用MPI进行分布式内存编程(1)
《并行程序设计导论》第三章部分程序
程序3.1运行实例
#include<stdio.h>
#include<string.h>
#include<mpi.h> const int MAX_STRING=; int main()
{
char greet[MAX_STRING];
int comm_sz; //进程数
int my_rank; //进程号 MPI_Init(NULL,NULL); //初始化
MPI_Comm_size(MPI_COMM_WORLD,&comm_sz); //返回进程数
MPI_Comm_rank(MPI_COMM_WORLD,&my_rank); //返回进程号 if(my_rank!=)
{
sprintf(greet,"Greeting from process %d of %d",my_rank,comm_sz);
MPI_Send(greet,strlen(greet)+,MPI_CHAR,,,MPI_COMM_WORLD); //通信,发送
}
else
{
printf("Greeting from process %d of %d",my_rank,comm_sz);
int q;
for( q=;q<comm_sz;q++)
{
MPI_Recv(greet,MAX_STRING,MPI_CHAR,q,,MPI_COMM_WORLD,MPI_STATUS_IGNORE);//通信,接收
printf("%s\n",greet);
}
}
MPI_Finalize(); //告知系统MPI已使用完毕
return ; }
在天河平台运行结果
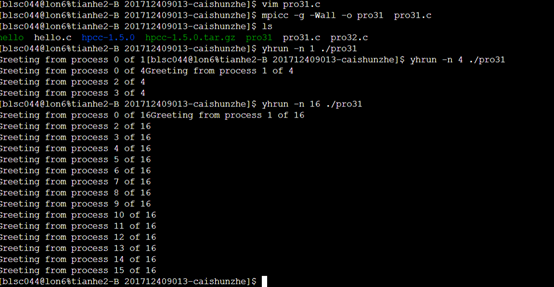
自己虚拟机运行结果

3.2运行实例
#include<stdio.h>
#include<string.h>
#include<mpi.h> double f(double x)
{
return x*x+x*x*x+;
}
double Trap(double left_endpt,double right_endpt,int trap_count,double base_len)
{ double estimate,x;
int i;
estimate=(f(left_endpt)+f(right_endpt))/2.0; //梯形面积
for(i =;i<=trap_count-;++i)
{
x=left_endpt+i*base_len;
estimate+=f(x);
}
estimate=estimate*base_len;
return estimate;
} int main()
{
int my_rank,comm_sz,n=,local_n;
double a=0.0,b=3.0,h,local_a,local_b;
double local_int,total_int;
int source; MPI_Init(NULL,NULL); //初始化
MPI_Comm_size(MPI_COMM_WORLD,&comm_sz); //返回进程数
MPI_Comm_rank(MPI_COMM_WORLD,&my_rank); //返回进程号 h=(b-a)/n;
local_n=n/comm_sz; local_a=a+my_rank*local_n*h;
local_b=local_a+local_n*h;
local_int=Trap(local_a,local_b,local_n,h); if(my_rank!=)
{
MPI_Send(&local_int,,MPI_DOUBLE,,,MPI_COMM_WORLD);
}
else
{
total_int=local_int;
for(source=;source<comm_sz;source++)
{
MPI_Recv(&local_int,,MPI_DOUBLE,source,,MPI_COMM_WORLD,MPI_STATUS_IGNORE); //接受其他节点信息
total_int+=local_int;
}
} if(my_rank==)
{
printf("With n=%d trapezoids,our estimated\n",n);
printf("of the intergral from %f to %f=%.15e\n",a,b,total_int);
} MPI_Finalize();
return ; }
天河运行结果
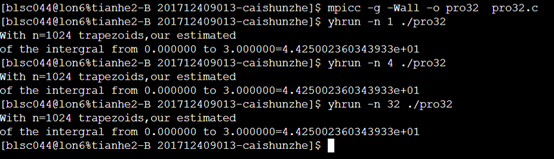

用MPI进行分布式内存编程(1)的更多相关文章
- 使用MPI进行分布式内存编程(2)
MPI的英文全称为message passing interface,中文名为消息传递接口,他不是一种新的语言,而是一个可以被C,C++,Fortran程序调用的库. 预备知识 1.编译与执行 使用类 ...
- 【并行计算】用MPI进行分布式内存编程(一)
通过上一篇关于并行计算准备部分的介绍,我们知道MPI(Message-Passing-Interface 消息传递接口)实现并行是进程级别的,通过通信在进程之间进行消息传递.MPI并不是一种新的开发语 ...
