系列教程(八)之使用神经网络(基于pybrain)识别数字手写集MNIST
这篇博客介绍RNN的原理,同时推荐大家去看李宏毅老师的课程:ML Lecture 21-1: Recurrent Neural Network (Part I)。基本上看完他的课程,也就没有必要看这篇博客了。
RNN简介
RNN全称Recurrent Neural Network ,中文名为循环神经网络(亦或称递归神经网络)。相信大家在看这篇博客之前都已经简单的了解过RNN。将RNN说的简单一点,就是进行预测(或者回归)的时候,不仅要考虑到当前时刻的输入,还要考虑上一个时刻的输入(甚至有些RNN的变种还会考虑未来的情况)。换句话说,预测的结果不仅与当前状态有关,还与上一个时刻的状态有关。
RNN用于处理时序信息 。而在传统的神经网络中,我们认为输入的 \(x_1,x_2,x_3\),是相互独立的:比如说在Iris分类中,我们认为鸢尾花的长宽是独立的,之间不存在前后序列逻辑关系。
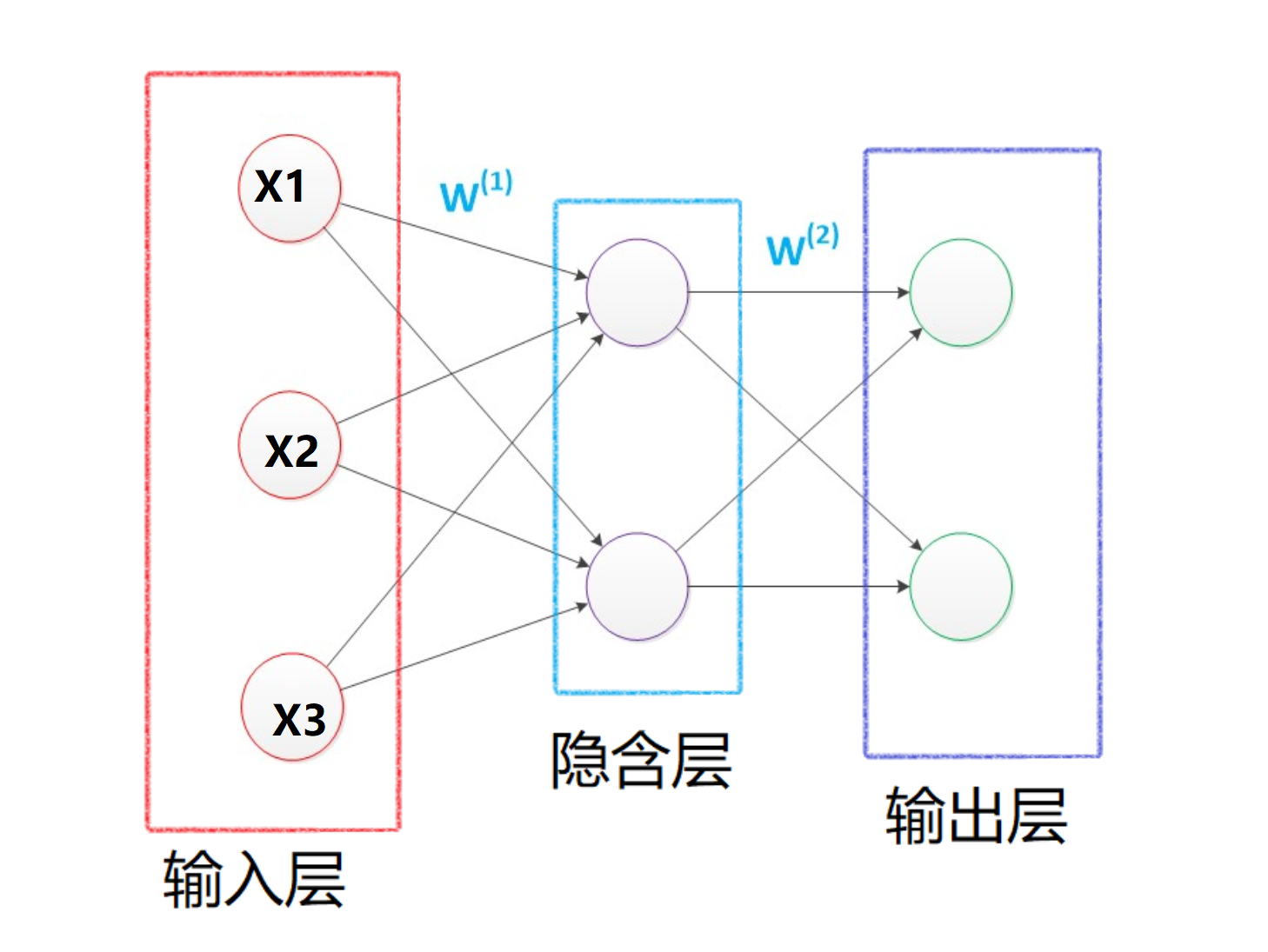
尽管传统的神经网络在预测中能够取得不错的成绩(比如说人脸识别等等),但是对于以下方式情景可能就爱莫能助了。

当我们想要预测一段话“小丑竟是我自____”时,我们必须根据前文的意思来predict。而RNN之所以叫做循环(recurrent),这是因为它的预测会考虑以前的信息。换句话说,也就是RNN具有memory,它“记得”之前计算后的情况。
在知乎全面理解RNN及其不同架构上,说了一个很形象的例子:
以捏陶瓷为例,不同角度相当于不同的时刻:
- 若用前馈网络:网络训练过程相当于不用转盘,而是徒手将各个角度捏成想要的形状。不仅工作量大,效果也难以保证。
- 若用递归网络(RNN):网络训练过程相当于在不断旋转的转盘上,以一种手势捏造所有角度。工作量降低,效果也可保证。

RNN 结构