- 【并行计算】用MPI进行分布式内存编程(二)
通过上一篇中,知道了基本的MPI编写并行程序,最后的例子中,让使用0号进程做全局的求和的所有工作,而其他的进程却都不工作,这种方式也许是某种特定情况下的方案,但明显不是最好的方案.举个例子,如果我们让 ...
- Python并发编程-Memcached (分布式内存对象缓存系统)
一.Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态.数据库驱动网站的 ...
- 基于英特尔® 至强™ 处理器 E5 产品家族的多节点分布式内存系统上的 Caffe* 培训
原文链接 深度神经网络 (DNN) 培训属于计算密集型项目,需要在现代计算平台上花费数日或数周的时间方可完成. 在最近的一篇文章<基于英特尔® 至强™ E5 产品家族的单节点 Caffe 评分和 ...
- 共享内存Distributed Memory 与分布式内存Distributed Memory
我们经常说到的多核处理器,是指一个处理器(CPU)上有多个处理核心(CORE),共享内存多核系统我们可以将CPU想象为一个密封的包,在这个包内有多个互相连接的CORES,每个CORE共享一个主存,所有 ...
- Disque:Redis之父新开源的分布式内存作业队列
Disque是Redis之父Salvatore Sanfilippo新开源的一个分布式内存消息代理.它适应于"Redis作为作业队列"的场景,但采用了一种专用.独立.可扩展且具有容 ...
- Spark入门实战系列--10.分布式内存文件系统Tachyon介绍及安装部署
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Tachyon介绍 1.1 Tachyon简介 随着实时计算的需求日益增多,分布式内存计算 ...
- 高性能分布式内存队列系统beanstalkd(转)
beanstalkd一个高性能.轻量级的分布式内存队列系统,最初设计的目的是想通过后台异步执行耗时的任务来降低高容量Web应用系统的页面访问延迟,支持过有9.5 million用户的Facebook ...
随机推荐
- Maven 专题(四):什么是Maven
1 Maven 简介 Maven 是 Apache 软件基金会组织维护的一款自动化构建工具,专注服务于 Java 平台的项目构建和 依赖管理.Maven 这个单词的本意是:专家,内行.读音是['meɪ ...
- JVM 专题二十二:垃圾回收(六)垃圾回收器 (三)
4. GC日志分析 4.1 日志分析 通过阅读GC日志,我们可以了解Java虚拟机内存分配与回收策略. 内存分配与垃圾回收的参数列表-XX:+PrintGC:输出GC日志.类似-verbose: gc ...
- flask 源码专题(三):请求上下文和应用上下文入栈与出栈
1.请求上下文和应用上下文入栈 # 将ctx入栈,但是内部也将应用上下文入栈 ctx.push() def push(self): # 获取到的 top == ctx top = _request_c ...
- 深度剖析分布式单点登录框架XXL-SSO
于2018年初,在github上创建XXL-SSO项目仓库并提交第一个commit,随之进行系统结构设计,UI选型,交互设计-- 于2018年初,在github上创建XXL-SSO项目仓库并提交第一个 ...
- ASP.NET Core3.1使用Identity Server4建立Authorization Server-2
前言 建立Web Api项目 在同一个解决方案下建立一个Web Api项目IdentityServer4.WebApi,然后修改Web Api的launchSettings.json.参考第一节,当然 ...
- mysql 利用延迟关联优化查询(select * from your_table order by id desc limit 2000000,20)
其实在我们的工作中类似,select * from your_table order by id desc limit 2000000,20会经常遇见,比如在分页中就很常见. 如果我们的sql中出现这 ...
- 使用数据泵(expdp、impdp)迁移数据库流程
转载原文地址为:http://blog.itpub.net/26736162/viewspace-2652256/ 使用数据泵迁移数据库流程 How To Move Or Copy A Databas ...
- PG-跨库操作-dblink
在PostgreSQL数据库之间进行跨库操作的方式 dblink postgres_fdw 本文先说说dblink:dblink是一个支持从数据库会话中连接到其他PostgreSQL数据库的插件.在其 ...
- 七牛云如何绑定二次验证码_虚拟MFA_两步验证_谷歌身份验证器?
一般情况下,点账户名——账户设置——安全设置,即可开通两步验证 具体步骤见链接 七牛云如何绑定二次验证码_虚拟MFA_两步验证_谷歌身份验证器? 二次验证码小程序(官网)对比谷歌身份验证器APP ...
- python 批量重命名文件名字
import os print(os.path) img_name = os.listdir('./img') for index, temp_name in enumerate(img_name): ...