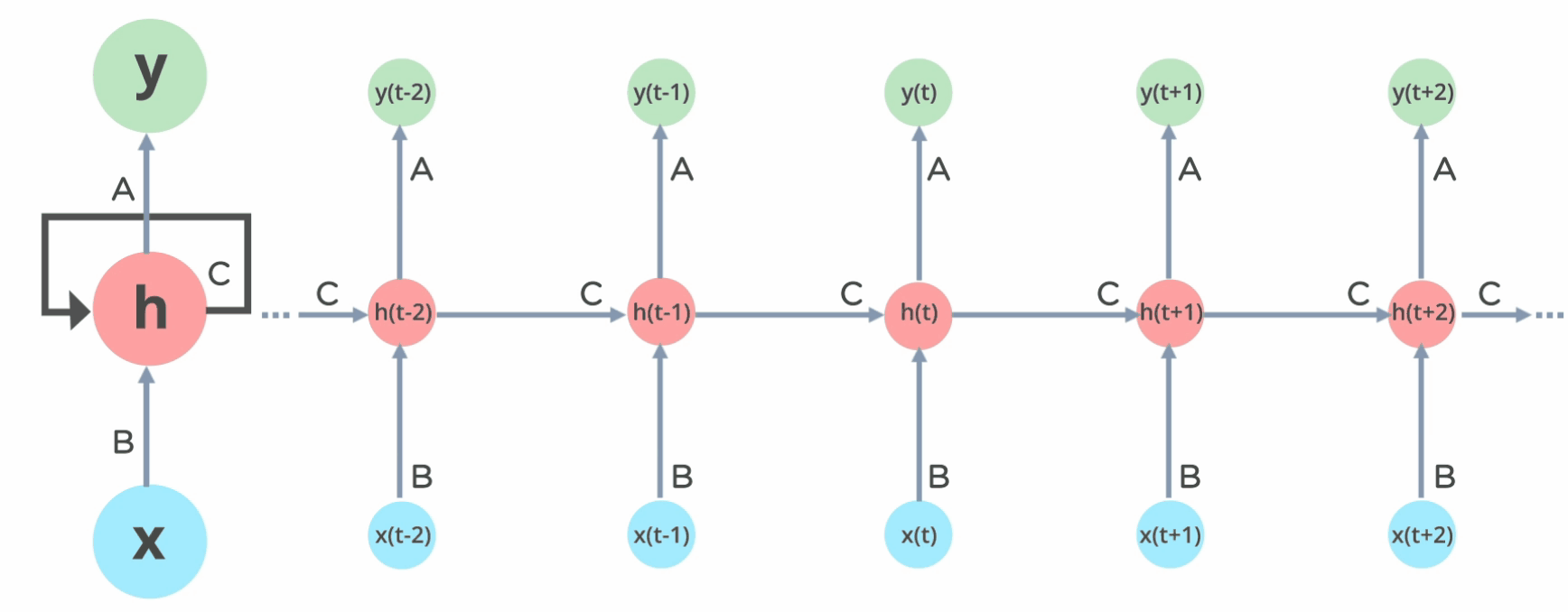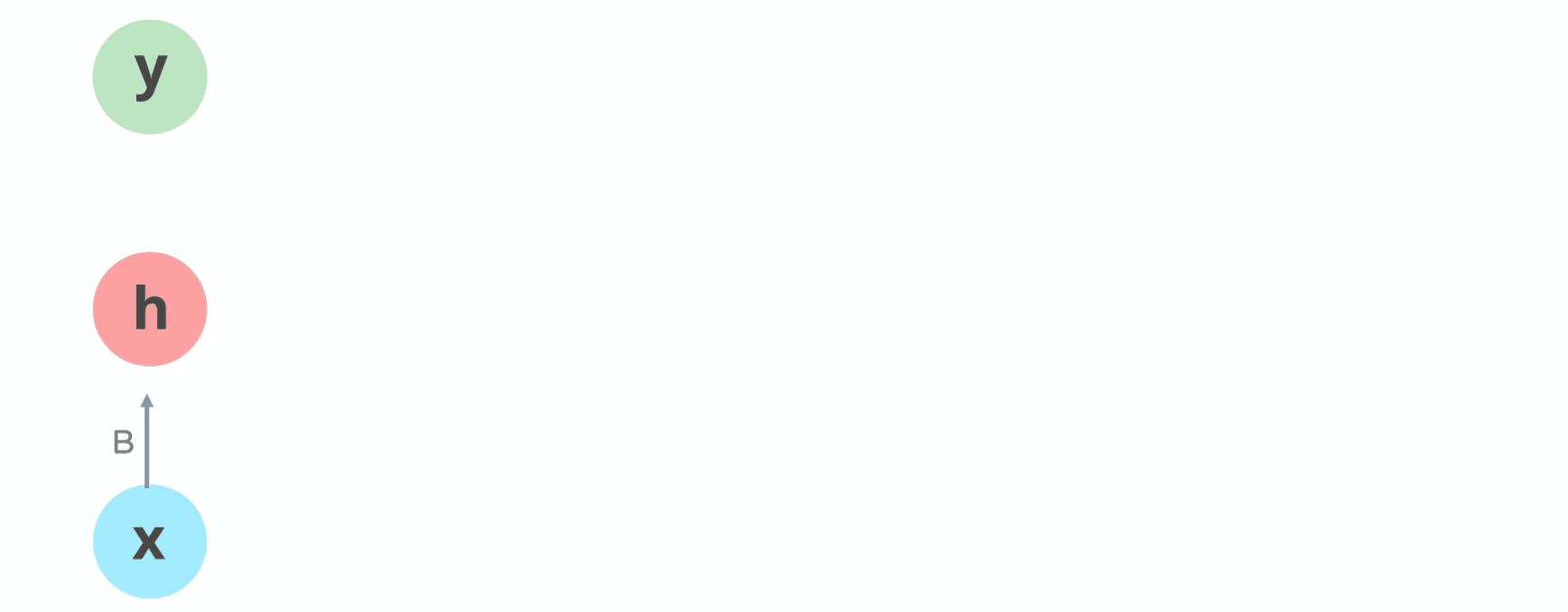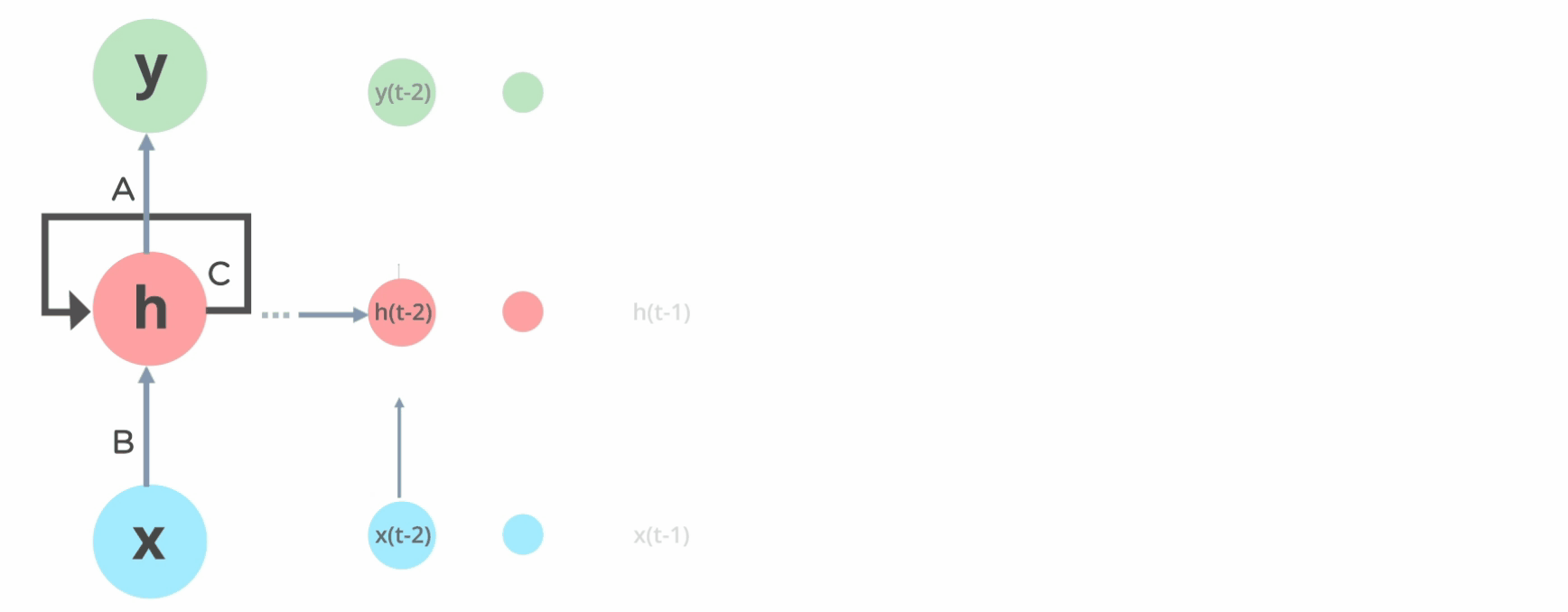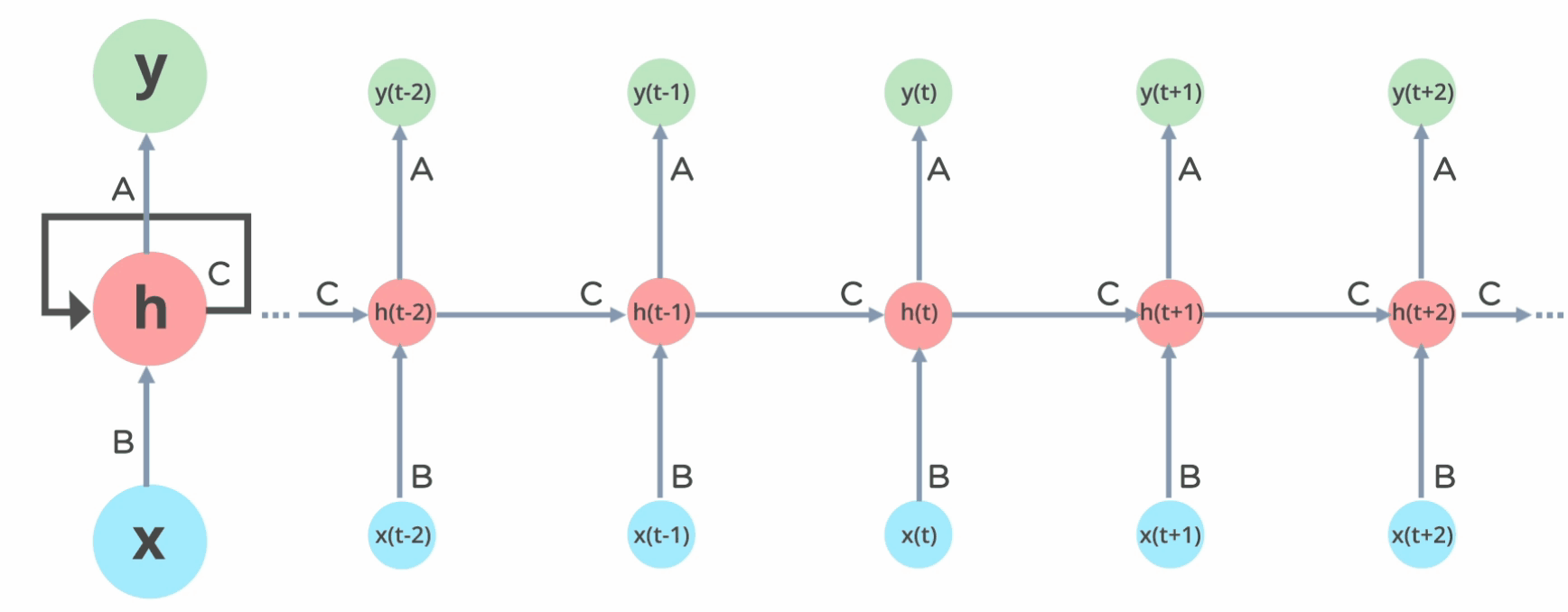
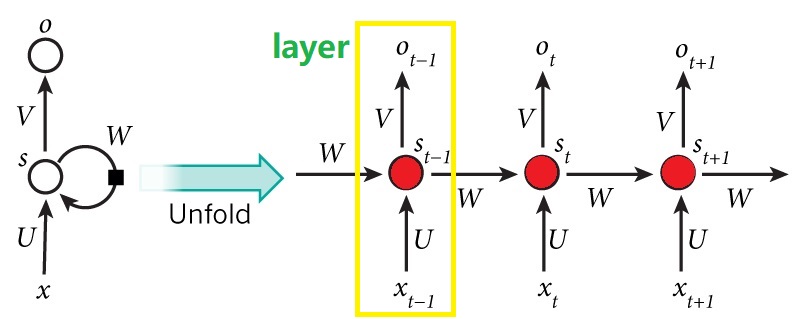
RNN的原理图,我们最多见的便是如左图所示,但是实际上将它展开,便是如下右图所示。
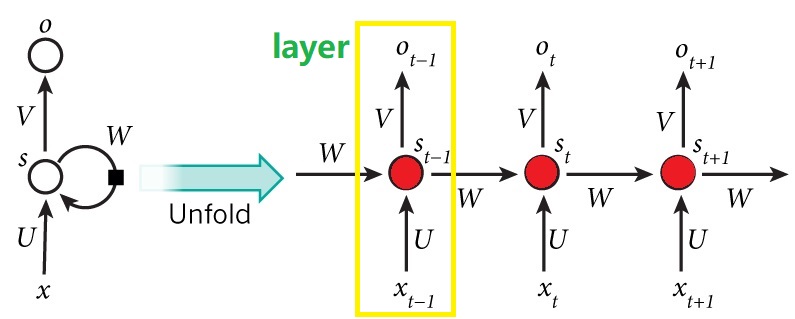
在RNN中,我们可以将黄框称之为一个layer,所有的layer的参数在一个batch中是相同的(参数共享),也就是说,上图中的 \(U,W,V\) 等参数在某个batch全部相同。(通过一个batch的训练之后,经过反向传播,参数会发生改变)
Layer的层数根据自己的需要来定,举个例子,比如说我们分析的句子是5个单词构成的句子,那么layer的层数便是5,每一个layer对应一个单词。
上图既有多个输入\(X_{t-1},X_{t},X_{t+1}\) , 也可以有多个输出\(O_{t-1},O_{t},O_{t+1}\) , 但是实际上输出可以根据实际的需要而定,既可以为多个输出,也可以只有一个输出,有如下几种:
Type of RNN Illustration Example One-to-one \(T_x=T_y=1\) 
Traditional neural network One-to-many \(T_x=1, T_y>1\) 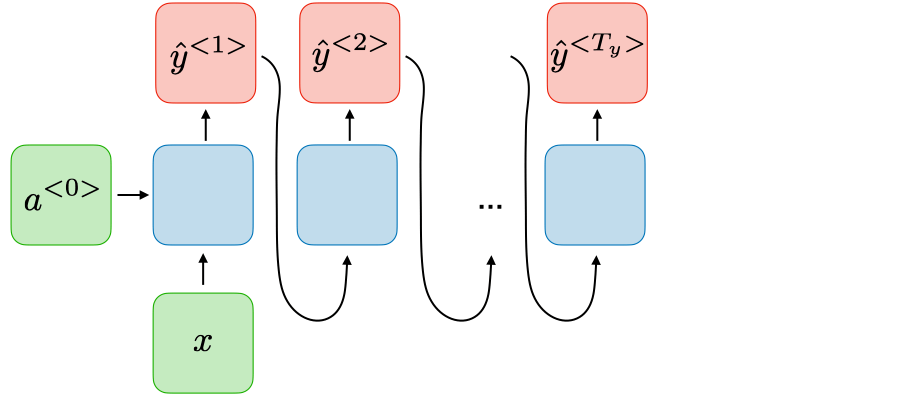
Music generation Many-to-one \(T_x>1, T_y=1\) 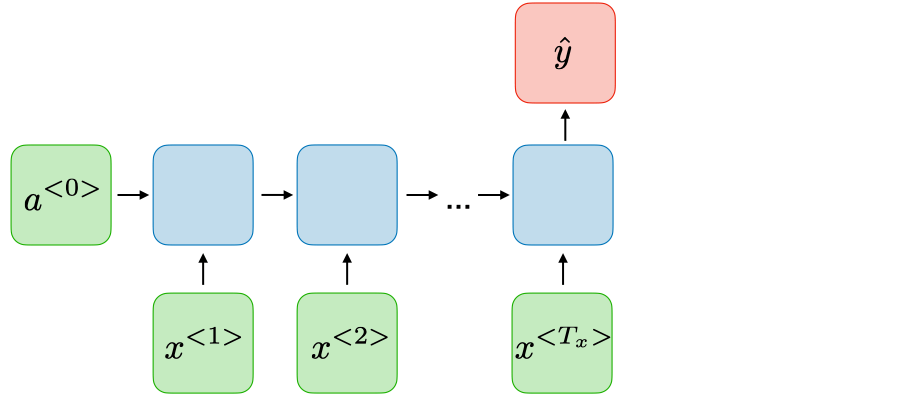
Sentiment classification Many-to-many \(T_x=T_y\) 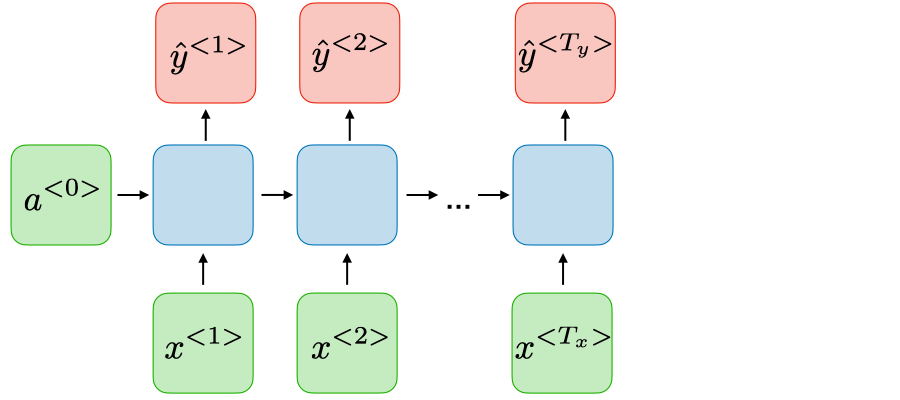
Name entity recognition Many-to-many \(T_x\neq T_y\) 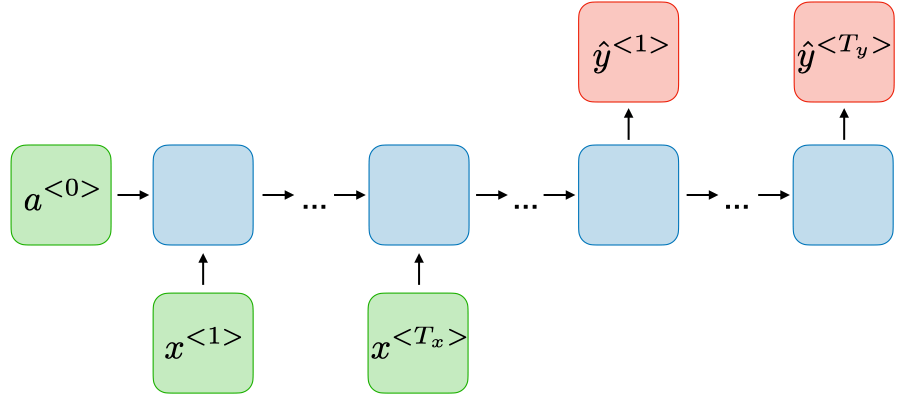
Machine translation
Gif图如下所示:
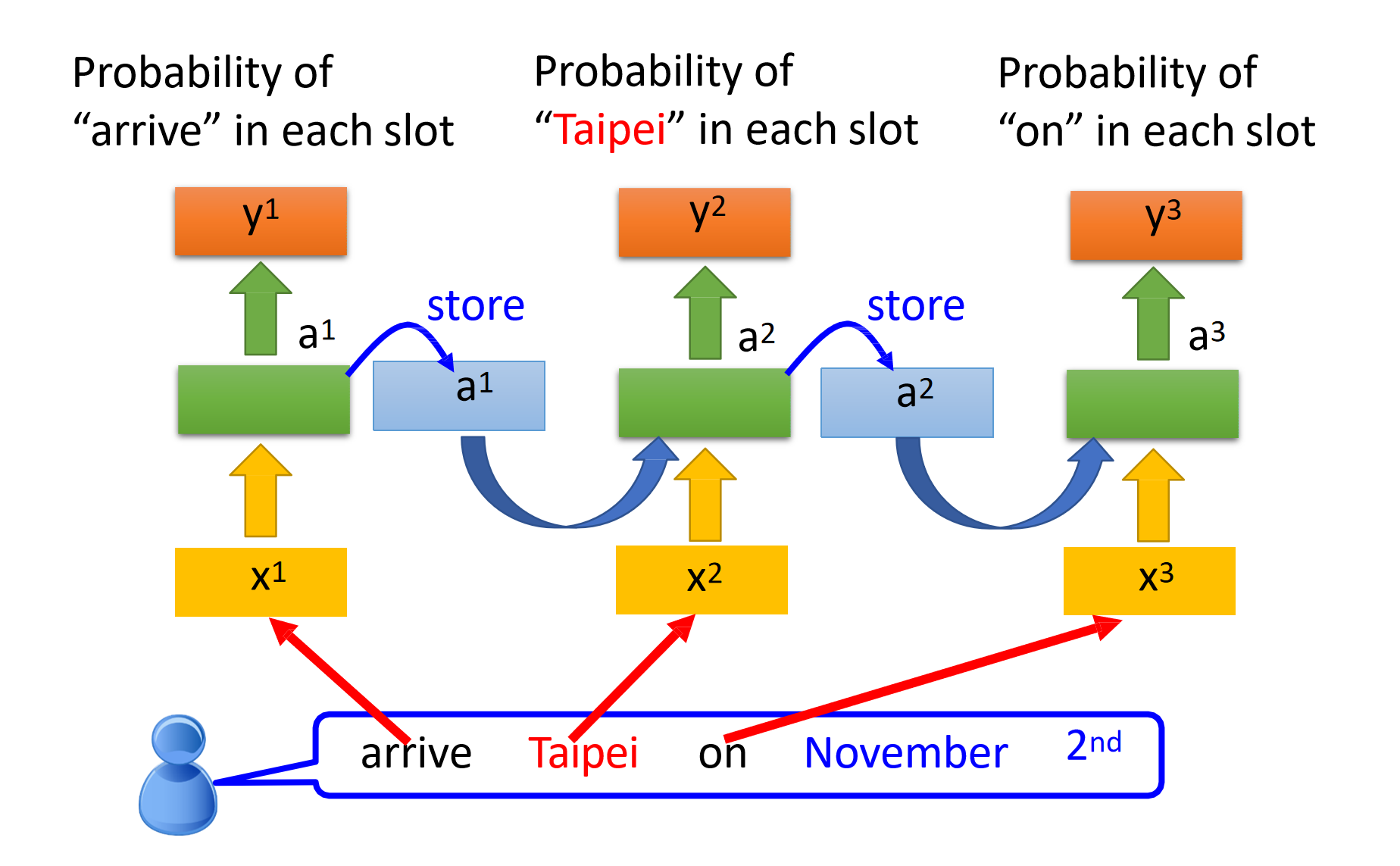
下图是李宏毅老师在课堂上讲的一个例子。
RNN原理
结构原理
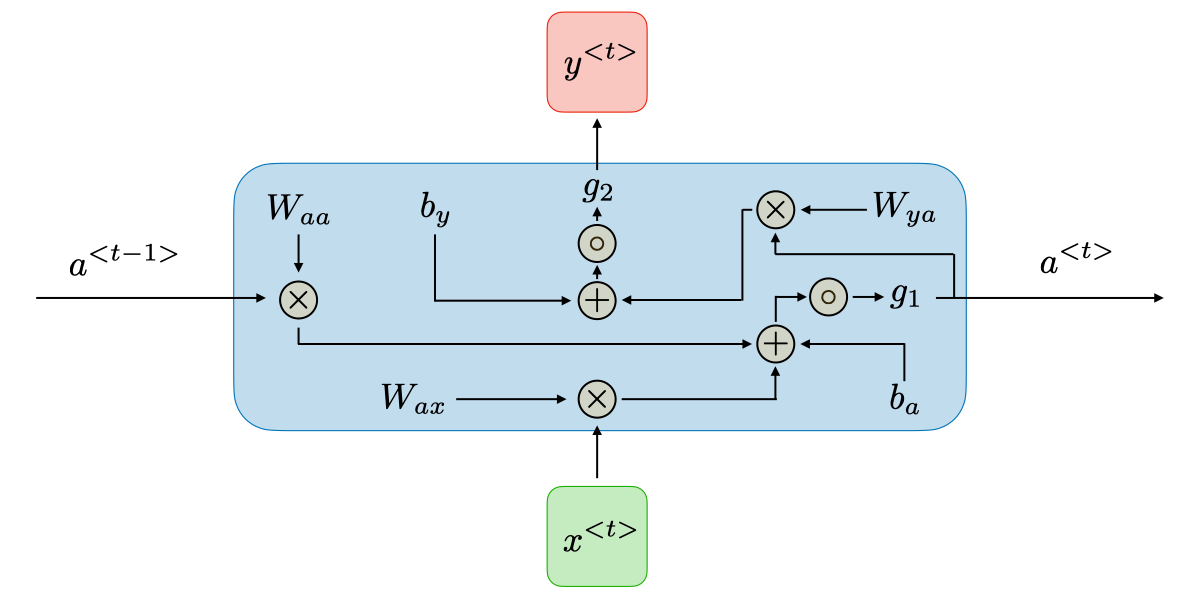
下面是来自Recurrent Neural Networks cheatsheet对RNN原理的解释:
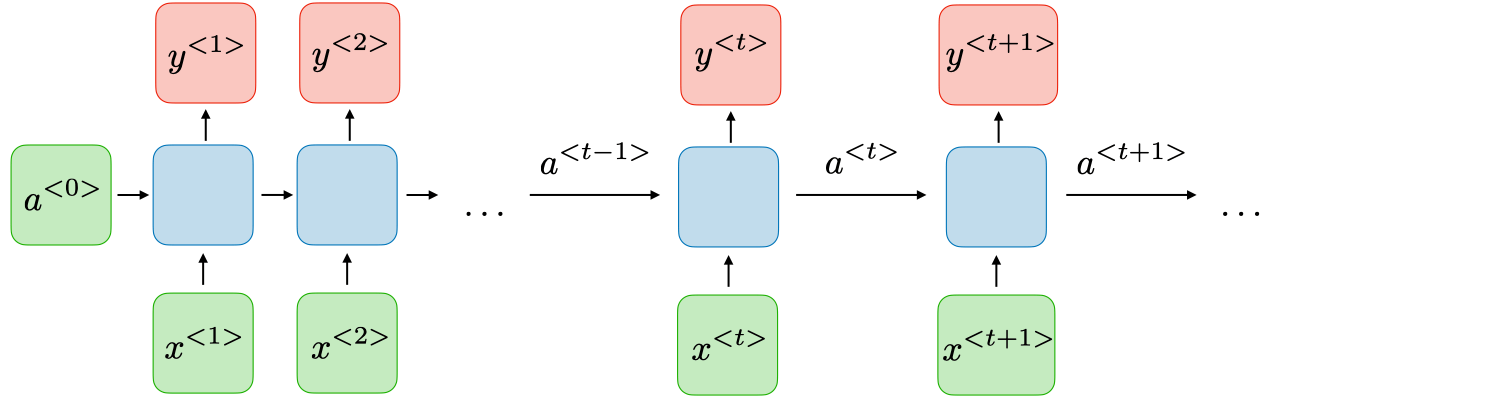
\(a^{<t>}\) 和 \(y^{<t>}\) 的表达式如下所示:
\]
\(W_{a x}, W_{a a}, W_{y a}, b_{a}, b_{y}\) 在时间上是共享的:也就是说,在一个batch中,无论是哪一个layer,其\(W_{a x}, W_{a a}, W_{y a}, b_{a}, b_{y}\)都是相同的(shared temporally)。当然,经过一个batch的训练之后,其值会因为反向传播而发生改变。
\(g_{1}, g_{2}\) 皆为激活函数(比如说tanh,sigmoid)
损失函数\(E\)
$ \mathcal{L}$ 为可微分的损失函数,比如交叉熵,其中\(y^{<t>}\)为t时刻正确的词语,\(\hat{y}^{<t>}\)为t时刻预测的词语。
{E}(\hat{y}, y)=\sum_{t=1}^{T_{y}} \mathcal{L}^{<t>}
\]
反向传播
反向传播目的就是求预测误差 \(E\) 关于所有参数 \((U, V, W)\) 的梯度, 即 \(\frac{\partial E}{\partial U}, \frac{\partial E}{\partial V}\) 和 \(\frac{\partial E}{\partial W}\) 。关于具体的推导可以参考循环神经网络(RNN)模型与前向反向传播算法。
知道梯度后,便可以对参数系数进行迭代更新了。
总结
在上述博客中,简单的对RNN进行了介绍,介绍了RNN作用,以及部分原理。而在下篇博客中,我将介绍如何使用keras构建RNN模型写唐诗。
网络流量预测入门(一)之RNN 介绍的更多相关文章
- 网络流量预测入门(二)之LSTM介绍
目录 网络流量预测入门(二)之LSTM介绍 LSTM简介 Simple RNN的弊端 LSTM的结构 细胞状态(Cell State) 门(Gate) 遗忘门(Forget Gate) 输入门(Inp ...
- 网络流量预测入门(三)之LSTM预测网络流量
目录 网络流量预测入门(三)之LSTM预测网络流量 数据集介绍 预测流程 数据集准备 SVR预测 LSTM 预测 优化点 网络流量预测入门(三)之LSTM预测网络流量 在上篇博客LSTM机器学习生成音 ...
- ARIMA模型实例讲解——网络流量预测可以使用啊
ARIMA模型实例讲解:时间序列预测需要多少历史数据? from:https://www.leiphone.com/news/201704/6zgOPEjmlvMpfvaB.html 雷锋网按:本 ...
- 网络流量预测 国内外研究现状【见评论】——传统的ARIMA、HMM模型,目前LSTM、GRU、CNN应用较多,貌似小波平滑预处理步骤非常关键
Time Series Anomaly Detection in Network Traffic: A Use Case for Deep Neural Networks from:https://j ...
- Kaggle比赛冠军经验分享:如何用 RNN 预测维基百科网络流量
Kaggle比赛冠军经验分享:如何用 RNN 预测维基百科网络流量 from:https://www.leiphone.com/news/201712/zbX22Ye5wD6CiwCJ.html 导语 ...
- Kaggle网站流量预测任务第一名解决方案:从模型到代码详解时序预测
Kaggle网站流量预测任务第一名解决方案:从模型到代码详解时序预测 2017年12月13日 17:39:11 机器之心V 阅读数:5931 近日,Artur Suilin 等人发布了 Kaggl ...
- mrtg监控网络流量简单配置
Mrtg服务器搭建(监控网络流量) [日期:2012-07-03] 来源:Linux社区 作者:split_two [字体:大 中 小] [实验环境] 监控机:Red Hat linux 5.3 ...
- 利用神经网络进行网络流量识别——特征提取的方法是(1)直接原始报文提取前24字节,24个报文组成596像素图像CNN识别;或者直接去掉header后payload的前1024字节(2)传输报文的大小分布特征;也有加入时序结合LSTM后的CNN综合模型
国外的文献汇总: <Network Traffic Classification via Neural Networks>使用的是全连接网络,传统机器学习特征工程的技术.top10特征如下 ...
- [转]HTTPS网络流量解密方法探索系列(一)
前言 分析网络流量总是绕不开HTTPS,因其广泛使用甚至是强制使用逐渐被大众熟知,在保证其安全的同时也提高了对流量进行研究的难度.目前解析HTTPS协议的文章很多,有很多不错的文章可以带着入门,老实说 ...
随机推荐
- 测试提bug及出现漏测情况时的注意点
提bug注意(此为公司开发提出的建议): 开发如果改bug影响导致另一个问题,原bug没有问题,尽量重新提bug,不要直接激活,因为可能不是同一个问题导致的: 不要一个bug里提多个问题,因为不同 ...
- Vue必须必须要注意的几个细节
1.每次执行完,尽量npm run dev 一次,有时候又缓存问题 2.安装sass 一.使用save会在package.json中自动添加.因为sass-loader依赖于node-sass npm ...
- redis源码学习之lua执行原理
聊聊redis执行lua原理 从一次面试场景说起 "看你简历上写的精通redis" "额,还可以啦" "那你说说redis执行lua脚本的原理&q ...
- 卷积涨点论文 | Asymmetric Convolution ACNet | ICCV | 2019
文章原创来自作者的微信公众号:[机器学习炼丹术].交流群氛围超好,我希望可以建议一个:当一个人遇到问题的时候,有这样一个平台可以快速讨论并解答,目前已经1群已经满员啦,2群欢迎你的到来哦.加入群唯一的 ...
- [leetcode]BestTimetoBuyandSellStock买卖股票系列问题
问题1: If you were only permitted to complete at most one transaction (ie, buy one and sell one share ...
- Java学习日报7.7
今天进一步学习了eclipse软件,遇到了几次程序运行不成功的问题,检查之后运行成功!明天继续学习程序逻辑控制!
- 第一章节 BJROBOT ROS 网络配置及移动控制【ROS全开源阿克曼转向智能网联无人驾驶车】
版权声明:该教程版权归北京智能佳科技有限公司所有,未经公司授权禁止引用.发布.转载等,否则将追究其法律责任. 使用前说明:本使用文档说明略微简明,请结合指导视频进行操作会更容易理解!! 第一章节 BJ ...
- JS常见面试题,看看你都会多少?
1. 如何在ES5环境下实现let 这个问题实质上是在回答let和var有什么区别,对于这个问题,我们可以直接查看babel转换前后的结果,看一下在循环中通过let定义的变量是如何解决变量提升的问题 ...
- 注意力论文解读(1) | Non-local Neural Network | CVPR2018 | 已复现
文章转自微信公众号:[机器学习炼丹术] 参考目录: 目录 0 概述 1 主要内容 1.1 Non local的优势 1.2 pytorch复现 1.3 代码解读 1.4 论文解读 2 总结 论文名称: ...
- flume基本概念及相关参数详解
1.flume是分布式的日志收集系统,把手机来的数据传送到目的地去 2.flume传输的数据的基本单位是 event,如果是文本文件,通常是一行记录. event代表着一个数据流的最小完整 ...